In the past couple of postings (here, here), I've gone through an introduction to the new BI Apps 7.9.5.2 release and talked about how the introduction of ODI has altered much of the technology underneath it. In today's posting I'll go through how data is loaded into the BI Apps data warehouse, and how you can use the various tools to diagnose why a load has failed (something that happens quite a lot when you first install the product).
The first step in performing a load is to start up the Configuration Manager and define the execution plan. If you've used the previous releases of the BI Apps that use Informatica and the DAC, you'll know that you can either run one of the predefined execution plans or you can define your own, using a list of subject areas that you select. In 7.9.5.2, the Configuration Manager doesn't provide you with any predefined execution plans and so you need to use the tool to create your own. You start off by creating a connection through to the Oracle database that contains the metadata tables used by the Configuration Manager (these are a much smaller set of tables than used by the DAC, as details of the execution plans etc are actually held in the ODI Work Repository).
Once you've created this first connection you can save it, so that you can just select it from a list next time you log in. Once you've logged in, you are presented with a list of options, to manage connections, manage parameters, edit, run and then monitor execution plans.
"Manage connections" allows you to define the connection through to the ODI workflow agent, and to the schema that holds the Configuration Manager tables. This is optional but saves you having to retype it all every time you submit an execution plan for running.
You can also edit the parameters used that are global (are independent of specific ETL runs), common (apply to all subject areas) or application specific (specific to a particular module, such as Financials Analytics). I leave these as the default, I also haven't updated or amended any of the domain values CSV files that ship with the BI Apps as I'm running against a subset of the Vision EBS database and don't really know/care about the specific codes used in this database.
Now it's time to define the execution plan. I click on the Administer Execution Plans link and start selecting the subject areas. These map to the license options for the product and are restricted to the modules that this release supports (see this posting for more details). I select Backlogs, Booking Line, Cycle Lines and Invoice lines from the Order Management module.
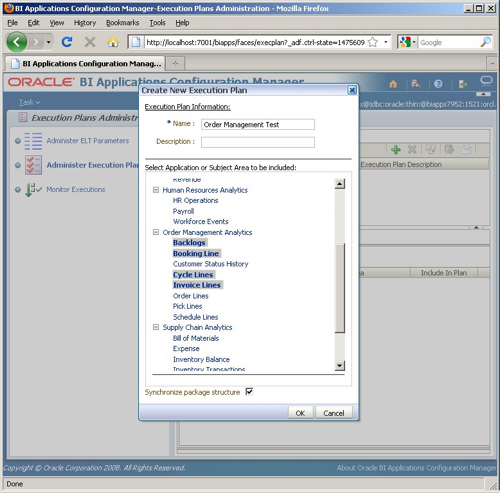
There's an option at the bottom of the select list to "Synchronize package structure", which you can also do when saving the execution plan. What this step actually does is a bit unclear; looking at the docs, it says:
"In order for the package structures to be displayed correctly on the Package Structure tab, the subject areas associated to an execution plan must be synchronized within internal Oracle BI Applications Configuration Manager tables. If you do not synchronize the package structures when creating the execution plan or when you made changes to the subject areas associated to the execution plan, you must synchronize by clicking the Synchronize package structure button that appears on the Package Structure tab in order to get correct package structure. The synchronization process may take up to several minutes depending on the network traffic between the Oracle Business Analytics Warehouse database and the Oracle BI Applications Configuration Manager installation."
The schema used by the Configuration Manager only actually has one table though, and what it appears to contain is a list of "transactions" associated with the Configuration Manager, like this:
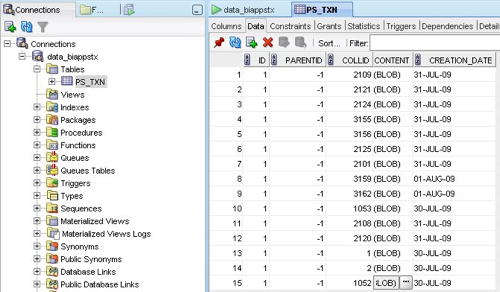
If you view the contents of the BLOB as an XML file, each one contains something a bit different and, I think, is storing details of parameter changes, setting up of execution plans and so on. Here's a look at the entry that was created just after I defined the above execution plan:
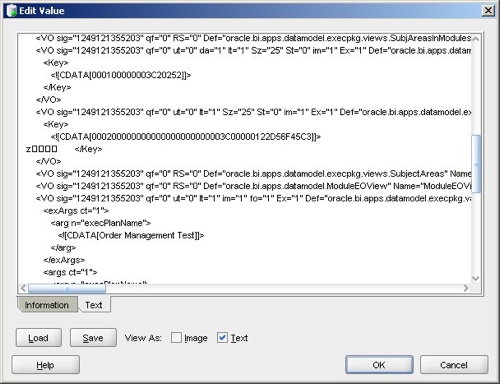
You can see the name of my execution plan mentioned in the XML, so I guess (a) this table stores details of the execution plans, parameter values and so on as you create them, and the synchronization step takes what's in these tables and copies it across to the ODI Work Repository.
Once you've created the execution plan, you can view its structure in the Configuration Manager application.
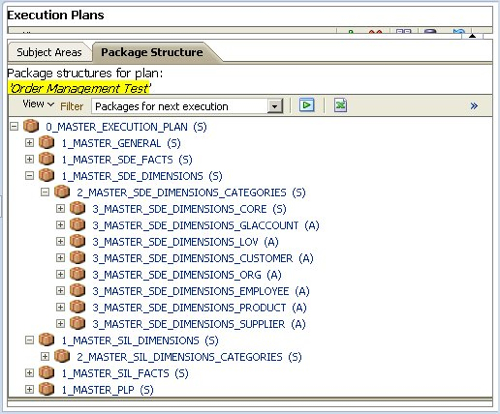
Notice how the execution plan package is structured; there is a "Master Execution Plan" at the top, which then has "Master General", "Master SDE Facts", Master SDE Dimensions" and so on. Within each of these are packages for the various dimension categories, and these then go down to the individual mappings that you'll need to run. If you saw my previous article on how ODI holds execution plans you'll have seen that these packages and mappings translate to packages and interfaces in the Project View in ODI Designer, like this:
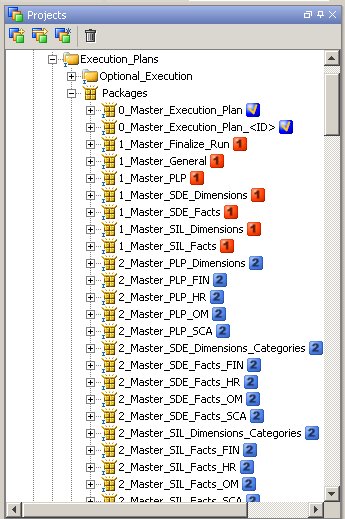
The numbers next to the packages indicates the ETL phase for the package, the complete list of which looks like this:
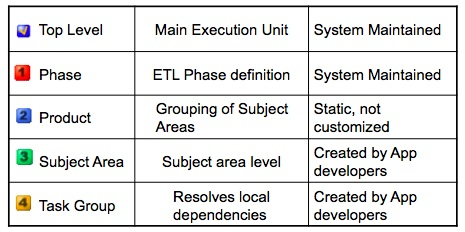
So how about we try and run the execution plan. To do this, you can either start it from the ODI Designer application (you can use this to schedule execution plans as well), or you can run it on-demand from the Configuration Manager. I run it from the configuration manager and enter the details for the ODI super user (SUPERVISOR).
After the execution plan is started, you can switch between the Monitor Executions view in the Configuration Manager and the Operator ODI application to see how the plan develops.
Things start off with some general routines to create indexes, truncate staging tables, refresh the execution plan and so on.
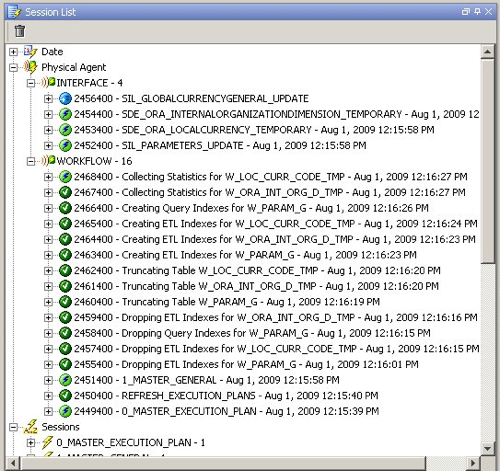
Taking a look at the execution plan status in the Configuration Manager, all looks OK at this stage.
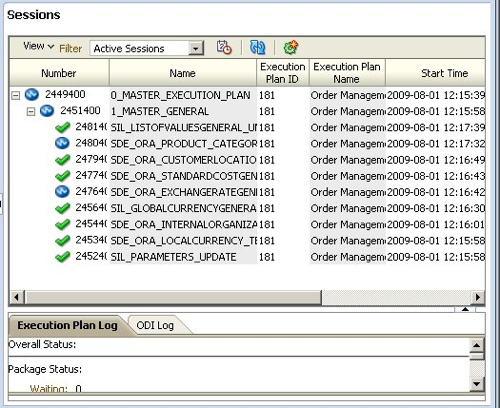
Going back to the Operator, you can see the Workflow agent kicking off Interface agent jobs to load the individual dimensions, at this point using the SDE mappings.
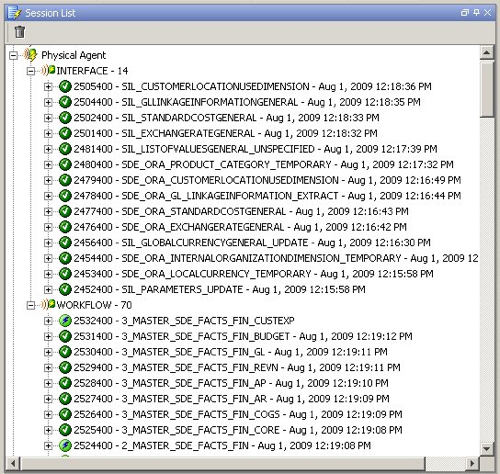
The view from the Configuration Manager still looks good, as well.
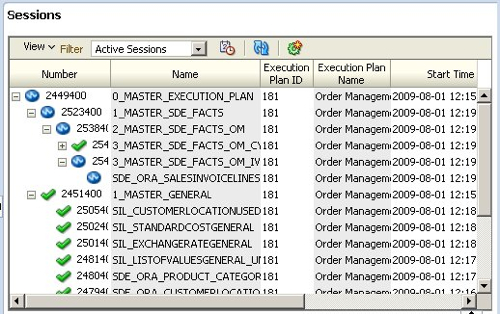
About five minutes later though, I notice that the load has ground to a halt. Taking a look in the Operator, I can see that one of the mappings has failed.
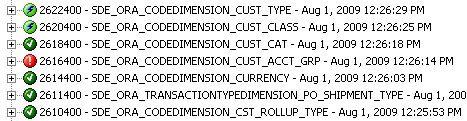
The Configuration Manager also shows an error, but also shows the log which indicates that the mapping has failed due to a table being missing.
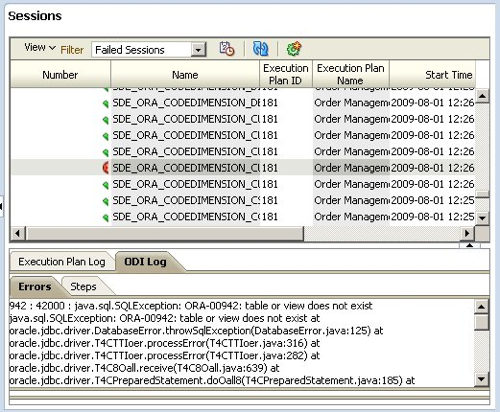
I half-expected this as the dataset I've got is a stripped-down version of the Vision dataset, originally designed to be demo'd with the 7.9.5 version of the BI Apps. Even for point releases such as 7.9.5.2 some of the mappings change though and require additional tables that aren't in my dataset.
So which table is missing? To find out, I go back to the Operator and have a look at the SQL that this step was trying to execute.
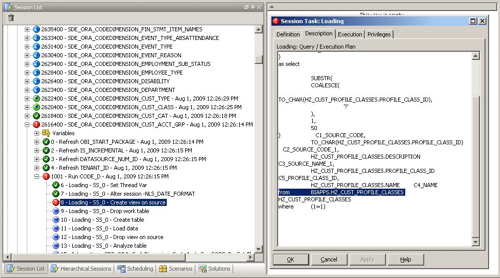
So the step that failed was one that was trying to create a view over one of the tables in the EBS schema, and for whatever reason this table doesn't exist.
Now as the ODI Model View contains the definition of all the tables that are expected as sources for the mappings, to get around the problem I use the ODI Designer to generate the DDL for this table and then apply it to the EBS source schema. Then, as you could do with the DAC, I go back to the Configuration Manager and restart the execution plan. As the mappings in the ODI repository are designed to be restartable, after a minute or so I go back to the Operator and check the progress again.
A few minutes later, the execution plan stops again, and looking at the Operator I can see that the Workflow agent has failed this time, whilst trying to create an index.
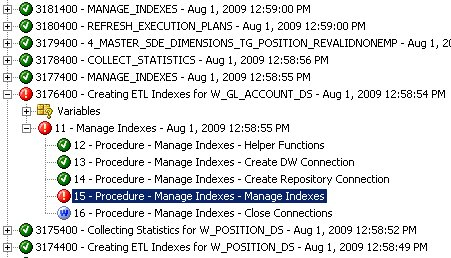
Looking at the error message associated with the step, I can see that a unique index has failed to create because the table has duplicate values in the indexed column.
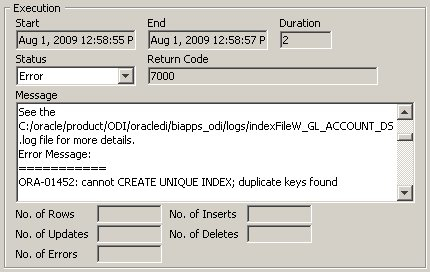
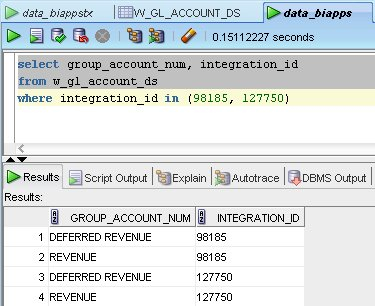
For some reason the W_GL_ACCOUNT_DS dimension staging table has got duplicate values in the DATASOURCE_NUM_ID, INTEGRATION_ID and the source effective from column, which is strange as this indicates a problem with the source data (there are duplicates in the source EBS table). To start working out what's gone wrong, I first run a query on the W_GL_ACCOUNT_DS table to find out which INTEGRATION_IDs are duplicates.
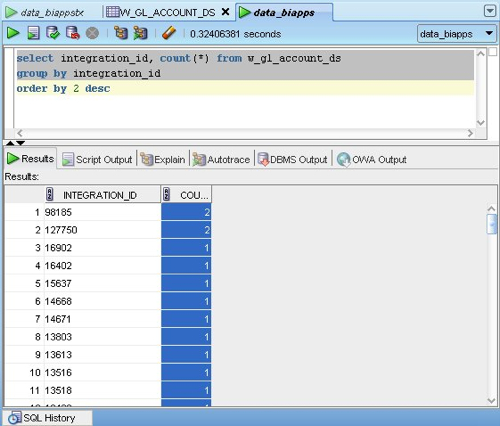
Sure enough, there are two that are duplicated. Now even if I've run this mapping a few times we shouldn't get duplicates as the table is truncated each time that the mapping is run, so there must be duplicates in the EBS table that provides the source. So which source table populates this mapping?
Now with the old DAC you could have taken this table name, viewed it in the DAC Console Design view and then displayed which tasks had this table as a target. This is a bit trickier in 7.9.5.2 as there's no UI for querying the relationship between tables and mappings, so I instead go back up the list of completed mapping steps and find the package that called this index creation step; I then look up the steps and see the view that's created to provide information for the table load.
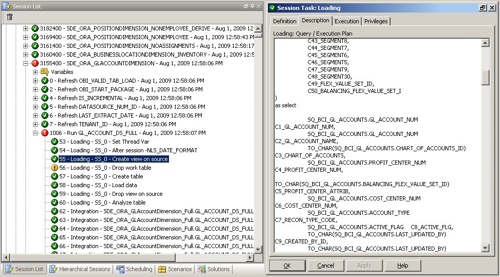
So the view is created over an SQ_BCI_ table, which is something that the Source Qualifier interfaces that I mentioned in my previous posting creates to mimic the mapplet and source qualifier transformations that Informatica uses. Going back to the Designer application, I can see that the mapping to load the W_GL_ACCOUNT_DS table consists of a package that calls two incremental load interfaces and two full load interfaces. The ones in yellow are the "source qualifier" interfaces that retrieve the data from EBS, the other two are the interfaces that load the warehouse staging table.
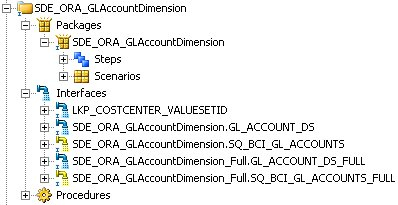
Taking a look at the full load interfaces, I first look at the interface that loads the W_GL_ACCOUNT_DS table to see where the INTEGRATION_ID column is populated from.
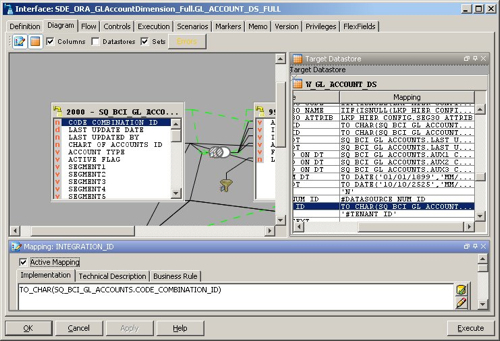
So INTEGRATION_ID is populated from the CODE_COMBINATION_ID from the SQ_BCI_ interface. So where does this interface get the CODE_COMBINATION column from?
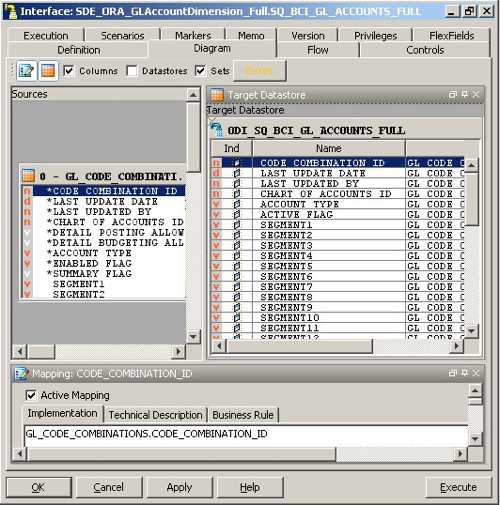
So it comes from the GL_CODE_COMBINATIONS.CODE_COMBINATION_ID table. Now it's a case of running a query against that table, and maybe I'll find a duplicate, or it could be that there are no duplicates but the SQ_BCI_ interface creates some because of the join that takes place in order to load the table. However looking at the data that's been loaded into the table, it actually looks like it's valid but I need to include another key value in the integration ID so that it becomes unique.
The task now is to resolve this issue and then work through any similar issues until the load completes without error, a task that in my experience usually takes up to a week to complete (meaning that including the install, working out these data issues and then getting the RPD set up, I usually budget for two weeks to get the first numbers up in front of the client) for initial evaluation.
If all else fails and you can't get a mapping to run, but you want to mark it as completed and run the rest of the mappings in the execution plan, in theory you can set the status of the session to "Done" from "Error". This should then allow the rest of the process to complete as if the erroneous step completed correctly (although your data of course may not now be consistent), however when testing this I found that even though I could mark the session as "done" and other steps then started running, this step later on got marked as "error" again later so I don't think it works in quite the same way as the equivalent feature in the DAC Console.
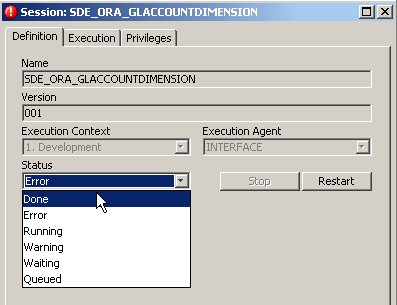
If nothing is working, you can mark the whole load as having completed or even reset (truncate) the warehouse tables in order to start again.
So there you go. As with the versions of the BI Apps that used Informatica, your first load will probably take a couple of attempts to go through and you need to know how to diagnose errors, restart the load and monitor progress in order to complete the task. The process is a bit different to using the DAC and Informatica but if anything, the mappings are a bit simpler as all of the SCD2 handling, ETL_PROC_WID applying and so on is done through the various knowledge modules. In the final posting on this topic later in the week, I'll be completing things by talking about customizations, and how they work in this new version.