Adding New Facts and Dimensions to the BI Apps Data Warehouse
I've been working with Informatica 8.1.1, the Oracle BI Applications and the DAC (Data Warehouse Administration) for a while now, and over this time I've tried to post a few techniques I've picked up whilst putting the tools through their paces. I'm going to round up the current set of postings now with one on how you add completely new facts and dimensions to the BI Apps data warehouse; this is particularly pertinent as the BI Apps data warehouse only really covers a small proportion of the modules available with Oracle E-Business Suite and therefore it's inevitable that you're going to want to add data from modules such as Projects into the warehouse. What's good about the Oracle BI Applications is that there's a published methodology for doing just that, and if you follow it you can customize your warehouse and still be supported by Oracle.
To take an example, I'm working with the Sales - Order Lines subject area in the BI Applications 7.9.5 with my data being sourced from Oracle e-Business Suite 11.5.10. As well as the standard dimensions of product, customer, time and so on together with my standard Sales Order Lines and Sales Invoice lines fact tables, I now want to add a new fact table called Sales Returns which I'll be analyzing by Product, and by a new dimension called Return Reasons.
The other day I talked about customizing existing mappings through the use of a "placeholder" column, X_CUSTOM, that marked a spot in each warehouse table where you could safely start adding new columns. Mappings too have an X_CUSTOM placeholder and if you find the route this placeholder takes through the mapping, this marks a "safe path" through the mapping that you can thread your new columns through too. Whereas for customizations of this type you can take existing Source-Dependent Extract (SDE) and Source-Independent Load (SIL) mappings, copy them to a "custom" table and then amend them as needed, if you're going to add new facts and dimensions to your warehouse you need to create SDE and SIL mappings from scratch.
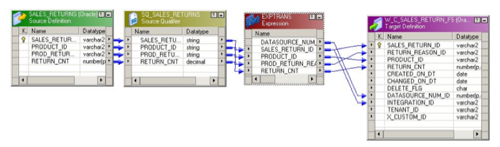
To take my example, I need to load a dimension called Return Reason with data from my E-Business Suite database. To do this I start off by creating a new mapping called SDE_C_ORA_ReturnReasonDimension and add my source table to the mapping together with what's called a "Source Qualifier" transformation. In the screenshot below, the yellow mapping object is the source qualifier and in it's simplest form, it's a SELET list of all the columns for a particular table and it's this, rather than the source itself, that you extract from. The source qualifier lets you customize the SELECT statement so that you can add a filter or otherwise modify the source data before it's processed.
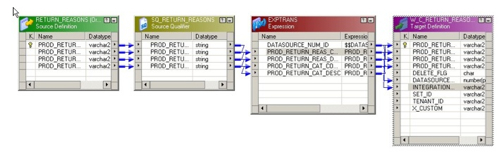
Next to the source qualifier in the mapping is another transformation, this time an "Expression" transformation. If you're used to Oracle Warehouse Builder this is more or less the same, but if you notice in the top row of the transformation is a column (or "port" in Informatica terms) called DATASOURCE_NUM_ID. This column is then assigned to a variable called $DATASOURCE_NUM_ID that's give a value by the DAC when the mapping is called. DATASOURCE_NUM_ID is one of a number of standard columns that you'll find in all OBI Apps mappings and it's one of two mandatory columns, the other being INTEGRATION_ID, the business key, that's required for OBI Apps staging tables.
The Source-Independent Load that takes data from this staging table and loads it into the Return Reason dimension looks in this case fairly similar to the SDE mapping. You'll notice the source at the start (which is the staging table, which happened to be the target in the previous mapping) together with its source qualifier, but then next to it is an example of a transformation, a lookup in this case, that can be shared amongst other mappings in the same way as pluggable mappings and public transformations in OWB. In fact they're better than their OWB equivalents as they're not just restricted to PL/SQL (as transformations are) and they update themselves in mappings whenever the transformation itself is edited (which isn't the case with OWB pluggable mappings). In this case, the transformation retrieves the ID of the current ETL run which is then inserted, along with the ROW_WID (the standard name for a fact or dimension primary key column), the INTEGRATION_ID and the DATASOURCE_NUM_ID into the dimension table.
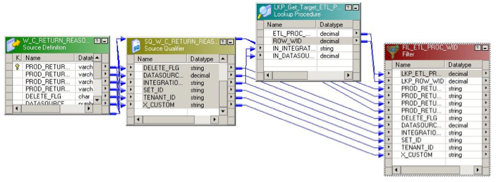
This lookup transformation is another example of the added value you get with the OBI Applications, in that Oracle (or more precisely Siebel, or Informatica before them) have pre-written a number of standard ETL components that you can drop onto your mappings to, for example, make sure you don't add a source row twice if you've had to restart an ETL process. These are things you inevitably end up writing yourself if you're putting an OWB project together, in this case though they're written for you and the standard way of constructing OBI Apps ETL processes is to use these bits of reusable ETL code.
Once you've picked up the ETL process ID and filtered out any rows that have already been processed for that ETL run ID, there's another step where you work out whether the row is either a new one (and therefore needs to be INSERTed into the dimension table) or an existing one (which therefore needs to be UPDATEd).
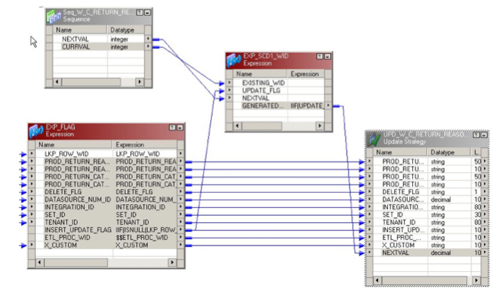
Then once you've loaded what's called the "Update Strategy" transformation you then use this to insert or update into the actual dimension table.
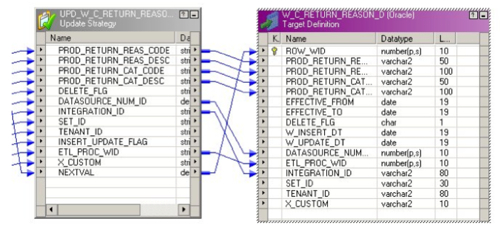
Now this is one area I think where Informatica is weaker than OWB. In OWB, loading a table is very simple as you just map the source columns to the target, select either insert, update, insert/update, delete or whatever as the load strategy, and then the data just goes in the table. For facts and dimensions it's even cooler as OWB takes care of lookup up the surrogate keys and loads these into the fact table, wheareas Informatica makes you do all this yourself. For inserting and updating regular tables though, you have to go through these Update Strategy transformations which to me don't seem to add anything beyond what OWB does but instead does the same thing in a more convoluted manner. That said though, one thing I will say for Informatica is that the "fit and finish" of the product is way beyond OWB - as it's a Windows application rather than Java, it's much snappier, more stable and doesn't suck all the memory out of your machine as you're doing your work. Coming from a background of teaching OWB and having to get students used to the regular crashes, reboots and so on that are a standard feature of OWB, using Informatica over the last month has been quite an eye-opener.
Loading data into the fact table, at least from the SDE (extraction) side, is very similar to the dimension table. The SDE mapping takes data from the source table, adds the DATASOURCE_NUM_ID and stores it along with the INTEGRATION_ID in the fact staging table.
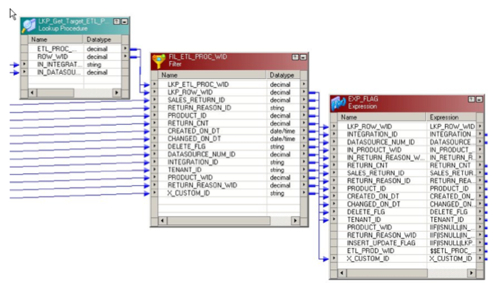
Loading from the fact staging table into the fact table itself is a bit more complex. First off you need to add both the fact staging table, and the two dimension tables to the mapping as sources, then you join them using a single source qualifier transformation. Now the source qualifier transformation to me is one of the major flaws in Informatica; what you use it for is to bring together one or more source tables into a single mapping object which you then use as the source for the rest of your mapping. In a way it's like an OWB joiner transformation, and in fact the joiner transformations you get in Informatica are actually there for joining data from different data sources, as the source qualifier transformation only allows joins across a single source system.
So far so good, but the flaw for me in this transformation is that it's backed up by an SQL statement, that you can edit and in most cases does get edited so that you can fine-tune the join condition, add custom columns in and so on. The problem is that this SQL statement has in my experience been responsible for around 90% of all mapping errors, as the column list in the SQL has to exactly match the column list in the mapping, it's easy to introduce typos, it's not that obvious if the join condition is wrong and so on.
Contrast this with OWB, where you just create input and output groups in a joiner transformation, then drag source columns in to it and just use an SQL expression editor to set the join condition. I've had far less errors occur with OWB's way of doing things and I just can't see why Informatica have provided a transformation type with so much scope for human error.
Anyway, once you've got your source transformation working you can work through the rest of the fact load, again using reusable transformations to retrieve the ETL run ID, get the next surrogate key and so on. Going back to the OWB vs. Informatica subject again, one thing that I found very good about Informatica is that you've got more or less complete freedom to construct your ETL process in any way you want, you don' t have to worry about whether it'd make sense as an SQL SELECT statement or whatever.
Now of course this doesn't necessarily lead to the most performant of mappings (I couldn't help noticing that every load took absolutely ages when moving data into the BI Apps data warehouse, but then again I was loading from E-Business Suite) but as a developer it's a pretty exciting environment with a total absence of strange database error messages when you try and do anything complex. In fact this detachment from the underlying database was in some circumstances pretty good - unlike OWB where every move of the mouse seems to trigger a database transaction, Informatica only interacts with the database when you save mappings, for example, to the repository - although I can't help thinking that on big data warehouse loads, where you've got an experience OWB and database perform creating the mappings, OWB is going to beat Informatica's row-based approach through its use of set-based SQL. Still, it's nice to be able to access data from a web service, say, without having to use some mind-bendingly complex internal Oracle database feature and I think Informatica have got a nice balance between developer productivity and leverage of the database, especially in the current release where certain ETL functions can be shipped back to the underlying database, in the same way that the BI Server function-ships calculations back to the underlying database.
The other thing I've kept thinking when working with Informatica is, on the one hand, how much it's like OWB, and on the other, how much it's not like Oracle Data Integrator, which is slated as being the ETL tool that will replace Informatica once Oracle get around to migrating all the mappings. ODI is strictly set-based and it's mappings are very simple - just join a number of source tables, perform calculations en-route and load it into a target table, none of these fancy reusable transformations and so on that Informatica uses so widely. Unless Oracle replace all of this advanced ETL functionality with new ODI Knowledge Modules, I'm not quite sure how they'll make the transition, but then again I'm no wiser than anyone else how this process is going and I guess we'll hear more at Open World. For the time being though, that's it for me on the BI Applications; I'm hoping to get the new Essbase 11 tools up and running over the weekend and then I'm starting work on some examples for the DW Seminar I'm running for Oracle in Denmark early in September.