What's New in Oracle Endeca Information Discovery v2.4

As I am new to the Rittman Mead blog, I would first like to say hello. I am Farnaz and I have been working with Oracle Endeca Information Discovery (OEID) having joined Rittman Mead last year. As part of my experience with OEID I have just completed an Endeca project, focussing on complaints, with a large financial services organisation in UK.
Oracle Endeca Information Discovery v2.4 was released on 1st February this year and not publicly announced by Oracle due to the fact that a newer version is coming soon. I have now had a chance to install this version and play around with it. Here are my very initial observations of the release:
In the same way as older versions of OEID, this software is downloadable via Oracle e-Delivery website which is the Oracle Software Delivery Cloud where you can find downloads for all licensed Oracle products.
The first thing I noticed when downloading the new version was the change in the way different parts of OEID parts have been distributed in different packages and their titles, for example:
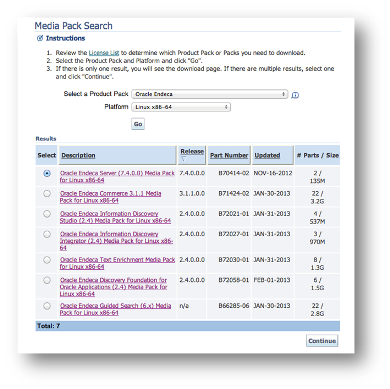
- A new package called “Oracle Endeca Information Discovery Foundation for Oracle Application version 2.4 Media Pack” has been created which contains:
- Oracle Endeca Server version 7.4
- OEID Integrator version 2.4
- OEID Studio version 2.4
- Oracle Endeca Content Acquisition System version 3.0.2
For more information about different parts of software, please refer to the previous series of Rittman Mead blogs.
- A new “Oracle Endeca Information Discovery Integrator (2.4) Media Pack” contains:
- OEID Integrator (Server and Designer both in one zip file)
- Oracle Endeca Content Acquisition system (CAS)
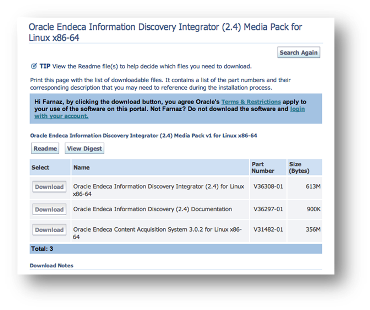
The Text Enrichment component installation files are not part of the Integrator package.
Also, I personally was expecting to see the Tomcat server files required for installing the Integrator Server in this package, as a part of installations users should download it separately from the Tomcat website.
The most impressive change in the new version I can see is the new Oracle Endeca Text Enrichment functionality to support Portuguese, German, Spanish, and French languages. Since the most powerful and the unique future of Oracle Endeca Information Discovery is to provide text analysis next to traditional reports.
The installation files include language data directories, which provide text analysis capabilities for different language contents. These include a custom part-of-speech tagger, entity extraction, model-based sentiment, theme and stemming patterns appropriate for each of the different language content.
There is another positive move forward in text enrichment capabilities around optimisation for social media data. At Rittman Mead where various demos on reading and analysing Social Media feeds with Endeca have been built, we know how important it is nowadays for organisations to analysis their unstructured data coming from different social media feeds such as Twitter, Facebook, LinkedIn and etc. OEID has proved to be one of the best tools to do this job so far and it seems that it is getting even better.
This installation file adds a Twitter data directory and is aimed at providing custom handling of short-form content. Some tasks for extracting value from social data can be done with other feed providers like DataSift or even each media’s own API.
Finishing the installation and starting to work with the new Integrator, The first change I noticed was in Clover ETL project structure where additional new directories have been added such as Job-Flow and Profile:
- CloverETL Jobflow module provides the functionality for combining ETL graphs together with other activities into complex processes providing orchestration, conditional job execution, and error handling.
- ProfilerProbe calculates metrics of the data that is coming through its first input port. Developers can choose which metrics they want to apply on each field of the input metadata.
Also there are a number of new components in Clover ETL palette:
- Readers (JSONReader, XMLExtract, XMLReader, XMLXPATH Reader) - JSON files (Java Script Object Notation) is a lightweight human-readable data interchange format serving as an alternative to XML, which is commonly used for feeds coming from different social media. So it can be another step towards social media analytics. After all being able to read from more sources is an excellent capability.
- Writers (JavaBeanWriter, JavaMapWriter)
- Job Control (Fail, GetJobInput, SetJobOutout, Success)
- Data Quality (Address Doctor, EmailFilter, ProfileProbe) - In the older versions it was not possible to check the quality of data coming from different sources and passing through different components of a graph in Integrator Designer. The task used to be assigned to the source systems. Sometimes data developers need to combine data from different data sources within Integrator Designer or make dramatic changes to the flow of data, proving the need for a data quality system.
A new ability to connect to OBI Server functionality from Integrator designer, which basically allows Integrator to fetch data from an OBI Server using Oracle JDBC driver to create a project with all meta-data files, connection, sql statements and graphs required to read data from an OBI Server. I will discuss this in more detail in a future blog post.
Those who have created pages and reports in v2.3 Oracle Endeca Studio probably have seen bugs placing components in pages and page layouts or components losing their preferences after a change in control panel. In the new version most of the changes in Studio have been around solving such issues within dashboards. For more information you can find a list of solved bugs in Studio v2.4 ReadMe text file.
Full product documentation is not part of e-delivery packages. However it is accessible on this link (http://www.oracle.com/technetwork/middleware/endeca/documentation/index.html).
Look out for my next post covering the OBI Server connection functionality.