Comparing Analytic Workspaces to GROUPING SETS, CUBE and ROLLUP
I know I said I wouldn't answer any more questions send directly as opposed to via the forum, but this one was too good to pass on.
"Hello, Mark.
I am searching for answers to two puzzling questions about Oracle cubes and am hoping that you wouldn't mind helping me out.
I've searched your Forum and Blog and have not come across anything that addresses these. I saw your email address on the Blog, and so, thought I would take a chance and pose my questions to you directly. I've just begun playing with Oracle's 10g Analytic Workspace Manager and am trying to integrate this technology with Discoverer 10g against a large data warehouse (star schema type).
Question 1:
========I read the docs about Oracle cubes, that they consist of the dimension attributes from my warehouse dimension tables and certain measure columns (either from my fact tables and/or calculated fields). Conceptually, these dimension attributes compose the "edges" of the cube. And the measures are really pre-calculated values found at the point of intersection of these edges within the cube. Selecting from a cube is fast because the calculations were done when the cube was loaded with dimension data. This, then, is my concept of what an Oracle cube is. If I'm mistaken here, please let me know.
All of this, however, sounds to me exactly like a regular table that was created and populated using Oracle's specialized grouping clauses (GROUPING SETS, ROLLUP, CUBE). Using these clauses, I've built tables consisting of various dimension attributes from my warehouse dimension tables along with pre-calculated measures associated with various combinations of these dimension columns. That's how the grouping clauses work. They allow me to create such pre-calulated measures at the "intersection", so-to-speak, of these dimension columns. And selecting from them is fast because Oracle does not need to calculate anything. All the measures have already been calculated when I created the table in the first place. Doesn't all this sound very much like an Oracle cube?
I admit that using the GUI that comes with AWM 10g is easier than manaully writing the SQL that uses these grouping clauses. Still, are Oracle cubes really the same as creating regular Oracle tables using the clauses GROUPING SETS, ROLLUP, CUBE?
Question 2:
========I am trying to figure out what the difference is between a Discoverer OLAP worksheet (uses an Oracle cube) and a Discoverer relational worksheet (uses a regular EUL). I read your excellent article entitled "Drilling from OLAP to Relational using Discoverer 10g". This gave me a few hints as to these differences, but I'm still not sure. Put it this way, I am unable to explain this difference to anyone. I've searched the web, looking for answers but have only come across discussions about the differences between MOLAP versus ROLAP, for example. Such discussions do not really clinch it for me.
Put another way, what can one do with a Discoverer OLAP worksheet that cannot be done with a Discoverer relational worksheet and vice-versa?
And so, would you mind explaining what this difference is or, perhaps, point me to an article that explains this difference. Thank you so much for your help. If this is not the right place to ask such questions, I do apologize. I just took a chance because I could not find these questions answered anywhere."
OK, here's how I'd try and explain it. Note that I'm obviously not from the Oracle OLAP product team so this isn't the official answer, but here's my take on it.
Taking question one first, as you point out both the SQL method and the analytic workspace method allow you to create "cubes" that contain the values for multiple levels of aggregation. With the SQL method, the GROUPING SETS, CUBE and ROLLUP method generate the aggregates on the fly, which you can then either use straight away or store for later use in a materialized view (either using CREATE MATERIALIZED VIEW or via DBMS_ODM if you've licensed the OLAP Option and want to use them with the Java OLAP API). With analytic workspaces, you load data into the lowest level of a measure (usually) and then either aggregate the other levels on the fly, or generate the aggregates and store them along with the base-level data in the measure.
Below the surface though, the two methods use very different techniques to store and then access the cubes. The SQL method, assuming you've stored the results in a materialized view, holds the cube in regular tables and provides access through query rewrite; as you know this can sometimes be problematic and there's a limit to how much you can muck about with your query before rewrite fails and you fall back to having to rollup your cube from scratch again. Analytic Workspaces though store the aggregated data right alongside the base-level data in one big indexed array, there's no rewriting of queries or substitution of table names going on in the background, the OLAP engine is natively aware of the hierarchical structure of its data and it provides access to higher levels in your cube just as fast as the bottom levels through calculating the cell offset from the beginning of the cube's data. There's more flexibility when performing the aggregation as well - the AGGMAP feature in Oracle OLAP gives you full programmatic control over the aggregation process for a cube, similar to the User-Defined Aggregates feature in Oracle 9i and 10g but a lot easier to use and performant.
Once you go beyond the aggregate-awareness feature though, there are a couple of other benefits you get from using a proper multi-dimensional engine. The range of calculations you can perform using OLAP DML goes well beyond the analytic functions in SQL with features such as forecasting, allocation and some high-end statistical features, and probably most importantly, there's a ton of features built-in to deal with large cubes and sparse data sets.
So, to sum up - functionally they do the same thing, but under the covers the technologies are very different. Analytic Workspaces are natively aggregate-aware and store all the hierarchical levels of the cube in one big indexed array, and don't rely on bolted-on features such as query rewrite to access aggregated data. Analytic workspaces come with OLAP DML, a high-end OLAP query language built specifically for multidimensional and statistical analysis, and come with a number of features that are there to deal with situations where your cubes could otherwise get very large because of all the possible dimension level combinations. If you want to do a bit more background reading, this presentation (slide 21) by Dan Vlamis and this Oracle paper by Bud Endress are a good introduction to the technology and benefits, although the latter does do SQL a disservice though by only considering MVs built using regular GROUP BYs rather than GROUP BY ... GROUPING SETS.
The second question is also interesting as I can see where the confusion comes from. Both versions of Discoverer allow you do OLAP-style analysis; Discoverer Plus relational has a crosstab feature that allows you to query data using hierarchies, "dimensions" and page items, whilst Discoverer Plus OLAP only does OLAP-style analysis, but it can do it against both relational and multi-dimensional data (the OLAP Option lets you store data relationally as well as multidimensionally, though most people don't bother with this as it's slower to query, the metadata is fragile and it's more complicated to set up). So what do you really get when you use Discoverer Plus OLAP as opposed to Discoverer Plus relational?
In my view, there are two main benefits in using Discoverer Plus OLAP. The first is that you get to access your data using a logical dimensional model, which instead of presenting data items to users as items inside of folders, presents it to them in terms of a hierarchical model of measures, dimensions, hierarchies, levels and attributes, like this:
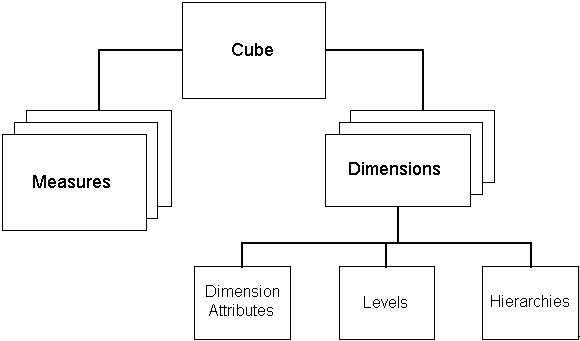
The thinking behind this is that it better reflects the way that end-users picture their business or organisation. For example, if you're a sales manager and you're looking to improve sales (a measure) over the next twelve months (time, a dimension), you need to consider the customers you sell to (another dimension), the products you sell (another one), the areas you sell in (another) and the promotions you're offering (another one). Your customers can be grouped by their income bands (an attribute of the customer), their propensity to defect (another attribute) and their time as a customer (and another), whilst the products can be of a certain type, colour, price band and price elasticity. The point here is that Discoverer for OLAP, and the OLAP cubes you've got stored in either analytic workspaces or relational tables with OLAP Option metadata placed over them, is naturally organised in this querying and business-centric manner which naturally provides some meaning to the data and guides the user when trying to answer their business question. When you come to use the two tools then, this dimensional view of data is reflected in the Workbook Wizard:
To take an example, imagine you are doing some sales analysis and you're using Discoverer relational. When you come to make your data item selection, either all of the items you want are all together in a custom folder, with no real indication as to the hierarchical relationship between them, like this:
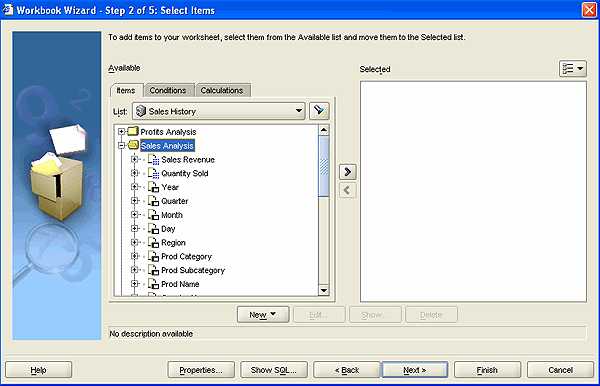
or they're arranged into folders, again all looking the same and with no way of telling, from looking at them, which are the dimensions and which are the measures:
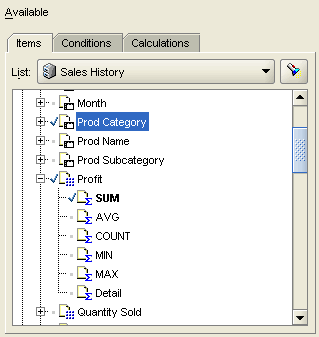
Then, if you go on and try and do some analytical-style reporting, even though the latest 10g release of Discoverer shields you from the SQL to some degree, you're still going to be faced with something like this:
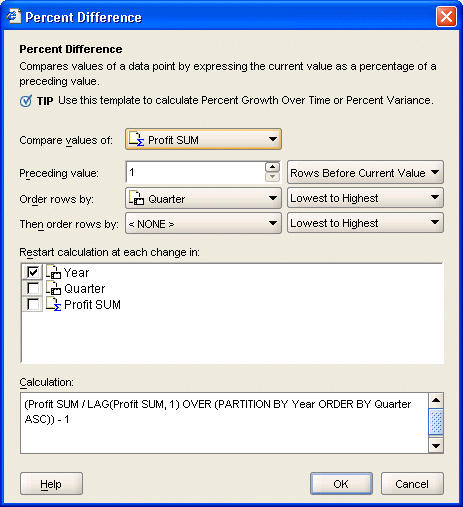
which is probably going to scare off a lot of business users.
Contrast this then with Discoverer Plus OLAP, which presents your data items to you in a dimensional, hierarchical way:
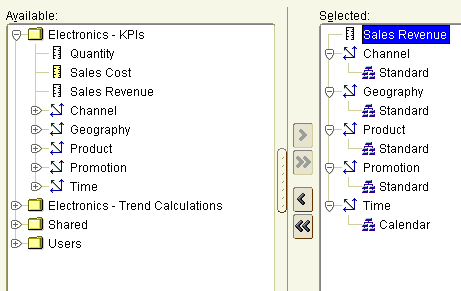
Then, when you come to make selections, create conditions and so on, you do it in terms of dimension members, who have attributes such as age band, size, colour and gender, and who are arranged into hierarchies and aggregation levels, like this:
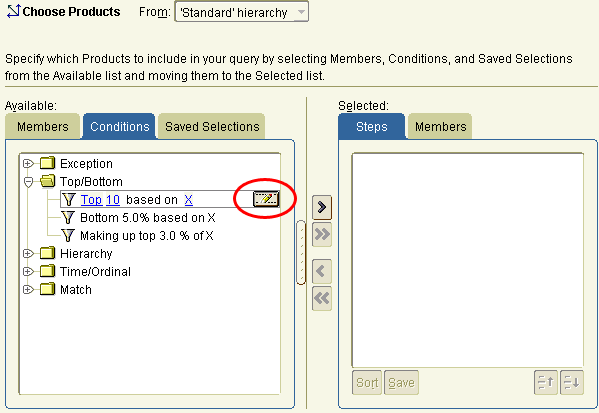
Then, when you come to do your analytical calculations, you do it through an OLAP-aware calculation builder, rather than a wizard over complex analytical SQL.
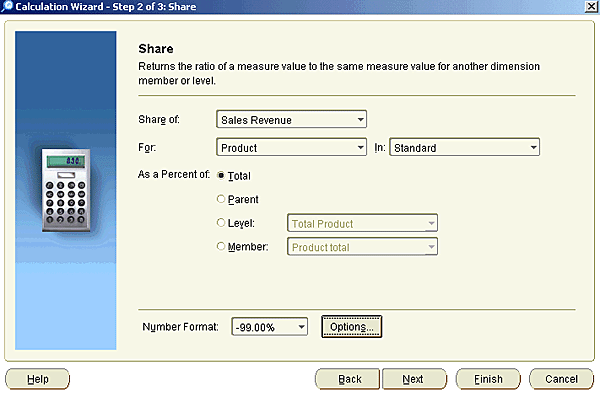
Now this isn't to say that Discoverer Plus OLAP should therefore always be used when you want to perform crosstab-style analysis; the logical dimensional model that it uses places restrictions on how you can analyze your data, so that for example you can't total up by an attribute. There are also some limitations in the way that Oracle have currently implemented Discoverer Plus OLAP so that, as the product currently stands, you can't access the forecasting or allocation features of your analytic workspace (or at least you can't create or maintain forecasts, you can view the results of ones that have already been created) with the same going for custom members, custom aggregates and models. If you're looking to do straightforward OLAP analysis of a cube of data though, and your target audience is business or end-users rather than SQL programmers, it's worth taking a look at Discoverer for OLAP.
Another benefit should be performance. In theory, it should be fast for users to access and query data held in a pre-summarised analytic workspace as opposed to a relational star schema supplemented by materialized views. I say "in theory" as it depends on how much aggregation is needed, how fast the interface between Discoverer Plus OLAP, the OLAP API and the analytic workspace performs (with versions of Oracle up to 10gR1 the interface was a bit slow) and how well your materialized view using GROUP BY ... GROUPING SETS performs. I haven't done any comparative tests myself and the only figures that exist are in Bud Endress' paper, which only compares analytic workspaces with regular materialized views, and so on this you'd have to do some tests on your own particular dataset. I suspect there won't be much in it.
Anyway, that's my answer for now. If you're interested in reading more, I wrote about this in a bit more detail in a paper I did for the UKOUG Conference last year; if anyone else has done any comparative tests regarding performance and rollup times, drop me a line as I'd be interested in hearing other people's experiences.