Using Oracle Real-Time Decisions to Automate Business Decisions
As well as being useful for call center applications where cross-selling offers have to be generated, Oracle Real-Time Decisions can also be used in general business situations where a decision has to be made, but you don't have perfect knowledge of all the factors. For example, you might want to make a decision about whether to refund a customer's bank charges, and your general business goals might be to maximize revenue and minimize customer attrition, but you don't really know what effect either refunding, or not refunding, a charge might have. If you can build up a model of what customers do when you do, or don't refund a charge, and the circumstances around the refund request, then it's conceivable that you could start to learn after a while when you should and when you shouldn't give the customer their money back.
Or take, for example, a situation where you have a number of competing delivery companies that can deliver an order to a customer. On the face of it, they're all pretty much the same - each one claims it'll get the delivery to the customer on time - and whilst they charge different amounts for their service, keeping our costs to a minimum isn't always the most important thing, if we're looking to build customer loyalty as well.
So, we're in a situation where every company claims to do the same thing, but you know that in reality some will perform better than others in different situations. How do you make a decision on which delivery company to use then, when you've got competing business goals, a bunch of suppliers that perform differently in different situations, and you've got to make a decision when you don't have perfect knowledge of all the factors?
This is where a tool like Real-Time Decisions comes in. Using Real-Time Decisions, we can set up a process that receives the order details, takes into account the context of the order (the day of week for example), factors in, for example, the fact that you want to in general offer better service to premium customers, and the builds up a model that records what actually happens, correlates this with the details of the order, and gradually builds up an model that can predict, given your business goals and the context, what the best delivery firm would be for a particular order.
So how do we set up Real-Time Decisions (RTD) to put this all in place? The first step is to start up Oracle RTD Studio, define a new Inline Service, and create an "entity" to hold the details of the order.
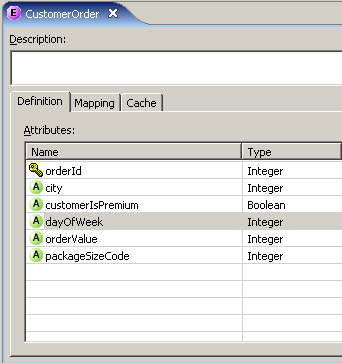
This entity will allow RTD to consider the city that the order is being delivered to, whether the customer is a premium customer or not (so that we can treat them slightly differently), what day of week the order is placed, the value of the order and the size of the package, in case these factors turn out to influence the outcome of the delivery. When a decision needs to be made, the calling application will contact RTD, pass across the order ID and these bits of information, and they'll then be persisted in RTD until the decision process is complete.
The next thing we need to do is to create some inputs into the RTD decision process. These inputs are called "informants" and we create one for the start of each individual decision process, for when we pass across the details of the order, and for when the decision process completes. We also create another one, which we've called "Supplier Feedback", that we let us pass feedback into the decision so we can tell whether the decision we made turned out to be the right one - this feedback loop is key to how RTD works and allows us to create a "self-learning model" that gets more accurate the more decisions it makes and feedback it receives.
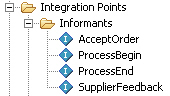
Each one of these informants has input parameters, which in the case of the start and end informants is just the order ID, but in the case of the one that receives details of the order, consists of the list of order details that gets passed through from the calling application.
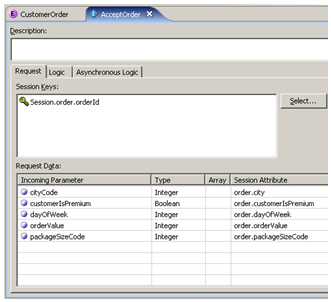
Each of these input variables is tied back to the session variables set up when the decision process started, so that's available later on when a choice needs to be made.
Now that we've got some inputs into the decision process, it's time to start setting out the choices that can be made. First of all is the list of delivery companies we can choose from, which we enumerate in the application under the heading of a "choice group".

Each of these choices can have attributes assigned to them, such as an ID code, a description and so on.
We then do the same for the days of week, the size of packages and the cities we deliver to, with all of these choices and options being enumerated in the application so that we can assign outcomes and probabilities to them later on.

UPDATE : You don't actually have to define choices and choice groups for these input variables, you only really need this for the things the decision is going to choose from - in statistical terms, the "dependent variables". As long as the package size, city and so on are in the session variable, RTD will be able to correlate them to the choice that's selected, so you don't even need the choice models that I mentioned just below. - MR
Now, as we're looking to create a self-learning model that detects correlations between, say, the day of week and whether a certain delivery company actually delivers on time, we need to create a way of storing for a particular order what day the deliver was booked on, what size of parcel it was and so on. To do this we create a number of "Choice Models" that are used to record what city was delivered to, what day of the week the order happened, anything that we feel might influence the outcome of the delivery.
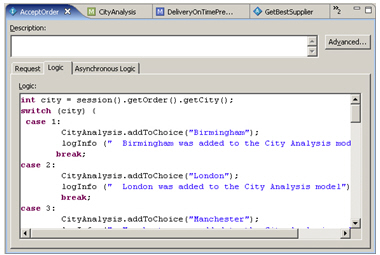
To set up the mechanism where these models are populated with data, we add a bit of Java code to the informant that receives the customer order details, using a CASE statement to add the relevant choice to the model.
Now that we've got some inputs into the decision process, and a way of recording the details of each order, it's time to think about the decision we're going to take, which is what delivery company to use for a particular order. Now the decision we're going to take its going to depend on a number of factors;
- whether the customer is "premium" or not - if they are, we probably want to get them their order a bit faster
- the price each delivery company charges
- the reliability of each delivery firm based on whether it deliverers "first time"
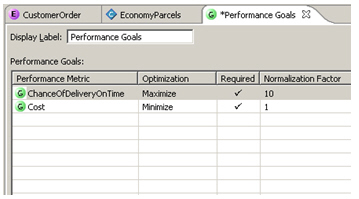
Leaving aside the issue of premium customers for the moment, the price and reliability factors can be boiled down to a couple of performance goals
- cost, which we will want to minimize, and
- chance of delivering on time, which we want to maximize
So the next step then is to put these performance goals into the model - later on, we'll assign priorities to these, which we can vary for different segments of customers.
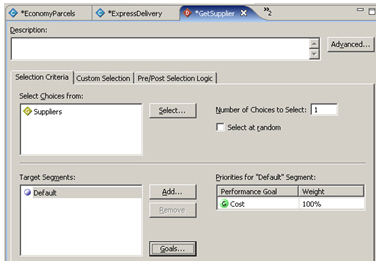
Now we've got some performance goals, we can score each of the suppliers against them. The cost of each service we can add now, the chance of delivery we'll add later once we add functionality to predict it into the model.

Now that we've defined this decision, we can create an "Advisor", an output from the decision process that takes a decision and sends it back to the calling application.
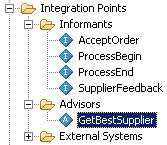
As well as using the decision we just defined, we also define a random decision as well, which we'll use every so often to see whether the models we're building up are actually improving the accuracy of the decision.
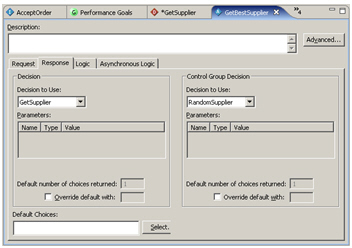
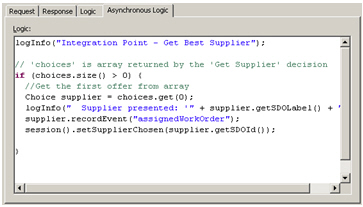
So that we can record what decision was actually made for this order, which we can tie back to the factors that defined the order, we add another bit of Java logic, this time to the Advisor, to record the decision.
So, so far, we're at the point where we've achieved the following:
- Details of an order come in, we record which city it's to, the day of the week and so on
- We've got a set of delivery firms, and a set of performance goals, which at the moment is just to minimize the cost of the delivery
- We've scored the delivery firms against this goal, and
- Set up a decision that chooses a delivery firm based on this goal.
In real-life though, price isn't the only factor that'll we'll base our choice of delivery firm on though. We also want to consider how likely it is they'll get the delivery to the customer on time, something that depends on the choice of delivery company, where they are delivering to, how big the parcel is and so on. Some firms may deliver well to Manchester and not to London, some firms might be overwhelmed at the start of the week but deliver on time towards the end. Others may handle big parcels worse than small ones, all of which leads to a situation where it's pretty hard to judge in advance which delivery firm is most likely to deliver on time. Where RTD comes in though is that we can set up another type of model, called a "Choice Event Model", that records events against a choice, in this case a delivery company, and over time correlates deliveries placed, and deliveries that are then on time, with the order factors we recorded earlier - parcel size, day of week and city.
Now, for each delivery we make, we'll record whether the delivery happened first time, or whether the customer needed to contact the delivery firm and arrange delivery for a second or third time. Crucially, we'll record this feedback on the delivery and use it to "learn" which delivery company actually delivers well based on the city, day of week and size of the parcel.
To do this, I go back to the application and define the new Choice Event Model This new type of model takes two events that I assign to suppliers, "Assigned Work Order" and "Delivered On Time", and records these bits of information for each delivery that takes place.
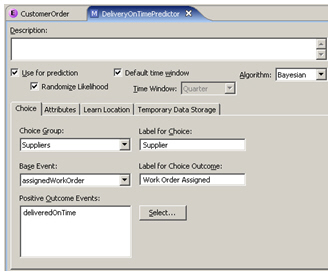
In case you've not already guessed, this is where the "data mining" part of RTD comes in. For this Choice Event Model, I tell RTD to use it for prediction, so that it starts to correlate successful and unsuccessful deliveries with the city, package size and day of week that the order takes place, and I add another Informant, this time to feed back to the Choice Event Model whether the order actually arrived on time.
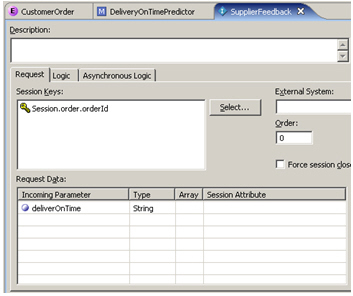
Again, I add a bit of Java logic to add the feedback to this new model.
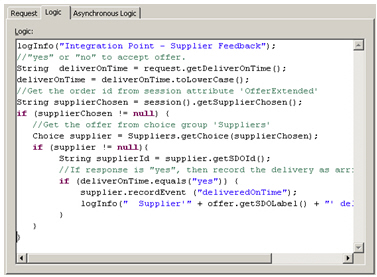
Now I can go back to the performance goal scores for each supplier, and tell it to calculate each one's reliability score based on the DeliveryOnTime Choice Event Model I created earlier.
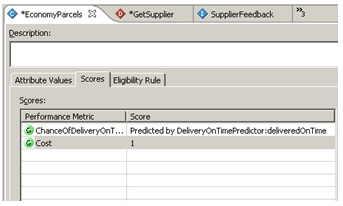
So now my model has two performance goals; one is static and is based on the price each charges, another evolves over time as we get actual feedback from each delivery on whether the delivery actually reached the customer on time. All that's left now is to go back to the decision I created earlier and include this new performance goal in the decision. For standard customers, I'll give equal weight to cost reduction and reliability maximization.
<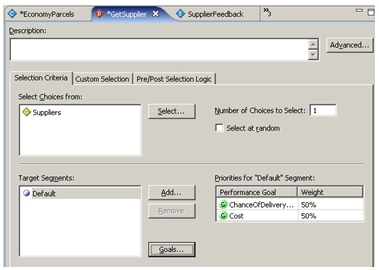
For our premium customers though, I'll create another segment where cost reduction is downplayed and chance of delivering on time in emphasized.
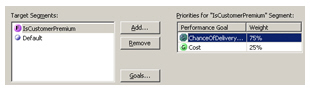
So now we're ready to go. RTD comes with a load generator that lets you define a script that passes values to the RTD decision process, where you can weight the input variables so that, for example, only 20% of customers are premium and 70% of deliveries happen on time. Running this load generator gives us some basic information to add to the model.
Although the values going into the decision process are random, after a while we'll start to get some skew which will mean certain choices get made more than others, and we'll start to get a bit of correlation between input variables and delivery outcomes. To check this out, I start up a web-based console called RTD Decision Center to see how decisions have played out so far.
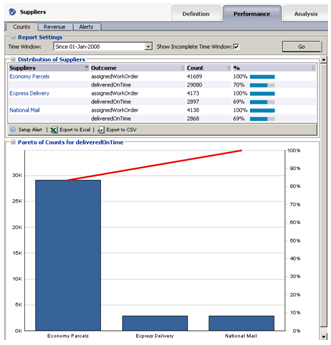
Taking a look at the distribution of orders, we can see that most have gone to Economy Parcels, who just happen to charge the least for delivering. As the load generator script has assigned a 70% chance of delivering on time to all suppliers, one delivering more reliably than another hasn't had a chance to impact the decision, but if, for example, Express Delivery turned out to deliver more reliably than all the others, it would end up getting selected more and more times.
Using Decision Center I can take a look at which order attributes were most significant for the outcome we're trying to predict - delivery on time - so that over time, we can start to understand that the day of the week and the city are the two things that most determine whether a particular company would deliver on time, so that in future, if we have that particular day and need to deliver to that particular city, we'll know which supplier is most likely to help us meet our business goals.
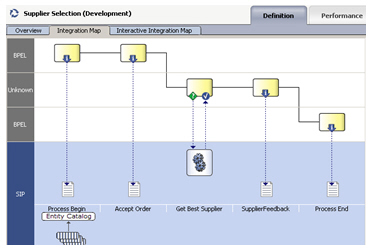
So there you go, we've used RTD and it's self-learning predictive models to work out, based on the history of previous deliveries against a wide range of different scenarios, which delivery firm to use in a particular situation. I wouldn't say I'm an expert at this - part of the skill in setting this sort of thing up is to work out how much information, or "rules" to feed in to the model and how much you should let it work things out itself, part of it is working out what we should be trying to predict in the first place - but it's certainly an interesting technology and a good example of BI becoming "pervasive" and helping business decision making.