Data Integration Tips: ODI - One Data Server with several Physical Schemas

Yes, I'm hijacking the "Data Integration Tips" series of my colleague Michael Rainey (@mRainey) and I have no shame!
DISCLAIMER
This tip is intended for newcomers in the ODI world and is valid with all the versions of ODI. It's nothing new, it has been posted by other authors on different blogs. But I see so much people struggling with that on the ODI Space on OTN that I wanted to explain it in full details, with all the context and with my own words. So next time I can just post a link to this instead of explaining it from scratch.
The Problem
I'm loading data from a schema to another schema on the same Oracle database but it's slower than when I write a SQL insert statement manually. The bottle neck of the execution is in the steps from the LKM SQL to SQL. What should I do?
Why does it happen?
Loading Knowledge Modules (LKMs) are used to load the data from one Data Server to another. It usually connects to the source and the target Data Server to execute some steps on each of them. This is required when working with different technologies or different database instances for instance. So if we define two Data Servers to connect to our two database schemas, we will need a LKM.
In this example, I will load a star schema model in HR_DW schema, using the HR schema from the same database as a source. Let's start with the approach using two Data Servers. Note that here we use directly the database schema to connect to our Data Servers.
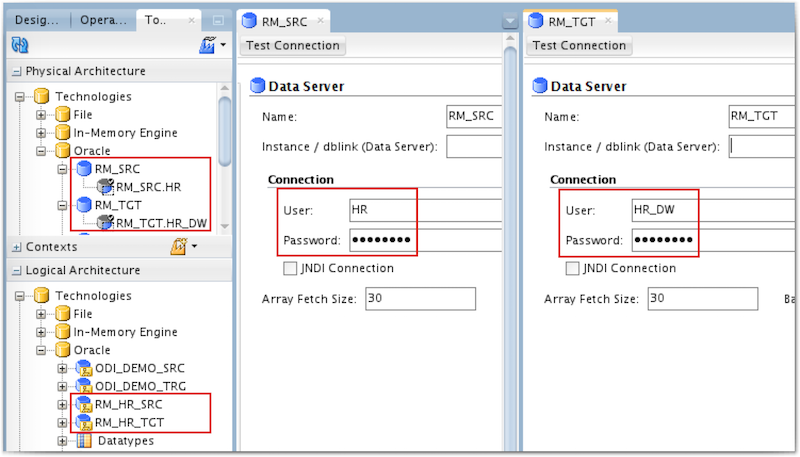
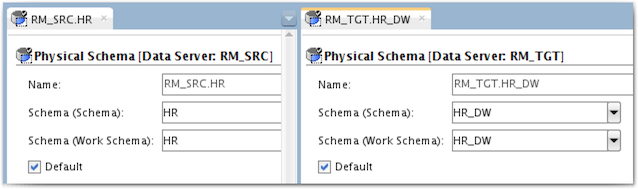
And here are the definitions of the physical schemas :
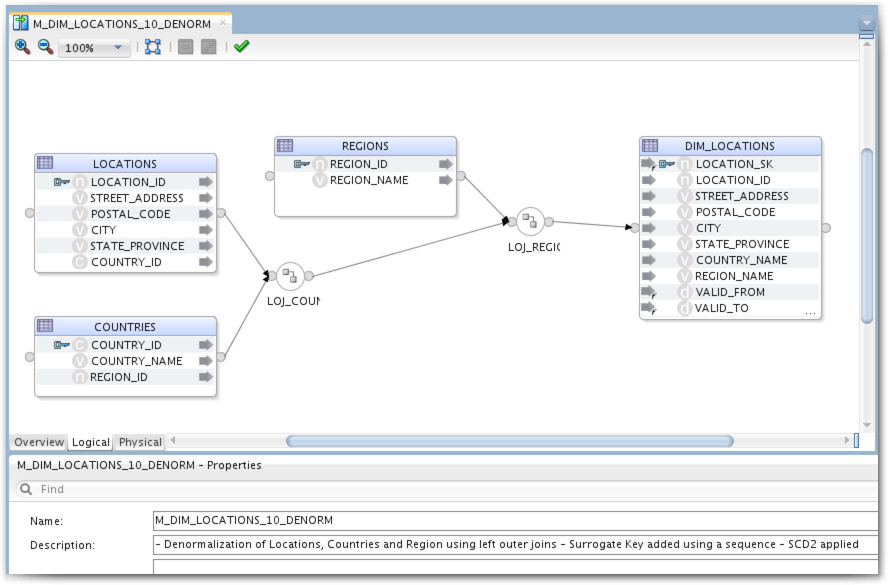
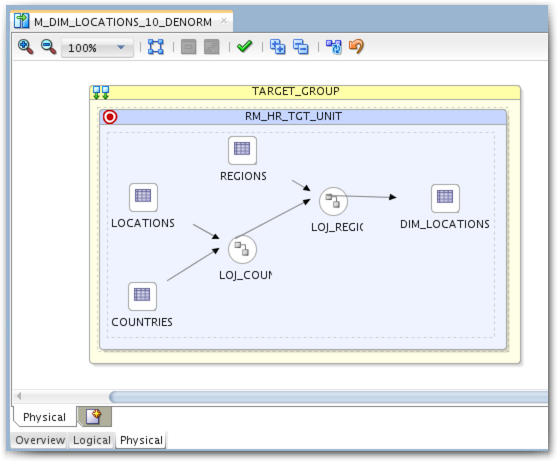
Let's build a simple mapping using LOCATIONS, COUNTRIES and REGIONS as source to denormalize it and load it into a single flattened DIM_LOCATIONS table. We will use Left Outer joins to be sure we don't miss any location even if there is no country or region associated. We will populate LOCATION_SK with a sequence and use an SCD2 IKM.
If we check the Physical tab, we can see two different Execution Groups. This mean the Datastores are in two different Data Servers and therefore a LKM is required. Here I used LKM SQL to SQL (Built-In) which is a quite generic one, not particularly designed for Oracle databases. Performances might be better with a technology-specific KM, like LKM Oracle to Oracle Pull (DB Link). By choosing the right KM we can leverage the technology-specific concepts – here the Oracle database links – which often improve performance. But still, we shouldn't need any database link as everything lies in the same database instance.
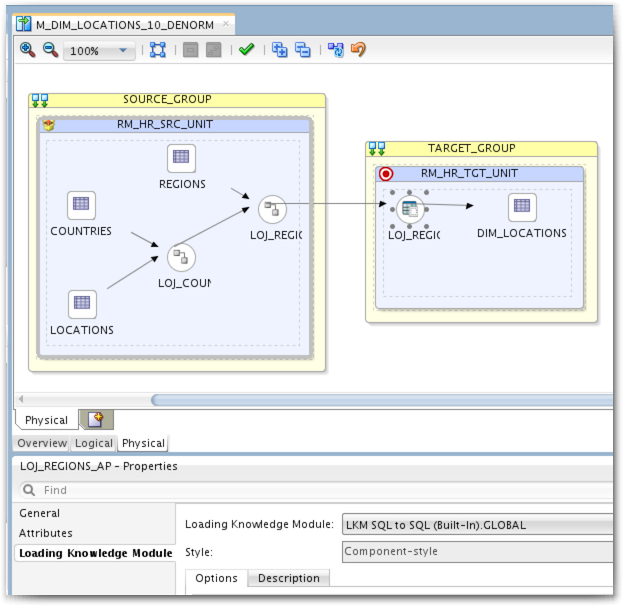
Another issue is that temporary objects needed by the LKM and the IKM are created in the HR_DW schema. These objects are the C$_DIM_LOCATIONS table created by the LKM to bring the data in the Target Data Servers and the I$_DIM_LOCATIONS table created by the IKM to detect when a new row is needed or when a row needs to be updated according to the SCD2 rules. Even though these objects are deleted in the clean-up steps at the end of the mapping execution, it would be better to use another schema for these temporary objects instead of target schema that we want to keep clean.
The Solution
If the source and target Physical Schemas are located on the same Data Server – and the technology can execute code – there is no need for a LKM. So it's a good idea to try to reuse as much as possible the same Data Server for data coming from the same place. Actually, the Oracle documentation about setting up the topology recommends to create an ODI_TEMP user/schema on any RDBMS and use it to connect.
This time, let's create only one Data Server with two Physical schemas under it and let's map it to the existing Logical schemas. Here I will use ODI_STAGING name instead of ODI_TEMP because I'm using the excellent ODI Getting Started virtual machine and it's already in there.
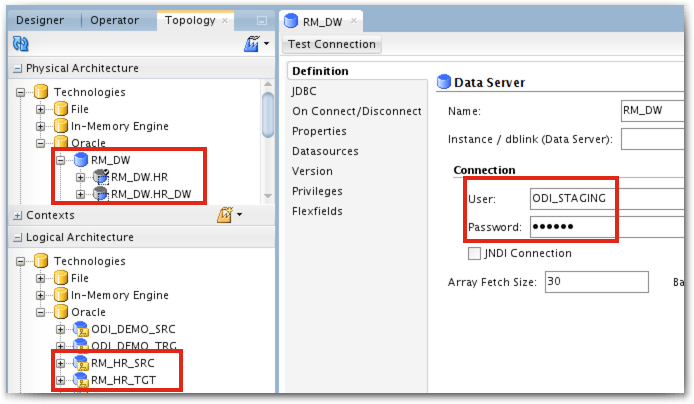
As you can see in the Physical Schema definitions, there is no other password provided to connect with HR or HR_DW directly. At run-time, our agent will only use one connection to ODI_STAGING and execute code through it, even if it needs to populate HR_DW tables. It means that we need to be sure that ODI_STAGING has all the required privileges to do so.
Here are the privileges I had to grant to ODI_STAGING :
GRANT SELECT on HR.LOCATIONS TO ODI_STAGING; GRANT SELECT on HR.COUNTRIES TO ODI_STAGING; GRANT SELECT on HR.REGIONS TO ODI_STAGING; GRANT SELECT, INSERT, UPDATE, DELETE on HR_DW.DIM_LOCATIONS to ODI_STAGING; GRANT SELECT on HR_DW.DIM_LOCATIONS_SEQ to ODI_STAGING;
Let's now open our mapping again and go on the physical tab. We now have only one Execution Group and there is no LKM involved. The code generated is a simple INSERT AS SELECT (IAS) statement, selecting directly from the HR schema and loading into the HR_DW schema without any database link. Data is loaded faster and our first problem is addressed.
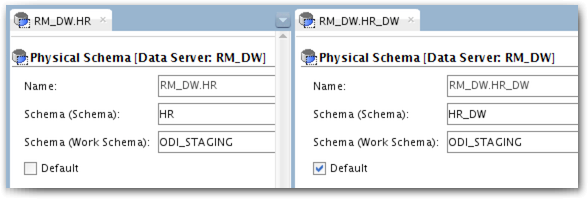
Now let's tackle the second issue we had with temporary objects being created in HR_DW schema. If you scroll upwards to the Physical Schema definitions (or click this link, if you are lazy...) you can see that I used ODI_STAGING as Work Schema in all my Physical Schemas for that Data Server. This way, all the temporary objects are created in ODI_STAGING instead of the source or target schema. Also we are sure that we won't have any issue with missing privileges, because our agent uses directly ODI_STAGING to connect.
So you can see it has a lot of advantages using a single Data Server when sources come from the same place. We get rid of the LKM and the schema used to connect can also be used as Work Schema so we keep the other schemas clean without any temporary objects.
The only thing you need to remember is to give the right privileges to ODI_STAGING (or ODI_TEMP) on all the objects it needs to handle. If your IKM has a step to gather statistics, you might also want to grant ANALYZE ANY. If you need to truncate a table before loading it, you have two approaches. You can grant DROP ANY table to ODI_STAGING, but this might be a dangerous privilege to give in production. A safer way is to create a stored procedure ODI_TRUNCATE in all the target database schema. This procedure takes a table name as a parameter and truncates that table using the Execute Immediate statement. Then you can grant execute on that procedure to ODI_STAGING and edit your IKM step to execute that procedure instead of using the truncate syntax.
That's it for today, I hope this article can help some people to understand the reason of that Oracle recommendation and how to implement it. Stay tuned on this blog and on Twitter (@rittmanmead, @mRainey, @markrittman, @JeromeFr, ...) for more tips about Data Integration!