Real-time BI: An Introduction
Discussing real-time data warehousing is difficult because the meaning of real-time is dependent on context. A CIO of an organization that has weekly batch refresh processes might view an up-to-the-day dashboard as real-time, while another organization that already has daily refresh cycles might be looking for something closer to up-to-the-hour. In truth, an interval will always exist between the occurrence of a measurable event and our ability to process that event as a reportable fact. In other words, there will always be some degree of latency between the source-system record of an event happening, and our ability to report that it happened.
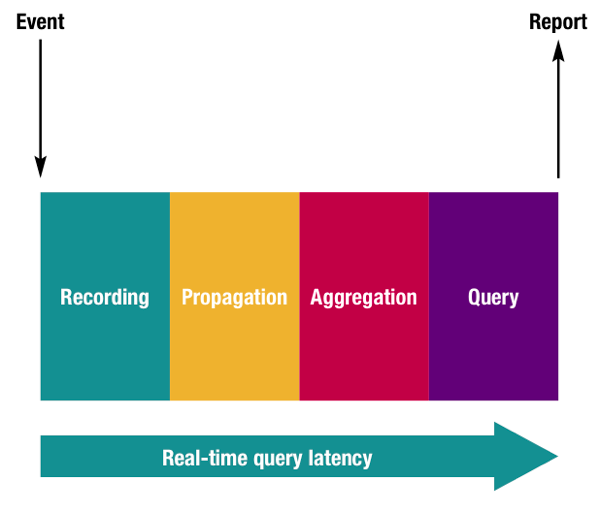
For the purposes of this series of blog posts, I’m defining real-time as anything that pushes the envelope on the standard daily batch load window. We will explore some of the architectural options available in the standard Oracle BI stack (Oracle Database plus Oracle Business Intelligence) for the removal of the latency inherent in this well-established paradigm.
I've categorized 4 basic types of DW/BI systems as they relate to real-time BI.
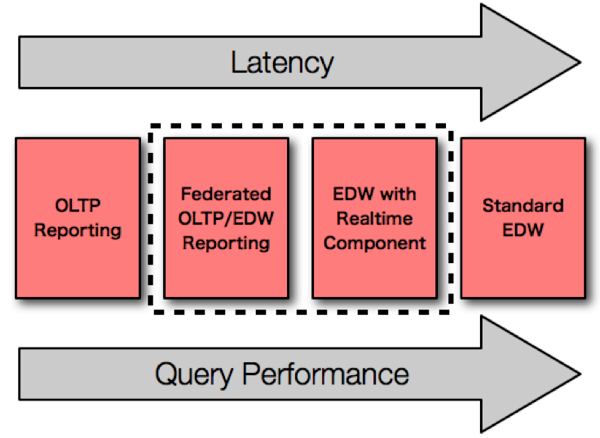
Our solution with the least amount of latency, but also with the worst performance, is simple reporting against the OLTP database. Our next approach, with more latency but better performance, is a federated approach, using a BI tool such as OBIEE to “combine” results from the data warehouse with fresh data from the OLTP source system schema. In this scenario, we have a typical data warehouse, loading in daily batch cycle, but we layer in fresh data from the source for intra-day records. We improve upon query performance by using an optimized data warehouse for the majority of our data, with gains for real-time reporting by including the non-tranformed data directly from the source system schema. Our next approach is using a traditional data warehouse that has been optimized to store the results of micro-batch loads. In this scenario, instead of running the batch load process once every 24 hours, we instead run it several times a day, usually between one and ten times an hour. We extend the standard data warehouse architecture to have a real-time component, which means, we modify our fact tables, our dimension tables, and the ETL processes that run them to better handle the micro-batch processing. Finally, last on the list in terms of latency, but our best choice for pure performance, is the traditional, batch-loaded data warehouse.
As the image above suggests, I'm most interested in the two squares in the middle, as I think they are the only ones that qualify as both "real-time" and "BI". In the series of blog posts to follow, I'll be talking about these two solutions, how they compare to each other, and what are some of the keys in determining "readiness" for delivering them. Before moving on, however, I need to make a pitch for the Oracle Next-Generation Reference DW Architecture, which Mark first spoke about here.
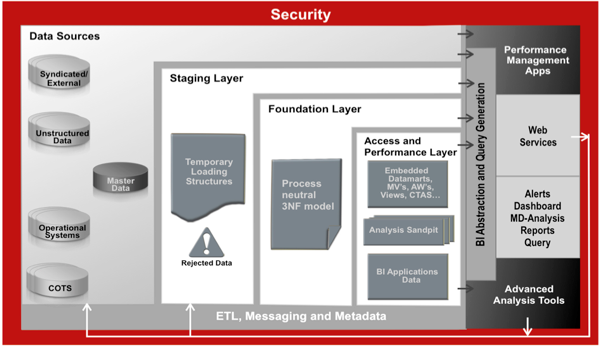
Regardless of which of the two solutions that we opt for, we should implement the staging, foundation and performance layers as the best overall approach to building and sustaining business intelligence. For example... even if we should to use our source system schema to address some portion of our reporting requirements, we should still stream, or "GoldenGate," our data from the actual live transactional system to the database where we do our reporting. But I'm not arguing in favor of simply having another "reporting" copy of our source system: I'm advocating that we use change data capture strategies to populate a foundation layer where we maintain a complete history of all the source system changes. Only then are we fully insulated against any change in user behavior and the possible change in reporting requirements that follows.
Be on the lookup for the first follow-up to this, where I will explain the EDW with Federated OLTP Data choice, and demonstrate how to achieve this using OBIEE 11g.