Using a PARTITION BY JOIN to Fill In The Gaps
As a quick introduction, I'm Stewart Bryson, Technical Director for North America. It seems strange to be posting an entry on this blog after so many years of reading it, and learning from it. The momentum it has in the community is something I do not take lightly, so hopefully, this post and others from me will find a receptive audience.
Recently, I had a design decision to make with some ETL code I was writing for a client. The fact table I was loading was at a transactional grain, recording activity of particular business processes, and storing the cumulative amount of time for certain tasks. The source and target tables were reasonably complicated, so for simplicity sake, I’ll use the PROMOTIONS table in the SH schema (an optional sample schema installed by the DBCA) to demonstrate my method.
desc sh.promotions Name Null? Type ----------------------------- -------- -------------------- PROMO_ID NOT NULL NUMBER(6) PROMO_NAME NOT NULL VARCHAR2(30) PROMO_SUBCATEGORY NOT NULL VARCHAR2(30) PROMO_SUBCATEGORY_ID NOT NULL NUMBER PROMO_CATEGORY NOT NULL VARCHAR2(30) PROMO_CATEGORY_ID NOT NULL NUMBER PROMO_COST NOT NULL NUMBER(10,2) PROMO_BEGIN_DATE NOT NULL DATE PROMO_END_DATE NOT NULL DATE PROMO_TOTAL NOT NULL VARCHAR2(15) PROMO_TOTAL_ID NOT NULL NUMBERFor simplicity sake, I’ll be loading a very simple fact table without surrogate keys and only a simple measure: DURATION_DAYS.
desc dim.promotions_fact Name Null? Type ----------------------------- -------- -------------------- PROMO_ID NUMBER(6) PROMO_NAME VARCHAR2(30) PROMO_SUBCATEGORY VARCHAR2(30) PROMO_BEGIN_DATE DATE PROMO_END_DATE DATE DURATION_DAYS NUMBERNow ordinarily, finding the difference between two dates is easy in Oracle… it’s simple subtraction. We could easily load this fact table with the following statement:
INSERT INTO dim.promotions_fact
SELECT promo_id,
promo_name,
promo_subcategory,
promo_begin_date,
promo_end_date,
promo_end_date-promo_begin_date
FROM sh.promotions;
503 rows created.
select promo_begin_date,
promo_end_date,
duration_days
from dim.promotions_fact
where promo_id=108;
PROMO_BEGIN_DATE | PROMO_END_DATE | DURATION_DAYS
---------------------- | ---------------------- | -------------
12/23/2000 12:00:00 AM | 01/23/2001 12:00:00 AM | 31
1 row selected.
Problem solved, right? Well, maybe not. What if one of the requirements for the DURATION_DAYS measure was to exclude weekends? My client had a process for calculating these values in the OLTP reporting database using some cursor-based PL/SQL code that was terribly inefficient, doing multiple table lookups for every single row processed. I concluded that I should be able to do this with set-based processing and a single join. All I really need is a table that is loaded with a row for every day in the year, and also distinguishes weekdays from non-weekdays. Does that sound like any table we know?
Sure, it’s the DATE dimension table… or what some models refer to as the TIME or PERIOD dimension. We have such a table in the SH schema, called TIMES, and it’s likely that you have such a dimension table as well. I hadn’t looked at the TIMES table in a while, and I was hoping it also had an attribute distinguishing holidays from non-holidays. Since it doesn’t, I’ll remove that requirement from my list, but just keep in mind: if your date dimension table also has a holiday flag column, you could eliminate holidays from the calculation as well.
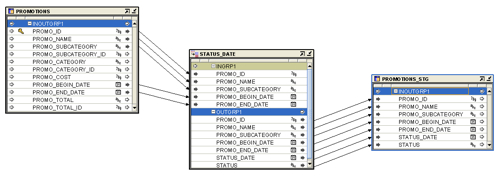
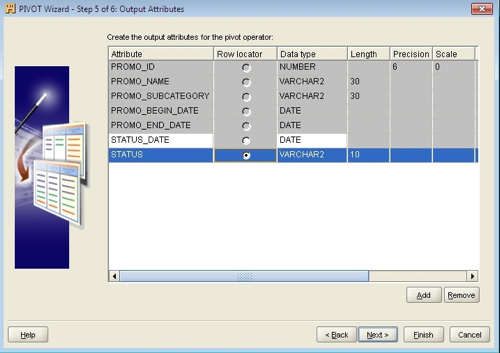
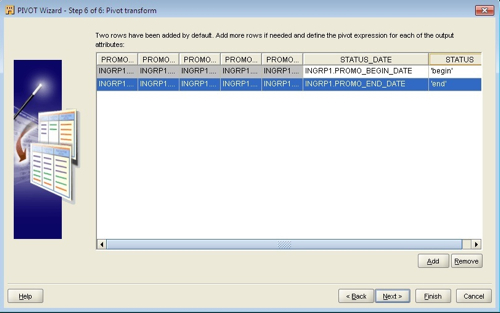
First, I’ll need a single date column to use to join in the TIMES table, but currently, I have two date columns: PROMO_BEGIN_DATE and PROMO_END_DATE. Sounds like I need to pivot those two dates into a single one called STATUS_DATE. I did this using the following Warehouse Builder mapping to load a staging table called PROMOTIONS_STG:
select promo_id, status_date, status from stage.promotions_stg where promo_id=108;
| PROMO_ID | STATUS_DATE | STATUS |
|---|
108 | 12/23/2000 12:00:00 AM | begin
108 | 01/23/2001 12:00:00 AM | end
2 rows selected.
Now my idea is to join in the TIMES table to this staging table using an outer join so the TIMES table will effectively fill in the gaps between start dates and end dates, and then I can use a simple COUNT aggregate to calculate DURATION_DAYS. But there is only one problem with this solution… a simple outer join will only fill in the missing days once FOR THE ENTIRE ROW SET, while I need the rows filled in ONCE FOR EACH PROMO_ID.
The Oracle database offers an extension to the ANSI join syntax called the PARTITION BY JOIN. I can use the the PARTITION BY syntax, just as I would with an analytic function, to “partition” or “divide up” the rows in my staging table according to the PROMO_ID. This allows me to use a single join to the TIMES table, which actually acts as if I were performing multiple joins; one for each PROMO_ID.
Warehouse Builder does not support the PARTITION BY JOIN syntax… which is a real shame. However, I can create a view to perform this logic, and then use the view as a source in my Warehouse Builder mapping:
CREATE OR REPLACE VIEW stage.promotions_vw
AS
SELECT promo_id,
promo_name,
promo_subcategory,
promo_begin_date,
promo_end_date,
time_id status_date,
status,
weekday_flag
FROM ( SELECT time_id,
CASE
WHEN day_name IN ('Saturday','Sunday') THEN 'N'
ELSE 'Y'
END weekday_flag,
promo_id,
MAX(promo_name) OVER (partition BY promo_id) promo_name,
MAX(promo_subcategory) OVER (partition BY promo_id) promo_subcategory,
MAX(promo_begin_date) OVER (partition BY promo_id) promo_begin_date,
MAX(promo_end_date) OVER (partition BY promo_id) promo_end_date,
nvl(status, 'ongoing') status
FROM stage.promotions_stg partition BY (promo_id)
right outer JOIN sh.times
ON time_id=status_date)
WHERE time_id BETWEEN promo_begin_date AND promo_end_date
/
View created.
select status_date,
status,
weekday_flag
from stage.promotions_vw
where promo_id=108
order by status_date;
STATUS_DATE | STATUS | W
---------------------- | ---------- | -
12/23/2000 12:00:00 AM | begin | N
12/24/2000 12:00:00 AM | ongoing | N
12/25/2000 12:00:00 AM | ongoing | Y
12/26/2000 12:00:00 AM | ongoing | Y
12/27/2000 12:00:00 AM | ongoing | Y
12/28/2000 12:00:00 AM | ongoing | Y
12/29/2000 12:00:00 AM | ongoing | Y
12/30/2000 12:00:00 AM | ongoing | N
12/31/2000 12:00:00 AM | ongoing | N
01/01/2001 12:00:00 AM | ongoing | Y
01/02/2001 12:00:00 AM | ongoing | Y
01/03/2001 12:00:00 AM | ongoing | Y
01/04/2001 12:00:00 AM | ongoing | Y
01/05/2001 12:00:00 AM | ongoing | Y
01/06/2001 12:00:00 AM | ongoing | N
01/07/2001 12:00:00 AM | ongoing | N
01/08/2001 12:00:00 AM | ongoing | Y
01/09/2001 12:00:00 AM | ongoing | Y
01/10/2001 12:00:00 AM | ongoing | Y
01/11/2001 12:00:00 AM | ongoing | Y
01/12/2001 12:00:00 AM | ongoing | Y
01/13/2001 12:00:00 AM | ongoing | N
01/14/2001 12:00:00 AM | ongoing | N
01/15/2001 12:00:00 AM | ongoing | Y
01/16/2001 12:00:00 AM | ongoing | Y
01/17/2001 12:00:00 AM | ongoing | Y
01/18/2001 12:00:00 AM | ongoing | Y
01/19/2001 12:00:00 AM | ongoing | Y
01/20/2001 12:00:00 AM | ongoing | N
01/21/2001 12:00:00 AM | ongoing | N
01/22/2001 12:00:00 AM | ongoing | Y
01/23/2001 12:00:00 AM | end | Y
32 rows selected.
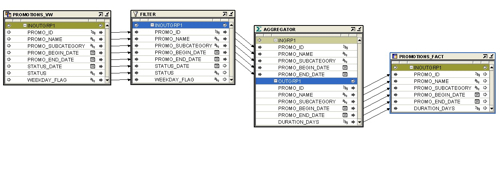
Now I can use this view as a source in a Warehouse Builder mapping, and load the fact table using an aggregate function:
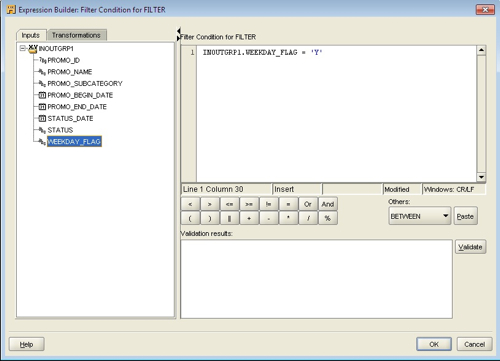
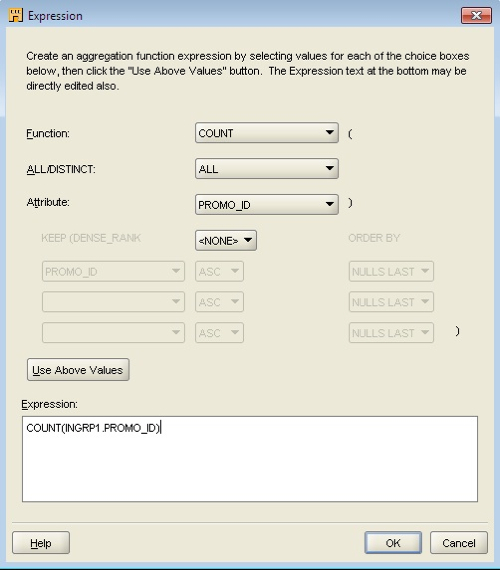
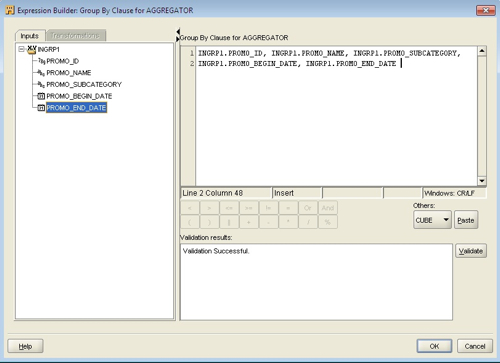
select promo_begin_date,
promo_end_date,
duration_days
from dim.promotions_fact
where promo_id=108;
| PROMO_BEGIN_DATE | PROMO_END_DATE | DURATION_DAYS |
|---|---|---|
| 12/23/2000 12:00:00 AM | 01/23/2001 12:00:00 AM | 22 |
1 row selected.
If OWB supported the PARTITION BY JOIN syntax, the entire process could be done in a single mapping. Because it doesn't, I was forced to to first write to a staging table, and then use a view on top of that table to fill in the PARTITION BY JOIN logic.