MDS XML versus MUDE Part 4: Simple Multi-Branch Development
After getting our MDS XML repository ready for development in the last post, I am ready to demonstrate what multi-user development without MUDE would look like using Git as our version control system (VCS). Let me apologize for the slightly different username and directory structure in these samples versus the last few posts... I built a new OBIEE 11.1.1.7.1 environment recently and migrated all my samples and demo work there. Now, just a little bit about Git, and why I chose it. Git was initially developed by Linus Torvalds, the original developer of Linux and specifically the Linux kernel. As the mythology tells us... Torvalds was dissappointed with all the VCS systems currently available, and doubted any of them could keep up with the distributed, multi-user development requirements from the thousands contributing to the Linux kernel concurrently. So the Linux community set about developing their own utility. Thus, Git was born.
The strength of Git lies in it's branching and merging model. Although we can do branching and merging in a VCS such as Subversion, or even in the Admin Tool using MUDE or the standard three-way merge, these are really just cheats: there is no inherent branching functionality in Subversion or in the Admin Tool. Instead, they use controlled merge processes (that's all that MUDE is: a controlled merge process) even when one branch is a direct decedent of the other, and the differences could only be one way. For instance, in Subversion, we use a special directory called "branches" to facilitate this feature.
Git is different. Branching and the metadata that supports it is built into the tool, and it's easy to create new branches, switch branches, etc. It's the flexible branching model that allows us to isolate the development process from the conflict resolution process. If you recall from my exposition of MUDE, the lack of this isolation is a deal-breaker: simply publishing changes back to the master repository should never cause the developer to handle conflicts. In larger development organizations (actually... any organization where the other developer isn't sitting right beside you) this scenario is not only difficult... it's ridicules.
In looking at a sample Git branching workflow, depicted in the diagram below, notice the master branch, the develop branch, and the multiple feature branches:
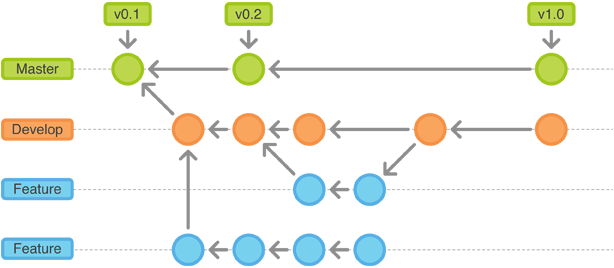
A feature branch is any individual branch that a developer works on in isolation. This feature branch could be called anything, and depending on the project management and delivery methodology, could look like any of the following: "branch1", "project2", "new-feature-101", "jira-ticket-206"... or, for less complicated environments, simply "stewart-bryson". Because the feature branch is isolated to a single developer, that developer is never confronted with a "conflict resolution" screen. Developers just develop... period. The develop branch could be a release, such as "release101" or commonly "v101". Or, for OBIEE environments, this could be focused around a particular subject area, a particular business model, etc. However... the main point about the develop branch is that it is used to integrate feature branches together prior to being merged back into master. So this is how a release can be packaged up to include certain features, but not everything currently active in the development stream. Once a develop branch is unit tested, it can be merged into the master branch for regression testing, and then tagged as a release.
To get started with the Git multi-user development, we start by "checking out" (to use a Subversion term) a Git repository. In Git, we do this with the git clone command. The reason it's a clone, and not a checkout, lies in Git's distributed nature. When working locally on a Mac, Windows machine, or even Linux desktop, we have a complete cloned copy of the repository, which we interact with during development, and then "publish" back to the origin repository. This allows us to commit our work locally (and often) without having to publish changes back to the server. Following the repository clone, we'll create two features branches locally, called "feature1" and "feature2", and then "push" (or publish) them to the remote server to make them available for everyone:

Using the process described in the last post, we add an MDS XML repository in the local Git repository that we just cloned:

Once we have our MDS XML repository checked in, we're ready to develop using the two new feature branches. My point here is to demonstrate what multi-user development looks like using branches. So we need our first developer... let's call him Mark Rittman just for kicks. Suppose that Mark Rittman is just another developer on our project (I know... like asking Albert Einstein to put gas in the DeLorean) and is going to work individually on the feature1 branch. The first thing he does is checkout branch feature1, merge in the changes from the master branch (to make sure he has the most recent changes, including the new MDS XML repository), and get ready to do some repository development:

Notice the "fast forward" merge that occurred? Git has several different strategies it can use when merging branches, with the easiest being the "fast forward" merge. We'll discuss that more in just a bit. So now, with the feature1 branch up-to-date with master, Mark will do some simple RPD development. First, he duplicates the connection pool to isolate the queries from initialization blocks (because Mark's a smart guy). Secondly, he adds a missing attribute to the Dim - Staff dimension: Staff DOB. Mark's development process is represented below, along with the source control message from the Admin Tool (after choosing Save) alerting him to new and modified XML files in the MDS XML directory:


So the Admin Tool has taken Mark most of the way... but it won't commit for him. So he goes to the command line again, and issues the git commit required to get the feature1 branch committed locally, and also the git push required to "publish" the branch back to the server:

Let's assume that Jon Mead is now working to add other features to the RPD, so he'll be developing against a different branch. Jon checks out the feature2 branch, and merges in the most recent changes from the master branch. Notice again that Jon gets the "fast forward" merge strategy... I promise to explain that soon.

Now that feature2 is up to date with master, Jon starts working on his new feature: he adds a few new measures to the fact table. Below we see a representation of his development with red annotation; we also see the two blue annotation boxes to draw attention to what's not there: notice that switching branches completely isolates streams of development as we would expect; none of the changes Mark made are present. Following the development, we can see Jon commit his changes to feature2 by using commands similar to Mark's previously:


Now imagine that we have a source master similar to what I defined in the second post in this series: a person who manages all the merges between branches. I will modestly play this role, and manage any merging that needs to take place. So we take a look at the project plan and see that feature1 needs to go into release 1.1, while feature2 is slated for release 1.2. We need to merge feature1 into master to prepare that release, and once complete, tag that release as version 1.1, or v1.1. I'll step out to the command line to complete the merge (most source masters would likely use a GUI tool for this, but the command line is better for demonstration purposes):

So our master branch now contains Mark's work performed against feature1, and we can package up v1.1 and prepare it to be released to our QA and Prod environments. I'll cover what that process looks like in the last post in this series. For now... let's return to the fast forward merge strategy since we see this strategy used once again. Git performs a fast forward merge when one branch is directly upstream of the other... and it simply has to move the pointer forward to update the branch. This is the sort of functionality that Subversion simply doesn't have.
As the source master, we've again taken a look at the project plan and we see it's time to package up version 1.2, which will contain the work done by Jon Mead on the feature2 branch. We go back to the command-line and merge the branch into master and tag the release:

We didn't get the fast forward merge here... Git used the recursive merge instead. This occurs when we have actual changes to merge together... when one branch is not a complete ancestor of the other. What Git does in this situation is a three-way merge, not unlike the three-way merge the Admin Tool does when using MUDE, but arguably much more advanced. In this case, we don't have to specify the ancestor, as we do with RPD merges in the Admin Tool. Instead, Git figures out the most efficient ancestor to use, sometimes creating "virtual ancestors" as combinations between one or more actual ancestors. We can open up the merged and tagged MDS XML repository and have a look at the results:

We have all the changes from feature1 and feature2 merged together into master and contained in the tagged release v1.2. What we've seen so far is Git and MDS XML at their best. We used multi-branch development without any hiccups because Mark and Jon were not touching the same objects during development, which made the merges easy and predictable. If the source master ensures that feature branches never overlap, then what you have witnessed will be the norm for your environment. For many small shops with only a few developers... this is possibly a workable solution. However, as well all know, this is not always the case, and we'll have to see how Git and MDS XML handle merges when the same objects are touched in different feature branches. To be continued.