ETL Offload with Spark and Amazon EMR - Part 4 - Analysing the Data

We recently did a project we did for a client, exploring the benefits of Spark-based ETL processing running on Amazon's Elastic Map Reduce (EMR) Hadoop platform. The proof of concept we ran was on a very simple requirement, taking inbound files from a third party, joining to them to some reference data, and then making the result available for analysis.
The background to the project is here, I showed here how I built up the prototype PySpark code on my local machine, and then here how it could be run on Amazon's EMR hadoop platform automatically.
In this article I'm going to discuss the options for analysing the data and producing reports from it.
Squeegee Your Third Eye
Where do we store data for analysis? Databases, right? That's what we've always done. Whether Oracle, SQL Server, or even Redshift - we INSERT, UPDATE, and SELECT our data in a database, and all is well and happy with the world.
But ... what if you didn't need a database per se to query your data?
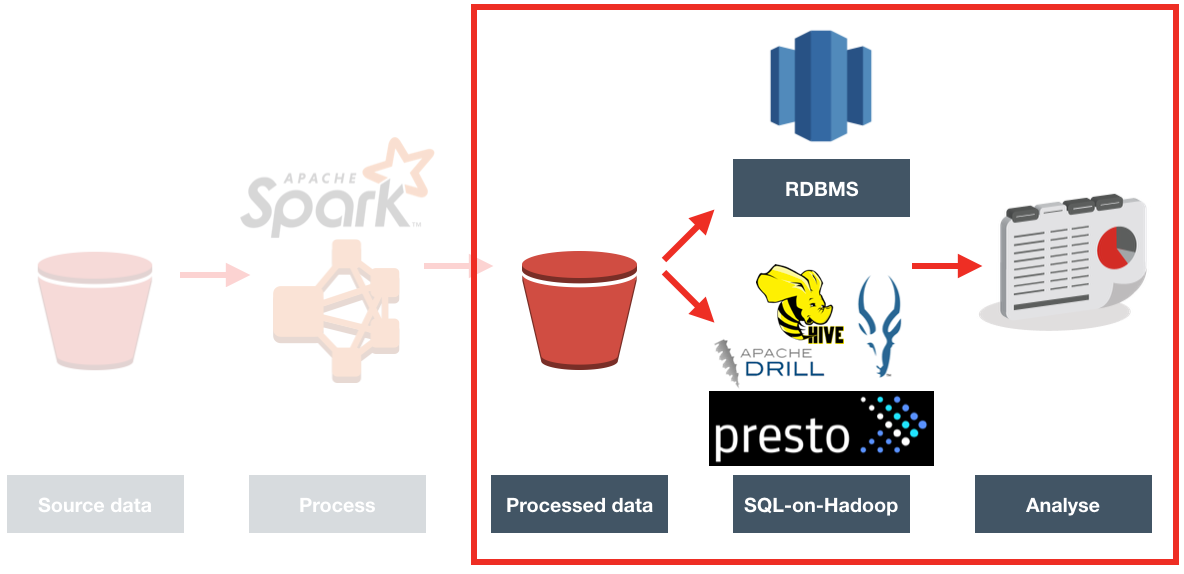
One of the things I wanted to explore during this project was the feasibility and response times that "SQL on Hadoop" engines could bring. Hive is probably the most well known of these, with other options including Apache Impala (incubating), Apache Drill, Presto, and even Oracle's Big Data SQL. All these tools read data that is not stored in a proprietory database format but stored in an open format, such a simple text file, on open storage platform such as HDFS. More commonly, formats (also open, non-proprietory) which are optimised for performance such as Parquet or ORC are used.
The advantage of these is that they provide multiple options for working with your data, starting from the same base storage place (usually HDFS, or S3). If one tool has benefits over another in a particular processing or analytics scenario we have the option to switch, without having to do anything to the actual data at rest itself. Contrast this to the implicit assumption that the data starts in an RDBMS (such as Oracle). With the data in a proprietary database the only options for switching tools are which ones you use to submit workload (over JDBC/ODBC/OCI etc). If another database platform is better in a given use case you end up either duplicating the data, or re-platforming the data entirely.
So whilst the flexibility of SQL-on-Hadoop is very appealing, there are limitations to it currently, in areas including performance and levels of ANSI SQL support.
Throughout this evaluation, my considerations were:
- Performance. The client we were doing this project for performs both batch querying as well as ad-hoc analytics
- Complexity, in two areas:
- Configuration and optimisation : The more configuration and careful tending that a platform needs, the greater the overall cost. Oracle may have its license implications compared to open-source software, but how to operate it for optimal performance is well known and documented. It's also an extremely mature product, having solved many of the problems that newer technologies are only just starting to realise, let alone solve.
- Load process: Whilst the SQL-on-Hadoop engines don't "load" the data, they sometimes require it to be laid out in a particular pattern of folders, or in a particular format for optimal performance.
- Compatibility. JDBC or ODBC interfaces are needed to be able to use the tool with BI tools such as OBIEE or Oracle's Data Visualization Desktop. As well as the interface, the SQL language support needs to be sufficient for analytical queries.
For an overview of SQL-on-Hadoop engines see this presentation from Greg Rahn. It's a couple of years old but pretty much still current bar the odd version and feature change.
Redshift
Redshift is not SQL-on-hadoop - it is a full-blown database. Specifically, it is a proprietory implementation of Postgres by Amazon, running as a service on their cloud. Just as you can provision an EMR cluster of any required size, you can do the same for Redshift. As your capacity and processing requirements change, you can scale your Redshift cluster up and down.
Redshift has both JDBC and ODBC drivers, making it accessible from both Data Visualization Desktop (supported) and OBIEE (works, but not supported).
To work with Redshift you can use a tool just as SQL WorkbenchJ, or the psql commandline tool. I installed the latter on my Mac using brew and brew install postgres.
With the processed data held on S3, loading it into Redshift is as simple as defining the table (with standard CREATE TABLE DDL), and then issuing a COPY command:
COPY ACME FROM 's3://foobar-bucket/acme_enriched/'
CREDENTIALS 'aws_access_key_id=XXXXXXXXXXXXXX;aws_secret_access_key=YYYYYYYYYYYY'
CSV
NULL AS 'null'
MAXERROR 100000
;
This takes any file under the given S3 path (and subfolders), parses it as a CSV, and loads it into the table. It presumes that the columns in the table are in the order that they are in the CSV file.
As a rough idea of load timings across several separate load jobs:
- 2M rows in 10 minutes
- 6M rows in 30 minutes
- 23M rows in 1h18 minutes
Just like with the Spark coding, I didn't undertake any performance optimisations or 'good practices'. No sort keys or distribution configuration - just however it came by default, I used.
Out of the box, response times were pretty good - here's a sample of the queries. They're going across the same set of data (23M rows), stored on Redshift with no defined sort keys, distribution keys, etc - just however it comes out of the box with a vanilla CREATE TABLE DDL.
-
COUNT all records - 0.2 seconds
dev=# select count(*) from acme3; count ---------- 23011785 (1 row) Time: 225.053 ms -
COUNT, GROUP BY - 2.0 seconds
dev=# select country,site_category, count(*) from acme3 group by country,site_category; country | site_category | count ---------+----------------+--------- GB | Indirect | 512519 [...] (34 rows) Time: 2043.805 ms -
COUNT, GROUP BY day (with DATE_TRUNC function) - 1.6 seconds
dev=# select date_trunc('day',date_launched),country,count(*) from acme3 group by date_trunc('day',date_launched),country; date_trunc | country | count ---------------------+---------+-------- 2016-01-01 00:00:00 | GB | 24795 [...] (412 rows) Time: 1625.590 ms -
COUNT, GROUP BY week (with DATE_TRUNC function) - 3.8 seconds
dev=# select date_trunc('week',date_launched),country,count(*) from acme3 group by date_trunc('week',date_launched),country; date_trunc | country | count ---------------------+---------+--------- 2016-01-18 00:00:00 | GB | 1046417 2016-01-25 00:00:00 | GB | 945160 2016-02-01 00:00:00 | GB | 1204446 2016-02-08 00:00:00 | GB | 874694 [...] (77 rows) Time: 3871.230 ms -
COUNT, GROUP BY, WHERE, ORDER BY - 5.4 seconds
dev=# select supplier, product, product_desc,count(*) from acme3 where lower(product_desc) = 'beans' group by supplier,product,product_desc order by 4 desc limit 2; supplier | product | product_desc | count ---------------------+-----------------+--------------+------ ACME BEANS CO | baked beans | BEANS | 2967 BEANZ MEANZ | beans + saus | Beans | 2347 (2 rows) Time: 5427.035 ms
Hive (on Tez)
Hive enables you to run queries with SQL-like language (Hive QL) on data stored in various places including HDFS, and S3. It supports multiple formats of data, including simple delimited text files like CSV, and more advanced formats such as Parquet.
The version of Hive that I was using on EMR was automagically configured to use Tez as its execution engine, instead of the traditional map/reduce of the original Hadoop platform.
To query the data, simply define an EXTERNAL table. Why an EXTERNAL table? Well if you just define a TABLE, and then drop it ... it will also delete the underlying data. It's one of those syntax decisions that makes brutally logical sense, but burnt me and I'm sure has burnt many others. But, you won't do it again (or at least, not for a while).
CREATE EXTERNAL TABLE acme
(
product_desc STRING,
product STRING,
product_type STRING,
supplier STRING,
date_launched TIMESTAMP,
[...]
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://foobar-bucket/acme_enriched';
With the table defined you can test that it works using the LIMIT clause to only pull back some of the records:
hive> select product_desc,supplier,country from acme3 limit 5;
OK
Baked Beans BEANZ MEANZ GB
Tinned Tom VEG CORP GB
Tin Foil FOIL SOLN GB
Shreddies CRUNCHYCRL GB
Lemonade FIZZ POP GB
Whilst Hive technically enables you to query your data, the response times are so high that it's not even really a candidate for batch reporting.
Here's a couple of examples against a very small set of data, held in CSV format:
hive> select count(*) from acme;
21216
Time taken: 58.063 seconds, Fetched: 1 row(s)
hive> select country,count(*) from acme group by country;
US 21216
Time taken: 50.646 seconds, Fetched: 1 row(s)
Tez helpfully provides a progress report of queries, such as this one here - a simple count of all rows, on a much larger dataset (25M rows, CSV files). After seven minutes, I gave up - with 3% of the query complete
hive> select count(*) from acme3;
Query ID = hadoop_20161019112007_cca7d37f-c5af-47f2-9d7d-3187342fbbb3
Total jobs = 1
Launching Job 1 out of 1
Tez session was closed. Reopening...
Session re-established.
Status: Running (Executing on YARN cluster with App id application_1476873946157_0002)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 container RUNNING 107601 3740 5 103856 0 6
Reducer 2 container RUNNING 1 0 1 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 00/02 [>>--------------------------] 3% ELAPSED TIME: 442.36 s
----------------------------------------------------------------------------------------------
As with elsewhere in the exercise - I'm well aware that there are optimisations that could be made that could help with response time, such as storing the data in more optimal formats (ORC/Parquet) and layouts (partitioning) as well as compresing it.
Don't write Hive off though - the latest versions (being developed by Hortonworks, and not on EMR yet) are moving to use in-memory components and competing well against Impala.
Impala
Impala is Cloudera's open-source offering in the SQL-on-Hadoop space. I was hoping to try out Impala against the data in S3, especially given a recent post by Cloudera with some promising performance metrics. Unfortunately this was for Impala 2.6, and the only version available prebuilt on EMR was 1.2.4. Given time, it would have been possible to build my own CDH-based Hadoop cluster (using Director to automate it) with the latest version of Impala installed - but this will have to be for another day. The current Cloudera documentation also suggests that S3 is:
[...]more suitable for holding 'cold' data that is only queried occasionally
although it's not clear if that's still true in the context of the latest Impala S3 optimisations.
Presto
Presto is an open source project that originated at Facebook. Similar to Apache Drill (below), it can query across data (and federate the results) from multiple sources including Hive (and thus S3), MongoDB, MySQL, and even Kafka.
For Presto to query against the data in S3, you need to define the table in Hive first. Presto uses the Hive metastore to retrieve the definition of the table, and carries out the actual query execution itself. First, a simple smoke test that we can pull back some data:
$ presto-cli --catalog hive --schema default
presto:default> select product_desc,supplier,country from acme limit 5;
product_desc | supplier | country
-------+-------+---------
(0 rows)
Query 20161019_110919_00004_ev4hz, FINISHED, 1 node
Splits: 1 total, 1 done (100.00%)
0:01 [0 rows, 0B] [0 rows/s, 0B/s]
No data. Hmm. The exact same query against the same Hive table does return data. Turns out that Presto, by default, won't recursively query subfolders, whilst Hive, by default, does. After amending /etc/presto/conf.dist/catalog/hive.properties to set hive.recursive-directories=true and restarting Presto (sudo restart presto-server) on each EMR node, I then got data back:
presto:default> select count(*) from acme_latam;
_col0
---------
1993955
(1 row)
Query 20161019_200312_00003_xa352, FINISHED, 2 nodes
Splits: 44 total, 44 done (100.00%)
0:10 [1.99M rows, 642MB] [203K rows/s, 65.3MB/s]
This was against a 1.9M row dataset, held in CSV format. Run again soon after, and the response time was 3 seconds.
Querying a bigger set of data was slower - 4 minutes for 23M rows of data:
presto:default> select count(*) from acme3;
_col0
----------
23105948
(1 row)
Query 20161019_200815_00006_xa352, FINISHED, 2 nodes
Splits: 52,970 total, 52,970 done (100.00%)
4:04 [23.1M rows, 9.1GB] [94.8K rows/s, 38.2MB/s]
Same timing for doing a GROUP by on the data too:
presto:default> select country,site_category, count(*) from acme3 group by country,site_category;
country | site_category | _col2
--------+--------------------+----------
GB | Price comparison | 146
GB | DIRECT RETAIL | 10903
[...]
Query 20161019_201443_00013_xa352, FINISHED, 2 nodes
Splits: 52,972 total, 52,972 done (100.00%)
4:54 [23.1M rows, 9.11GB] [78.6K rows/s, 31.7MB/s]
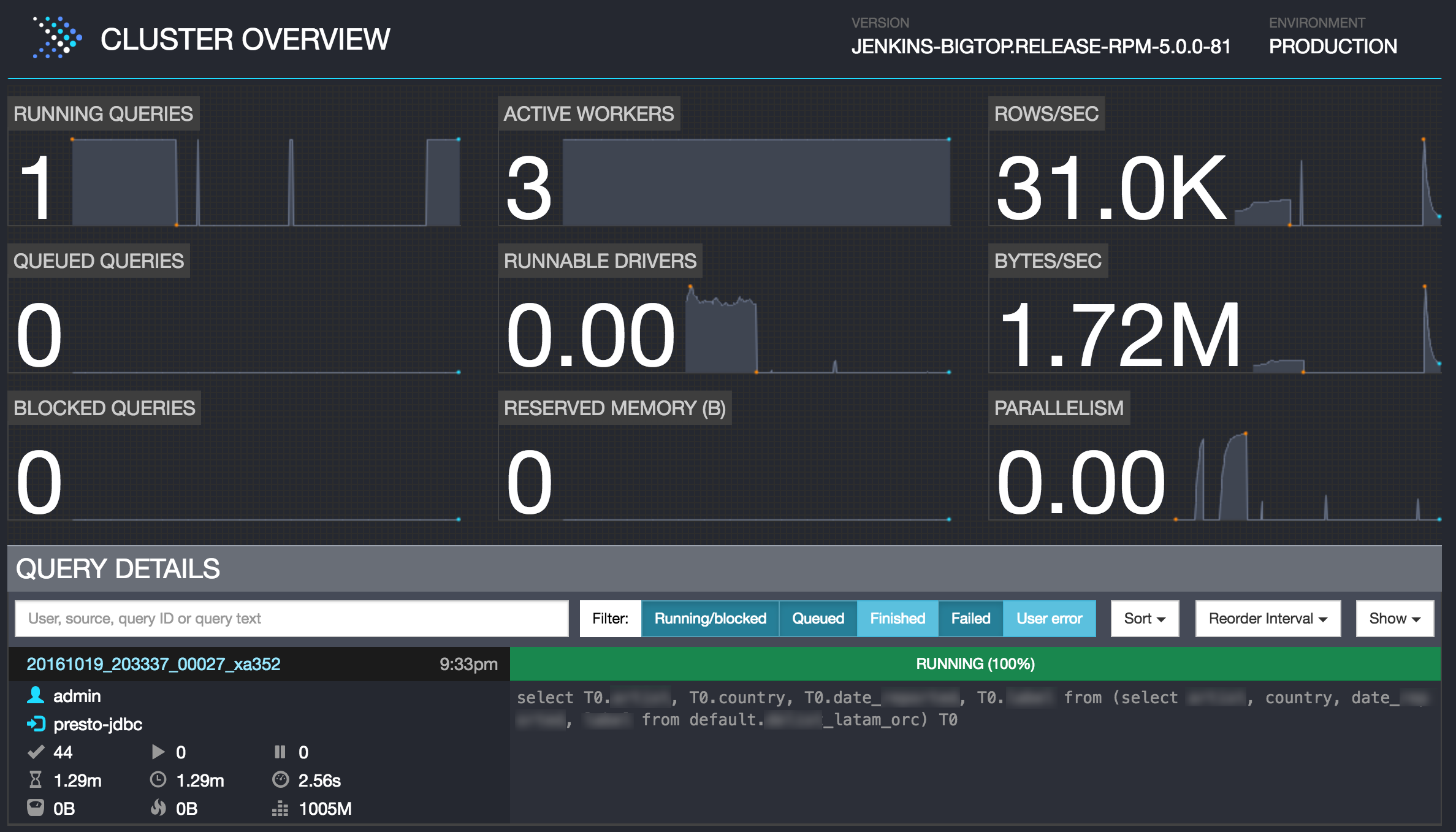
Presto includes a swanky web interface for seeing the status and execution of queries
Loading to ORC
Taking a brief detour into one of the most common recommendations for performance with Presto - storing data in ORC format.
First, in Hive, I created an ORC-stored table:
CREATE EXTERNAL TABLE acme_orc
(
product_desc STRING,
product STRING,
product_type STRING,
supplier STRING,
date_launched TIMESTAMP,
[...]
)
STORED AS ORC
LOCATION 's3://foobar-bucket/acme_orc/';
and then loaded a small sample of data:
hive> insert into acme_orc select * from acme_tst;
Querying it in Presto:
presto:default> select count(*) from acme_orc;
_col0
-------
29927
(1 row)
Query 20161019_113802_00008_ev4hz, FINISHED, 1 node
Splits: 2 total, 2 done (100.00%)
0:01 [29.9K rows, 1.71MB] [34.8K rows/s, 1.99MB/s]
With small volumes this was fine - 90 seconds to load 30k rows into an ORC-stored table, and a second to then query that from Presto with a count across all rows.
Loading 1.9M rows into an ORC-stored table took 30 minutes, and didn't actually (on the surface) speed things up. Caveat: this was a first pass at optimisation; there'll be a dozen settings and approaches to try out before any valid conclusions can be drawn from it:
-
COUNT GROUP BY from 1.9M rows, ORC - 3 seconds
presto:default> select country,site_category, count(*) from acme_latam_orc group by country,site_category; country | site_category | _col2 ---------+---------------+--------- LATAM | null | 1993955 (1 row) Query 20161019_202206_00017_xa352, FINISHED, 2 nodes Splits: 46 total, 46 done (100.00%) 0:03 [1.99M rows, 76.2MB] [790K rows/s, 30.2MB/s] -
COUNT over 1.9M rows, CSV - 3 seconds
presto:default> select country,site_category, count(*) from acme_latam group by country,site_category; country | site_category | _col2 ---------+---------------+--------- LATAM | null | 1993955 (1 row) Query 20161019_202241_00018_xa352, FINISHED, 2 nodes Splits: 46 total, 46 done (100.00%) 0:03 [1.99M rows, 642MB] [575K rows/s, 185MB/s] -
Function and filter, 1.9M rows, ORC
presto:default> select count(*) from acme_latam_orc where lower(product_desc) = 'eminem'; _col0 ------- 2107 (1 row) Query 20161019_202558_00019_xa352, FINISHED, 2 nodes Splits: 44 total, 44 done (100.00%) 0:04 [1.99M rows, 76.2MB] [494K rows/s, 18.9MB/s] -
Function and filter, 1.9M rows, CSV
presto:default> select count(*) from acme_latam where lower(product_desc) = 'eminem'; _col0 ------- 2107 (1 row) Query 20161019_202649_00020_xa352, FINISHED, 2 nodes Splits: 44 total, 44 done (100.00%) 0:03 [1.99M rows, 642MB] [610K rows/s, 196MB/s]
Trying to load greater volumes (23M rows) to ORC was unsuccessful, due to memory issues with the Hive execution.
Status: Running (Executing on YARN cluster with App id application_1476905618527_0004)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------
VERTICES: 00/00 [>>--------------------------] 0% ELAPSED TIME: 13956.69 s
----------------------------------------------------------------------------------------------
Status: Failed
Application application_1476905618527_0004 failed 2 times due to AM Container for appattempt_1476905618527_0004_000002 exited with exitCode: 255
In the Tez execution log was the error
Diagnostics: Container [pid=4642,containerID=container_1476905618527_0004_01_000001] is running beyond physical memory limits. Current usage: 1.0 GB of 1 GB physical memory used; 2.7 GB of 5 GB virtual memory used. Killing container.
With appropriate investigation (and/or smaller chunks of data loading) this could obviously be overcome, but for now halted any further investigation into ORC's usefulness. The other major area to investigate would be partitioning of the data.
A final note on performance - this blog does a comparison of Presto querying data held in S3 vs HDFS on EMR. HDFS on EMR is quicker, generally about 1.5 times or so - but you of course need your data loaded into HDFS on a running EMR cluster, whereas S3 is there on demand whenever you want it.
Drill
Apache Drill is another open-source tool, similar in concept to Presto, in that it enables querying across data held in multiple sources. I've written about it previously here and here. Whilst EMR has an option to provision a Drill cluster as part of an EMR build, it didn't seem to work when I tried it - and with Presto running I didn't spend the time digging into Drill. Given another time and project though, I'd definitely be looking to run it against this kind of data to see how it handled it. A recent thread on the Drill mailing list gave some interesting information on performance.
Athena
Amazon's Athena tool was announced at re:Invent 2016. Even though it was made GA after the client project being discussed here and therefore not evaluated, it is definitely worth mentioning. It provides "serverless" SQL querying of data held in S3. Under the covers it uses Presto (which is one of the tools I evaluated above). The benefit of Athena is that you wouldn't need to provision and configure actual servers to use Presto. You work with it through the web-based interface, or JDBC. This is a pretty big point to make - you can query your data, held in an open format, on demand, using SQL, without having to move it into a database or build a server to run a query engine.
Athena looks interesting, but one of the main things that struck me about it was that it is not something you would simply point at piles of data on S3 and build your analytics systems on. The cost is per query, and is currently $5 per TB scanned. FIVE DOLLARS, per terabyte of data SCANNED. Not retrieved. Scanned. So in order to not run up big AWS bills if you've got lots of data, you're going to need to do smart things to reduce the size of data scanned. Partitioning your data, and compressing it, will both help. As it happens, these are the things that are going to increase performance too, so it's not wasted effort. There's a good writeup here demonstrating Athena, and the difference that using an appropriate storage format for the data makes to performance and volumes of data scanned (and thus cost).
The cost consideration is a crucial point, because it means that data 'engineering' is still needed in any system you plan to build Athena on top of as the query engine. Sure, you can use it for adhoc 'fishing' expeditions in your 'data lake' (sorry....). Here the benefit of sifting through vast and disparate data without having to transform and/or load it into a queryable form first will probably outweigh the ad-hoc costs (remember : $5 per TB scanned). But as I said, if you're engineering Athena into your system as the SQL engine of top of data at rest in S3, you'll want to invest in the necessary wrangling in order to store the data (a) partitioned and (b) compressed.
You can read more about Athena here.
Front End Tools
All of the exploration so far has been from the commandline, but users want their data visually. The client for whom we were doing this work currently use OBIEE and BI Publisher to deliver the data. Both Redshift and Presto have JDBC and ODBC drivers, which means that they should work with OBIEE (although neither are on the supported databases list). Oracle's Data Visualization Desktop tool is also of interest here, bringing with it native support for both Redshift and Presto (beta).
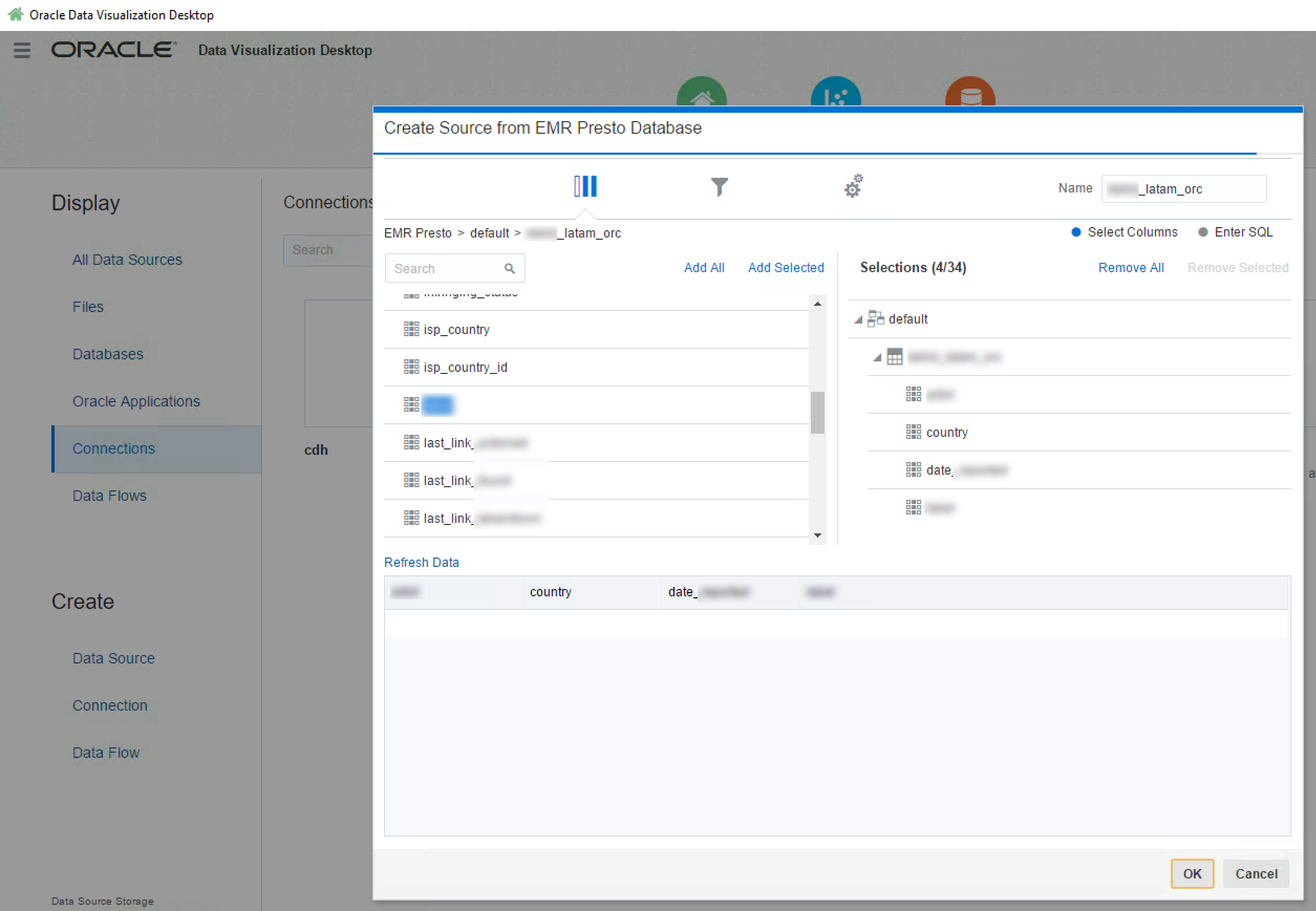
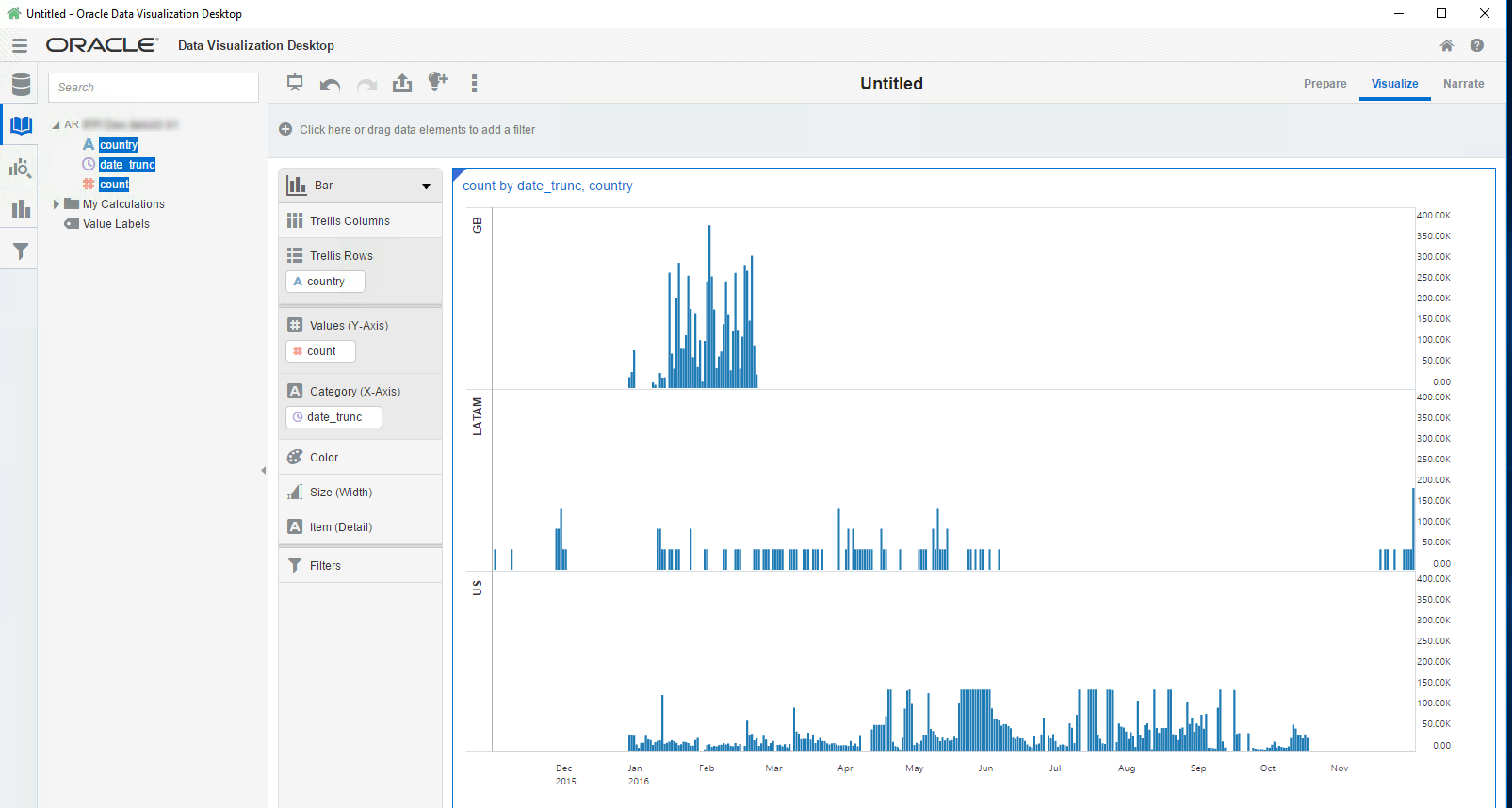
A tool that we didn't examine, but is directly relevant given the Amazon context, is Quicksight. Currently in closed-preview Released in mid-November 2017, this is a cloud-based tool that enables querying of data in many sources including Redshift -- but also S3 itself.
Summary
For interactive analysis, Redshift performed well straight off. However, with some of the in-memory capabilities of the SQL-on-Hadoop engines, and the appeal of simply provisioning compute to query data held on S3 when required, it would be interesting to spend some time digging into the recommended optimisations and design patterns to see just how fast the querying could be.
Since all the query engines considered support JDBC, and any respectable front-end tool can query JDBC, we're not constrained in the choice of one by the other. Hooray for open standards enabling optimal choice and pairing of technologies! I liked using Oracle DV Desktop as it's a simple install and quick to get visualisations out of. Ultimately the choice of tool would come down to factors including complexity of requirements, scale of deployment - and of course, cost.
In the final article in this series we'll take a recap over the whole project, and look at some of the broader points of interest to draw from it.