Profiling and Cleansing Data Using OWB “Paris”
I was working today with the latest beta release of OWB "Paris" and looking in particular at the new data profiling and cleansing features. Data Profiling is one of the major new features in Paris, and what particularly caught my eye was the ability of the tool to automatically build correction mappings for data that needs cleaning up. I think I've pretty much worked out how the feature works, and therefore it's probably worth making a note here how the process flows together with some initial observations (based on the beta release, of course the final product might be a bit different).
The scenario goes like this: You have a schema containing source data for the data warehouse, and you suspect that the data might need cleansing before it gets loaded into the warehouse for analysis. In the past you'd run a series of hand-crafted scripts to profile the data (look for the range of distinct values, report on the metadata, calculate aggregate values and so forth) but with Paris you can automate this process using the Data Profiling feature.
When you create a data profile, you point the profiler within Paris to the schema you wish to profile, select the objects to profile and the types of profile you want to carry out (attribute analysis, referential analysis and/or custom analysis). Paris then creates a schema (OWB_PRF) to hold the results of the profiling, and kicks of an asynchronous job to go and get the profile results. When it's finished, you can then access the Data Profile Editor and view the results, like this:
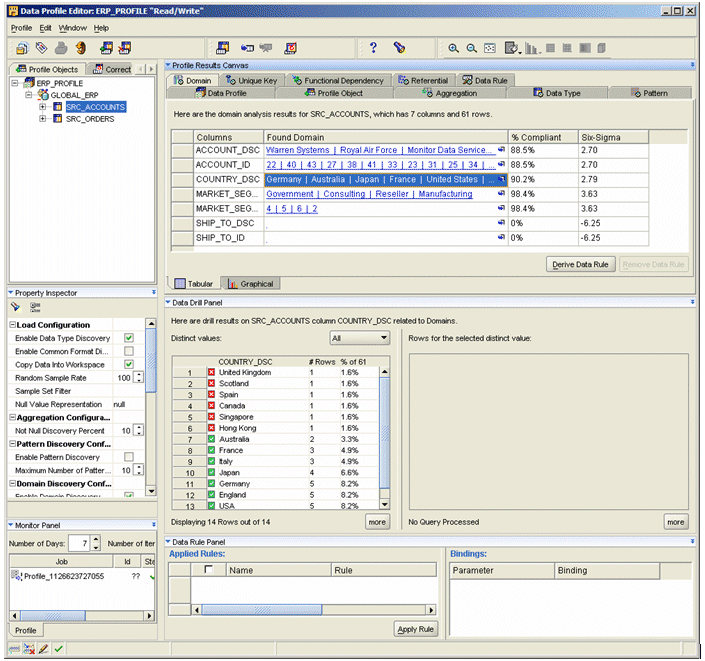
In the example I put together today, the COUNTRY_DSC field in the SRC_ACCOUNTS table contains data that I think I might need to clean up. The first step with this is to switch to the Domain tab for the Profile Results Canvas, which tells me that it has detected a domain for COUNTRY_DSC that contains Germany, Australia, Japan, France, United States, England, USA and Italy. The data within the column is 90.2% compliant with the domain, meaning that just under 10% of the rows have values outside the domain. Looking down at the Data Drill Panel, the values that contain green ticks are the ones that it considers part of the domain (basically any value that occurs more than once) and the ones with red crosses are considered outside the domain.
With our data, the correction that I'm looking to make is to change all the occurrences of England, Scotland, Wales and Northern Ireland to United Kingdom. What I want to do therefore is to take the suggested domain that the Data Profiler has come up with, use this as the basis for a data rule (excluding England, Scotland Wales and N.I. and including United Kingdom and the other countries with just one occurrence) and then take this data rule and use it to build a correction.
The first step therefore is to make sure the COUNTRY_DSC field is highlighted in the Profile Results Canvas, then press the Derive Data Rule button to put together a candidate data rule based on the domain that the Profiler has detected. You can then deselect those values that you want to be outside of the domain, select those you want to include in it, and add any other values (in my case, "Not Known") that you wish to manually add.
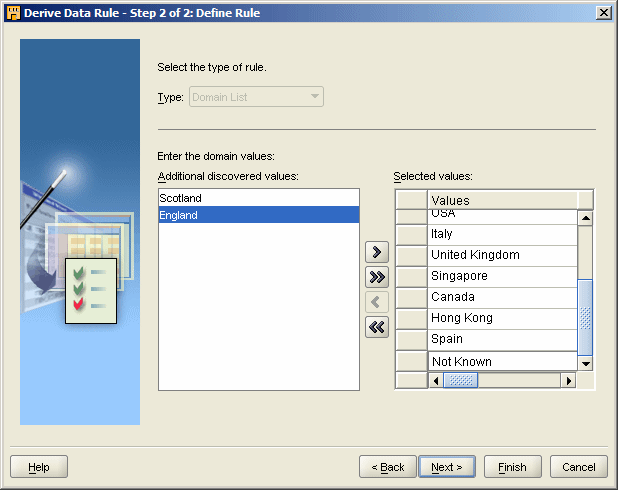
This Data Rule then becomes an object in the Project tree that you can then apply to multiple columns within tables. For our purposes though, we need to apply the data rule to the COUNTRY_DSC column of the SRC_ACCOUNTS table.
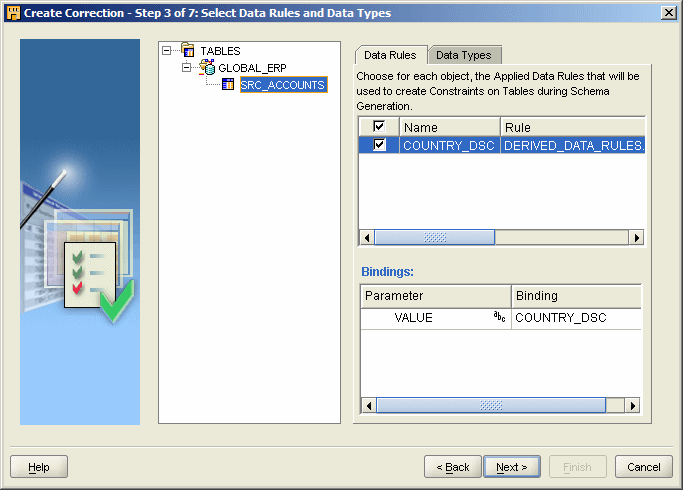
The next step is to go and create the correction. To do this, select Create Correction from the Profile menu, and select another module which will contain the corrected tables, and the mappings used to create the corrections. This module should point through to a schema that was previously registered as a Target Schema, so that OWB can create objects within it. In my case, the module was called GLOBAL_STG. You then need to select the objects that will be corrected - in our case, SRC_ACCOUNTS. Note that whilst you can select external tables, views or materialized views for correction as well as tables, the corrected version will always be a table.

Then, when the table for correction has been selected, you need to select the data rules that will apply to the table of corrected data - this data rule translates to a check constraint on the table that ensures that only values that are allowed by the rule (a.k.a. domain) will be allowed in the column. Note that this check constraint only gets put on the corrected table, not the original source one.
Now comes the interesting bit. Once the data rule has been selected, you need to specify the correction method. To do this, you need to specify two things: the Action (cleanse, ignore, report) and the Cleanse Strategy (remove, similarity match, soundex match and custom).
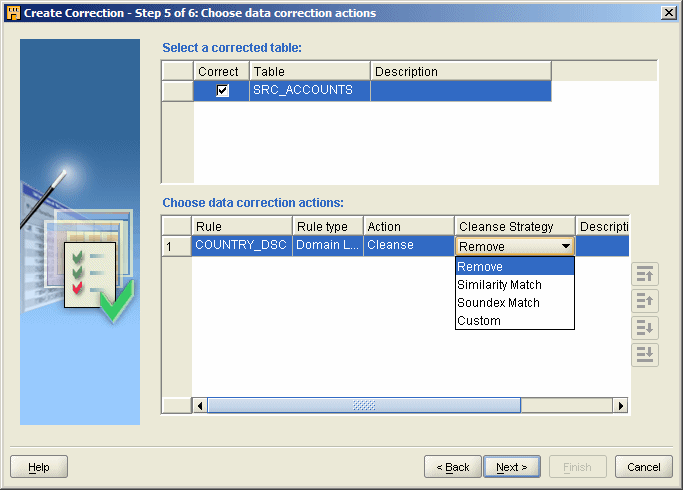
In our case we want the action to be Cleanse, but what about the Cleanse Strategy. The docs are pretty vague on this at the moment, but I had a chat with Nick Goodman and it looks like the options translate to the following:
-
Remove - simple, just deletes the column value so that the offending entry is removed. I haven't tested this though, so there is the chance that it could in fact remove the entire row rather than just NULL the column.
- n="left">Similarity Match, Soundex Match - again, not tested, but my take on this is that it will change the column value to the domain value that it most closely matches,
-
Custom - allows you to write custom code to make the correction. This is what we're going to use.
Now the correction as been specified, you can take a look at the new correction module that's been created, and the objects that are inside it.

From this you can see that the Correction Wizard has created a number of objects:
-
A mapping to implement the correction
- n="left">A function to implement the Custom cleansing process that we requested, and
-
Four tables: SRC_ACCOUNTS, which will contain the corrected version of SRC_ACCOUNTS from the source module, and other tables that will contain intermediate results from the correction process.
To do this, the code needs to be added to the CUSTOM_1 function, which has COUNTRY_DSC already defined for it as the input parameter. The code used to implement the function is pretty simple and looked like this (remember that only data that needs correction will pass through this, not all records):
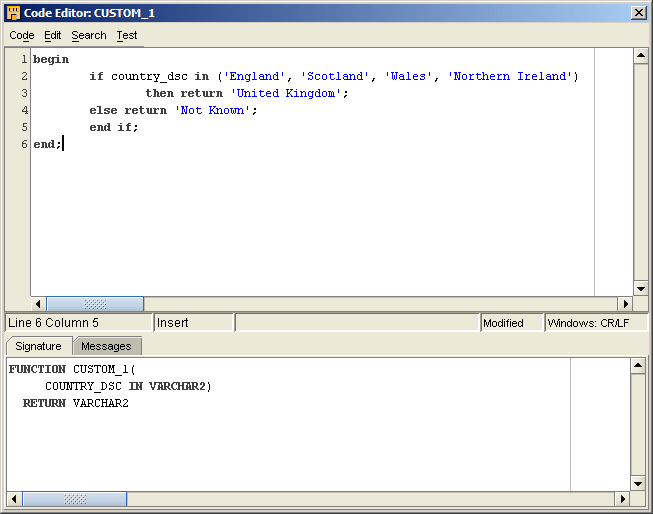
You can also take a look at the mapping that the Correction Wizard has generated to implement the correction:
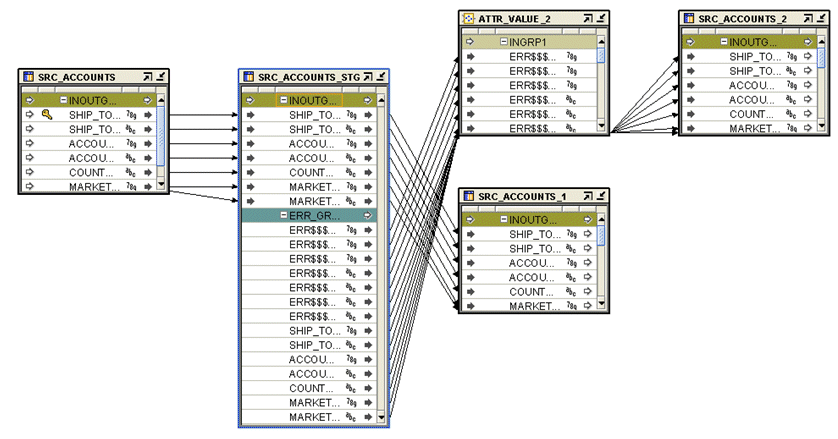
Working through the mapping, what appears to be going on here is that the first table, SRC_MAPPING is the table from the GLOBAL_SRC source module that will subsequently be corrected by this mapping. The SRC_ACCOUNTS_STAGING table is a copy of SRC_ACCOUNTS with the data rule attached, and note also the Error Group underneath it - this translates into another table that will contain the rows that fail the data rule we've specified, i.e. the ones that fail the check constraint.
The SRC_ACCOUNTS_1 and SRC_ACCOUNTS_2 tables are in fact aliases for the SRC_ACCOUNTS table within the GLOBAL_STG module, with the valid rows from SRC_ACCOUNTS_STG inserted into the SRC_ACCOUNTS_1 alias, and the records from the error group being passed through the ATTR_VALUE_2 pluggable mapping, corrected, and then inserted into the SRC_ACCOUNTS_2 alias.
Still with me? The ATTR_VALUE_2 pluggable mapping can itself be examined, using the View Child Graph toolbar button. When it's expanded out, it looks like this:
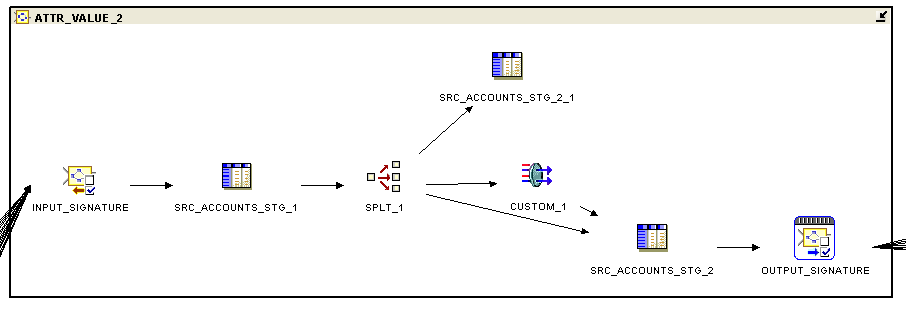
This sub-mapping contains an operator on the left-hand side, SRC_ACCOUNTS_STG_1, which is bound to the SRC_ACCOUNTS_STG_T1 table shown in the project tree earlier, and then splits the rows into two table operators, both of which are bound to the SRC_ACCOUNTS_STG_T2 table, with the second one using the custom PL/SQL transformation we set up earlier to convert all the incorrect country names to correct ones. I'm not sure what the purpose of the split is - I can't see what the split logic is from examining the operator, and both operators are bound to the same physical table. If I work it out later I'll post an update.
If we want to implement this correction, the first thing to do then is to deploy all of the objects (tables, mappings) in the Correction Schema, GLOBAL_STG, to the database. Once this is done, the following tables were created in the Correction Schema:
SQL> select table_name from user_tables; TABLE_NAME ------------------------------ WB_RT_VERSION_FLAG SRC_ACCOUNTS_STG_ERR SRC_ACCOUNTS_STG SRC_ACCOUNTS SRC_ACCOUNTS_ERR SRC_ACCOUNTS_STG_T2 SRC_ACCOUNTS_STG_T1 7 rows selected. SQL>
Note that this list includes the additional tables used by the pluggable mapping, not just those listed in the project tree.
Before the mapping is executed, you can take a look at how the data is held in the original SRC_ACCOUNTS table:
SQL> set pagesize 400 SQL> conn global_src/password@ora10g Connected. SQL> select country_dsc, count(*) from src_accounts 2 group by country_dsc; COUNTRY_DSC COUNT(*) ------------------------------ ---------- United Kingdom 1 Scotland 1 United States 28 Germany 5 France 3 England 5 USA 5 Spain 1 Australia 2 Canada 1 Singapore 1 Italy 3 Japan 4 Hong Kong 1 14 rows selected.
Now, when the mapping is executed, the corrected version of SRC_ACCOUNTS looks like this:
SQL> conn global_stg/password@ora10g Connected. SQL> select country_dsc, count(*) from src_accounts 2 group by country_dsc; COUNTRY_DSC COUNT(*) -------------- ---------- United Kingdom 7 United States 28 Germany 5 France 3 USA 5 Spain 1 Australia 2 Canada 1 Singapore 1 Italy 3 Japan 4 Hong Kong 1 12 rows selected. SQL>
You can also examine the other tables in the correction schema for details of the rows that were corrected, the data rules that were broken and so forth.
So, how does this method of correcting data differ from a simple mapping you put together yourself, using the same custom PL/SQL function to correct the data? Well in some respects, it's a lot more complicated and has a lot more things that can go wrong, and it took me the best part of a couple of days to work out how it all fits together. From working with it though, I can see two benefits from this.
Firstly, it creates metadata and graphical descriptions around your data cleansing processes, so that data cleansing is a distinct part of your ETL, your data clearly moves from dirty to cleansed, and it's much easier for a second person to work out what this part of the ETL process is for, compared to data cleansing being carried out "ad-hoc" as part of a general data movement from source to target.
Secondly (and I haven't had a chance to play around with this yet) the ability to match dirty data to it's correct form, using the soundex and similarity transformations, sounds a good new way of correcting spelling mistakes and mis-keyed customer data. One thing I haven't seen in it is the ability to combine this with the match-merge functionality (unless the similarity/soundex functions are match-merge under a different badge) but if these two functions were combined, it'd be a pretty good way of cleansing, deduplicating and householding customer data as part of the data profiling process.
Finally, one drawback that Nick Goodman actually pointed out to me, is that as the Correct Wizard is essentially a mapping generator that works off of your supplied parameters, if you need to change the correction in any way (perhaps switch from soundex to similarity, or to remove or custom cleansing) you've pretty much got to delete the mapping, all the tables it generated (including those used by the pluggable mapping) and do it all again. It would be good if you could just edit the correction as a whole, change the definition and OWB would make the changes, but without that you're pretty much stuck with deleting it and starting again.