Back From the Hotel of Misery, Progress on the Aggregation Setup
Well, I'm back home in my own house tonight after my week of misery and despair in my hotel in Newbury. I guess I've been spoilt recently working up in Soho, London, but a week of nights on my own in a bleak single room, with only a sandwich to look forward to the next day from the Texaco petrol station, and unrelenting rain and overcast skies makes coming home all that much sweeter. In fact the only highlight (apart from the selection of stale custard creams and jammy dodgers that were left in my room each day by the cleaner) was making a bit of progress with my aggregation testing project for the UKOUG conference later this year. I ended up taking David Aldridge up on an offer for some advice on the materialized view side of things, and as I all I otherwise had to do each evening when I got to my room at 5.30 was eat the custard creams, I got a fair bit done.
I started off by amending the script I wrote the other day to create the schemas, to instead create them all with the same default tablespace - the EXAMPLE one that the SH schema normally uses. This was because I was spending more and more time just trying to get the export from the SH schema to go into these new schemas, I tried all the normal steps of setting a quote of zero on the EXAMPLE schema for the SH_AW, SH_MV and SH_ODM users, removing the UNLIMITED TABLESPACE and RESOURCE priviledges, and in the end I gave up and put them all in the same tablespace. Maybe later on I'll try again but I was getting nowhere fast and I needed to get some sort of result to cheer myself up. The revised script to set up the test environment can now be downloaded here.
Next I wanted to put a script together to load data into the empty schemas (the export from the SH schema was with ROWS=N, so I could pick up the table structures, indexes, dimensions and so on, but not the data). First of all though, I created a new user called SH_TEST_RESULTS in which I created two tables, one to hold the results of the tests I ran, the other just a lookup table of run types, the idea being that the scripts would write the start and end times of each run in the table, and I could run and run the scripts again and again to check that the results I get aren't just a one-off - infact the whole set of tests will be scriptable so that I can quickly run them again if I want to try something new out. Anyway, the script to create the two tables in the test results schema is as follow (the SQL and DDL was auto-generated from SQL Developer, hence the formatting and the trigger code for the table sequence)
conn sh_test_results/password@ora10gdrop table results;
CREATE TABLE "SH_TEST_RESULTS"."RESULTS"
( "RUN_SEQUENCE_ID" NUMBER NOT NULL ENABLE,
"SCHEMA_NAME" VARCHAR2(6 BYTE) NOT NULL ENABLE,
"RUN_TYPE_ID" NUMBER(2,0) NOT NULL ENABLE,
"START_TIME" DATE,
"RUN_TIME_SECS" NUMBER (10,2),
CONSTRAINT "TABLE1_PK" PRIMARY KEY ("RUN_SEQUENCE_ID") ENABLE
) ;CREATE OR REPLACE TRIGGER "SH_TEST_RESULTS"."SEQ_TRIG"
before insert on "RESULTS"
for each ro
begin
if inserting then
if :NEW."RUN_SEQUENCE_ID" is null then
select RESULTS_SEQ.nextval
into :NEW."RUN_SEQUENCE_ID"
from dual;
end if;
end if;
end;
/
ALTER TRIGGER "SH_TEST_RESULTS"."SEQ_TRIG" ENABLE;CREATE TABLE "SH_TEST_RESULTS"."RUN_TYPE"
( "RUN_TYPE_ID" NUMBER(2,0) NOT NULL ENABLE,
"DESCRIPTION" VARCHAR2(30 BYTE) NOT NULL ENABLE,
CONSTRAINT "RUN_TYPE_PK" PRIMARY KEY ("RUN_TYPE_ID") ENABLE
) ;Insert into "RUN_TYPE" ("RUN_TYPE_ID","DESCRIPTION") values (1,'INITIAL LOAD');
Insert into "RUN_TYPE" ("RUN_TYPE_ID","DESCRIPTION") values (2,'INITIAL AGGREGATION');
Insert into "RUN_TYPE" ("RUN_TYPE_ID","DESCRIPTION") values (4,'INCREMENTAL AGGR 1');
Insert into "RUN_TYPE" ("RUN_TYPE_ID","DESCRIPTION") values (6,'INCREMENTAL AGGR 2');
Insert into "RUN_TYPE" ("RUN_TYPE_ID","DESCRIPTION") values (5,'INCREMENTAL LOAD 2');
Insert into "RUN_TYPE" ("RUN_TYPE_ID","DESCRIPTION") values (3,'INCREMENTAL LOAD 1');
Now that the users and the control table were set up, I started writing the code to load the first of the test users, SH_MV. This script would firstly INSERT /*+ APPEND */ data from the SH schema dimension tables into the SH_MV schema, then drop the bitmap indexes on the SALES table, load the table and then recreate the bitmap indexes. At the start and the end of the script I'd put code in to record the start time, then store it, the end time and the elapsed time in the control table, like this:
spool c:\agg_test_files\load_aw_mv.logconnect sh_mv/password@ora10g
variable start_time varchar2(20)
variable end_time varchar2(20)begin
select to_char(sysdate, 'DD:MM:YYYY HH:MI:SS') into :start_time from dual;
end;
/drop index sales_time_bix;
drop index sales_prod_bix;
drop index sales_cust_bix;
drop index sales_promo_bix;
drop index sales_channel_bix;insert /*+ APPEND */ into countries
select *
from sh.countries
/insert /*+ APPEND */ into customers
select *
from sh.customers
/insert /*+ APPEND */ into channels
select *
from sh.channels
/insert /*+ APPEND */ into times
select *
from sh.times
/insert /*+ APPEND */ into promotions
select *
from sh.promotions
/insert /*+ APPEND */ into products
select *
from sh.products
/insert /*+ APPEND */ into sales
select *
from sh.sales
/commit;
CREATE BITMAP INDEX "SALES_TIME_BIX" ON "SALES" ("TIME_ID")
LOCAL
(PARTITION "SALES_1995" ,
PARTITION "SALES_1996" ,
PARTITION "SALES_H1_1997" ,
PARTITION "SALES_H2_1997" ,
PARTITION "SALES_Q1_1998" ,
PARTITION "SALES_Q2_1998" ,
PARTITION "SALES_Q3_1998" ,
PARTITION "SALES_Q4_1998" ,
PARTITION "SALES_Q1_1999" ,
PARTITION "SALES_Q2_1999" ,
PARTITION "SALES_Q3_1999" ,
PARTITION "SALES_Q4_1999" ,
PARTITION "SALES_Q1_2000" ,
PARTITION "SALES_Q2_2000" ,
PARTITION "SALES_Q3_2000" ,
PARTITION "SALES_Q4_2000" ,
PARTITION "SALES_Q1_2001" ,
PARTITION "SALES_Q2_2001" ,
PARTITION "SALES_Q3_2001" ,
PARTITION "SALES_Q4_2001" ,
PARTITION "SALES_Q1_2002" ,
PARTITION "SALES_Q2_2002" ,
PARTITION "SALES_Q3_2002" ,
PARTITION "SALES_Q4_2002" ,
PARTITION "SALES_Q1_2003" ,
PARTITION "SALES_Q2_2003" ,
PARTITION "SALES_Q3_2003" ,
PARTITION "SALES_Q4_2003" )
/CREATE BITMAP INDEX "SALES_CHANNEL_BIX" ON "SALES" ("CHANNEL_ID")
LOCAL
(PARTITION "SALES_1995" ,
PARTITION "SALES_1996" ,
PARTITION "SALES_H1_1997" ,
PARTITION "SALES_H2_1997" ,
PARTITION "SALES_Q1_1998" ,
PARTITION "SALES_Q2_1998" ,
PARTITION "SALES_Q3_1998" ,
PARTITION "SALES_Q4_1998" ,
PARTITION "SALES_Q1_1999" ,
PARTITION "SALES_Q2_1999" ,
PARTITION "SALES_Q3_1999" ,
PARTITION "SALES_Q4_1999" ,
PARTITION "SALES_Q1_2000" ,
PARTITION "SALES_Q2_2000" ,
PARTITION "SALES_Q3_2000" ,
PARTITION "SALES_Q4_2000" ,
PARTITION "SALES_Q1_2001" ,
PARTITION "SALES_Q2_2001" ,
PARTITION "SALES_Q3_2001" ,
PARTITION "SALES_Q4_2001" ,
PARTITION "SALES_Q1_2002" ,
PARTITION "SALES_Q2_2002" ,
PARTITION "SALES_Q3_2002" ,
PARTITION "SALES_Q4_2002" ,
PARTITION "SALES_Q1_2003" ,
PARTITION "SALES_Q2_2003" ,
PARTITION "SALES_Q3_2003" ,
PARTITION "SALES_Q4_2003" )
/CREATE BITMAP INDEX "SALES_PROMO_BIX" ON "SALES" ("PROMO_ID")
LOCAL
(PARTITION "SALES_1995" ,
PARTITION "SALES_1996" ,
PARTITION "SALES_H1_1997" ,
PARTITION "SALES_H2_1997" ,
PARTITION "SALES_Q1_1998" ,
PARTITION "SALES_Q2_1998" ,
PARTITION "SALES_Q3_1998" ,
PARTITION "SALES_Q4_1998" ,
PARTITION "SALES_Q1_1999" ,
PARTITION "SALES_Q2_1999" ,
PARTITION "SALES_Q3_1999" ,
PARTITION "SALES_Q4_1999" ,
PARTITION "SALES_Q1_2000" ,
PARTITION "SALES_Q2_2000" ,
PARTITION "SALES_Q3_2000" ,
PARTITION "SALES_Q4_2000" ,
PARTITION "SALES_Q1_2001" ,
PARTITION "SALES_Q2_2001" ,
PARTITION "SALES_Q3_2001" ,
PARTITION "SALES_Q4_2001" ,
PARTITION "SALES_Q1_2002" ,
PARTITION "SALES_Q2_2002" ,
PARTITION "SALES_Q3_2002" ,
PARTITION "SALES_Q4_2002" ,
PARTITION "SALES_Q1_2003" ,
PARTITION "SALES_Q2_2003" ,
PARTITION "SALES_Q3_2003" ,
PARTITION "SALES_Q4_2003" )
/CREATE BITMAP INDEX "SALES_PROD_BIX" ON "SALES" ("PROD_ID")
LOCAL
(PARTITION "SALES_1995" ,
PARTITION "SALES_1996" ,
PARTITION "SALES_H1_1997" ,
PARTITION "SALES_H2_1997" ,
PARTITION "SALES_Q1_1998" ,
PARTITION "SALES_Q2_1998" ,
PARTITION "SALES_Q3_1998" ,
PARTITION "SALES_Q4_1998" ,
PARTITION "SALES_Q1_1999" ,
PARTITION "SALES_Q2_1999" ,
PARTITION "SALES_Q3_1999" ,
PARTITION "SALES_Q4_1999" ,
PARTITION "SALES_Q1_2000" ,
PARTITION "SALES_Q2_2000" ,
PARTITION "SALES_Q3_2000" ,
PARTITION "SALES_Q4_2000" ,
PARTITION "SALES_Q1_2001" ,
PARTITION "SALES_Q2_2001" ,
PARTITION "SALES_Q3_2001" ,
PARTITION "SALES_Q4_2001" ,
PARTITION "SALES_Q1_2002" ,
PARTITION "SALES_Q2_2002" ,
PARTITION "SALES_Q3_2002" ,
PARTITION "SALES_Q4_2002" ,
PARTITION "SALES_Q1_2003" ,
PARTITION "SALES_Q2_2003" ,
PARTITION "SALES_Q3_2003" ,
PARTITION "SALES_Q4_2003" ) ;CREATE BITMAP INDEX "SALES_CUST_BIX" ON "SALES" ("CUST_ID")
LOCAL
(PARTITION "SALES_1995" ,
PARTITION "SALES_1996" ,
PARTITION "SALES_H1_1997" ,
PARTITION "SALES_H2_1997" ,
PARTITION "SALES_Q1_1998" ,
PARTITION "SALES_Q2_1998" ,
PARTITION "SALES_Q3_1998" ,
PARTITION "SALES_Q4_1998" ,
PARTITION "SALES_Q1_1999" ,
PARTITION "SALES_Q2_1999" ,
PARTITION "SALES_Q3_1999" ,
PARTITION "SALES_Q4_1999" ,
PARTITION "SALES_Q1_2000" ,
PARTITION "SALES_Q2_2000" ,
PARTITION "SALES_Q3_2000" ,
PARTITION "SALES_Q4_2000" ,
PARTITION "SALES_Q1_2001" ,
PARTITION "SALES_Q2_2001" ,
PARTITION "SALES_Q3_2001" ,
PARTITION "SALES_Q4_2001" ,
PARTITION "SALES_Q1_2002" ,
PARTITION "SALES_Q2_2002" ,
PARTITION "SALES_Q3_2002" ,
PARTITION "SALES_Q4_2002" ,
PARTITION "SALES_Q1_2003" ,
PARTITION "SALES_Q2_2003" ,
PARTITION "SALES_Q3_2003" ,
PARTITION "SALES_Q4_2003" ) ;begin
select to_char(sysdate, 'DD:MM:YYYY HH:MI:SS') into :end_time from dual;
end;
/connect sh_test_results/password@ora10g
insert into sh_test_results.results (schema_name
, run_type_id
, start_time
, end_time
, run_time_secs)
values ('SH_MV'
, 1
, to_date(:start_time,'DD:MM:YYYY HH:MI:SS')
, to_date(:end_time,'DD:MM:YYYY HH:MI:SS')
, (to_date(:end_time,'DD:MM:YYYY HH:MI:SS') - to_date(:start_time,'DD:MM:YYYY HH:MI:SS')) * 86400
)
/commit;
spool off
Next, I do the same for the SH_ODM schema, changing the schema names as appropriate. Now I've got two schemas with data from the SH schema copied into them, and timings for how long the process took.
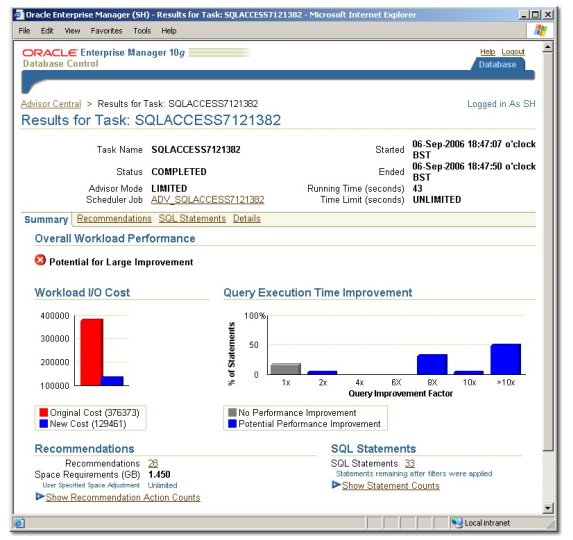
Now I come the the bit where I need to define the materialized views for the SH_MV schema. Now the idea I had for this before I started the tests, given that it's fairly tricky to come up with a correct set of summaries for a schema you've not queried before, is to use the SQL Access Advisor that you get with Oracle Database 10g. By logging on to Database Control and navigating to Advisor Central, you can get the SQL Access advisor to recommend a set of materialized views based on either a stored workload, or more appropriately for me, the dimensional metadata that exists for these tables in the form of CREATE DIMENSION statements.
Working through the SQL Access Advisor, I created an advisor job against the tables in the SH schema (this was before I set up the users, but it should hold the same for the SH_MV user) and let the job run; it came back with the encouraging message "Potential for Large Improvement" (sounds like my old P.E. report)
{kind=link}
Looking at the results, it had 28 recommendations ordered by effectiveness.
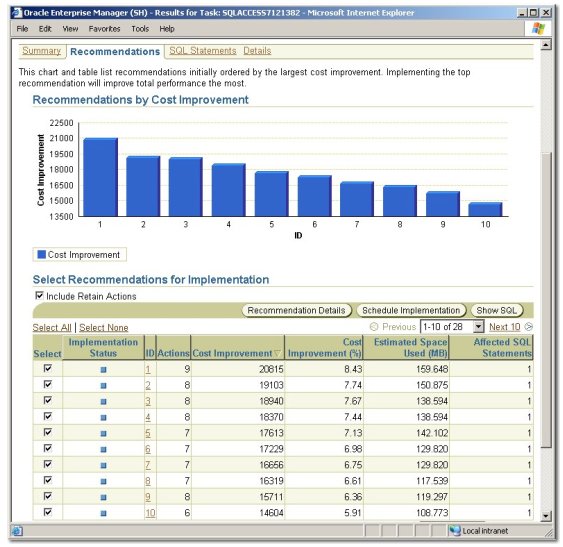
Looking at the recommendations individually, they were all for materialized views (they could have been indexes) against the SALES and dimension tables, together with the required materialized view logs.
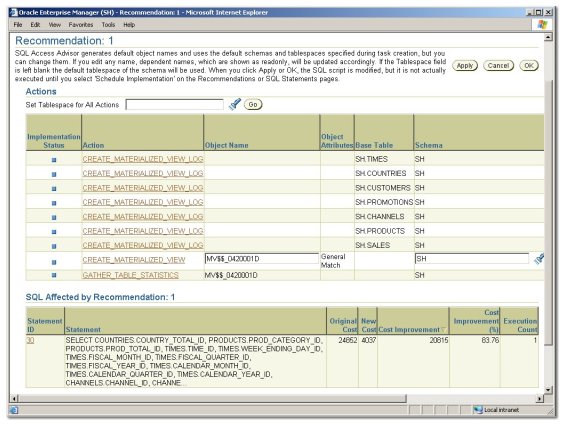
Now my thinking now is that this selection - 28 of them - is pretty good seeing as we were looking to check the performance of an analytic workspace compared to a number of materialized views, and to a single hierarchical materialized view using GROUPING SETS. I therefore turned the recommendations into a script which you can download here (there's a lot of MV creation commands in there).
Now comes the next bit - where I have to create a summary for the SH_ODM schema, but using a materialized view using GROUPING SETS to put all the aggregations into a single summary table. I did a bit of too-ing and fro-ing with David Aldridge on this one, and I did originally plan to have the DBMS_ODM procedure create it for me, but it was so much work creating the required CWM2 OLAP metadata that I couldn't imagine a real-life DBA doing this, so I created it manually myself. The script is here, but the interesting part, where we create the single materialized view using GROUPING SETS, is here (I've edited it to remove all but a couple of the 28 grouping sets)
CREATE MATERIALIZED VIEW "SH_ODM"."MV$SALES_HMV" BUILD IMMEDIATE REFRESH FORCE ON DEMAND ENABLE QUERY REWRITE AS SELECT CU.CUST_TOTAL_ID C1 , CU.CUST_STATE_PROVINCE_ID C2 , CU.CUST_CITY_ID C3 , CU.COUNTRY_ID C4 , CT.COUNTRY_TOTAL_ID C5 , CT.COUNTRY_REGION_ID C6 , CT.COUNTRY_SUBREGION_ID C7 , S.CUST_ID C8 , PM.PROMO_TOTAL_ID C9 , PM.PROMO_CATEGORY_ID C10 , PM.PROMO_SUBCATEGORY_ID C11 , S.PROMO_ID C12 , CH.CHANNEL_TOTAL_ID C13 , CH.CHANNEL_CLASS_ID C14 , PD.PROD_CATEGORY_ID C15 , PD.PROD_SUBCATEGORY_ID C16 , S.PROD_ID C17 , T.CALENDAR_YEAR_ID C18 , T.CALENDAR_QUARTER_ID C19 , T.CALENDAR_MONTH_ID C20 , S.TIME_ID C21 , COUNT(*) M1 , SUM(S.QUANTITY_SOLD) QUANTITY_SOLD , SUM(S.AMOUNT_SOLD) AMOUNT_SOLD , COUNT(S.QUANTITY_SOLD) C_QUANTITY_SOLD , COUNT(S.AMOUNT_SOLD) C_AMOUNT_SOLD FROM SH_ODM.CUSTOMERS CU , SH_ODM.PROMOTIONS PM , SH_ODM.CHANNELS CH , SH_ODM.PRODUCTS PD , SH_ODM.TIMES T , SH_ODM.SALES S , SH_ODM.COUNTRIES CT WHERE S.PROMO_ID = PM.PROMO_ID AND S.CHANNEL_ID = CH.CHANNEL_ID AND S.CUST_ID = CU.CUST_ID AND S.PROD_ID = PD.PROD_ID AND S.TIME_ID = T.TIME_ID AND CU.COUNTRY_ID = CT.COUNTRY_ID GROUP BY GROUPING SETS ( ( CU.CUST_TOTAL_ID , PM.PROMO_TOTAL_ID , CH.CHANNEL_TOTAL_ID , CH.CHANNEL_CLASS_ID , PD.PROD_TOTAL_ID , PD.PROD_CATEGORY_ID , PD.PROD_SUBCATEGORY_ID , S.CHANNEL_ID , S.PROD_ID) , ( CT.COUNTRY_TOTAL_ID , CT.COUNTRY_REGION_ID , CT.COUNTRY_SUBREGION_ID , CU.COUNTRY_ID , PM.PROMO_TOTAL_ID , CH.CHANNEL_TOTAL_ID , CH.CHANNEL_CLASS_ID , PD.PROD_TOTAL_ID , PD.PROD_CATEGORY_ID , S.CHANNEL_ID) , ... edited to remove 25 other grouping sets( CT.COUNTRY_TOTAL_ID
, PM.PROMO_TOTAL_ID
, CH.CHANNEL_TOTAL_ID
, CH.CHANNEL_CLASS_ID
, PD.PROD_TOTAL_ID
, PD.PROD_CATEGORY_ID
, S.CHANNEL_ID)
);begin
dbms_stats.gather_table_stats('"SH_ODM"','"MV$SALES_HMV"',NULL,dbms_stats.auto_sample_size);
end;
/
The idea being that I created a materialized view containing a superset of all the columns in the 28 individual materialized views, and put a grouping set at the end of the statement for each of the GROUP BYs in the individual materialized views - which should, in theory, create me a materialized view containing every aggregation performed by the individual MVs.
Unfortunately, I couldn't get the MV to fast refresh - when I create it with REFRESH FAST I get the error "cannot create a fast refresh materialized view from a complex query" which I guess is down to the grouping sets - I'll have to check this out later.
So, the stage I'm at now is that I've written the code to do the initial load - although I'll need to amend this to load just the first 100k rows from the SH.SALES table - and the initial aggregation, on the one hand using 28 materialized views recommended by the SQL Access Advisor, on the other using a single materialized view created using GROUP BY ... GROUPING SETS, but containing the same set of aggregates. The next stage now is to create the script to generate the analytic workspace. If you want to grab the scripts, there here.