How Does RTD Make Decisions?
In the last RTD posting, I used an example of product recommendations on a website to explain how an RTD solution could look, here’s the diagram again as a reminder:
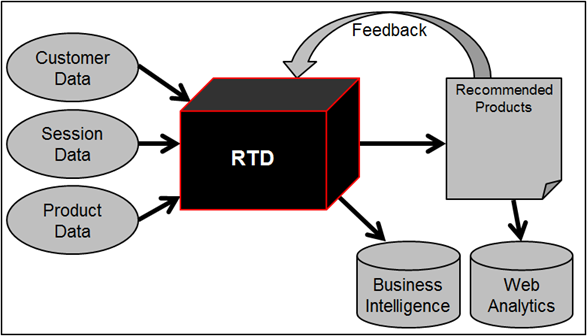
Using the same example, I’m going to provide a simplistic explanation of what’s happening inside the black box that is RTD. There’s more happening in the box than explained here, but hopefully you’ll get an idea of how the solution works.
Let’s say we have four products available a DVD, Book, CD and Video Game. Obviously, in reality we may have thousands of different products that will come under different product categories and sub-categories.
A customer visits our website and gets to the point of requiring a product recommendation. RTD could first check availability of stock, as there is no point recommending products that are not available for purchase (yes, I appreciate you might want to allow people to pre-order for when available, but as I said this is a simple example!). In this case, the video game is out of stock, leaving RTD to make a decision from the remaining three products.
When RTD is first switched on, it needs to learn before it can make recommendations. In this example, we are going to have three bits of data, the customer’s age, day of the week and customer’s country of residence. In the example, there are also a limited number of values for each field. Day of the week, for instance, can only be Monday or Friday (should have been Saturday and Sunday if I’m going to make it a two day week!). So the first customer from the UK, comes to the site on Friday and is 18 years old. This customer purchases the DVD, so as you can see from the diagram below, these customer attributes are stored against the DVD.
The next diagram below shows the second customer, aged 30 from America, visits the site on Friday and purchases the CD. Again, you can see that the attribute values for the second customer are stored against the CD.
Customer number three then purchases the CD, with their attributes being stored appropriately as shown in the pic below:
So I guess you get idea by now. So after 50 customers, of which 15 have purchased the DVD, 15 the book and 20 the CD, the attribute values against each product look as follows:
Now RTD has sufficient learning, when the next customer comes to the website it can predict the product they are interested in. It does this by scoring the customer’s likelihood to purchase each product. So when the 51st customer, who is 50 and from the UK, visits the website on Monday, they get the following likelihood to purchase scores:
As you can see from the above the product with the highest likelihood of purchase for this customer on this day is the book. As well as returning this recommendation to the website, RTD continually learns and hence will self-adjust to changes in customer behaviour. RTD scores each product or choice, and hence from a front end display point of view you could show the highest ranked product or the top ten in purchase likelihood order.
When new products or new customer attributes are added, RTD will automatically start learning on these and recommending as appropriate.
Hopefully, this has given you some idea of how RTD works. In my next post, we’ll take a look at RTD components and hardware requirements.