Aggregate Navigation using Oracle BI Server
In this example I'm going to show you how to create an aggregate table, register it with the Oracle BI Server, and have Oracle Answers and Dashboard use it to speed up queries. Oracle BI server lets you register aggregate (summary) tables that contain the precomputed sums, averages and so on for a fact table, which it then uses in preference to rolling up the detail-level fact table if this would speed up a query. I was shown how to do this by Kurt Wolff so all credit to him, and in this instance I'll be working with the source tables used in the Global Sample Schema.
The UNITS_FACT table in the Global Sample schema has around 220k rows in it, holding sales data at the month, item, ship to and channel level.
SQL> select count(*) from sales_fact;
COUNT(*)
----------
222589
What I'd like to do is create an aggregate table, where I roll the data up to the product family, and customer region, level. I'll leave channel as the detail level, and do the same for month, as the data is sparse by the time dimension - customers don't generally order every day each month, which means aggregating by this level won't really compress the aggregate any further.
I create the aggregate table using a CREATE TABLE ... AS SELECT statement.
SQL> create table agg_sales_fact
2 as
3 select p.family_id
4 , cu.region_id
5 , ch.channel_id
6 , t.month_id
7 , sum(s.units) as units
8 , sum(s.sales) as sales
9 , sum(s.cost) as cost
10 from product_dim p
11 , customer_dim cu
12 , channel_dim ch
13 , time_dim t
14 , sales_fact s
15 where s.ship_to_id = cu.ship_to_id
16 and s.item_id = p.item_id
17 and s.channel_id = ch.channel_id
18 and s.month_id = t.month_id
19 group by p.family_id
20 , cu.region_id
21 , ch.channel_id
22 , t.month_id
23 /
Table created.SQL> select count(*) from agg_sales_fact;
COUNT(*)
----------
5291
That's better; the summary table is just 2% of the size of the detail-level table.To go with the aggregate table, I create cut-down versions of the PRODUCT_DIM and CUSTOMER_DIM dimension tables, using just the levels and above referenced by the aggregate table.
SQL> create table agg_customer_dim
2 as
3 select distinct region_id
4 , region_dsc
5 , total_customer_id
6 , total_customer_dsc
7 from customer_dim
8 /
Table created.
Now the aggregate fact table and dimensions have been created, I then import them into the physical layer of the semantic model...
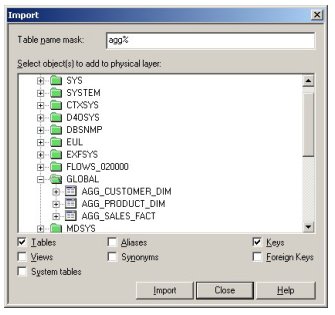
... create keys on the relevant columns ...
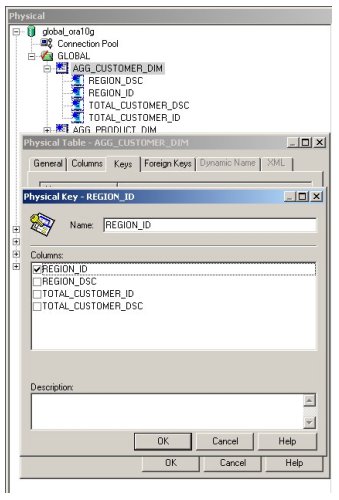
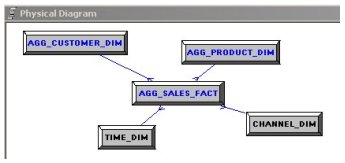
... use the physical diagrammer to create foreign key relationships between the aggregate fact table, the aggregate dimension tables and the existing detail-level TIME_DIM and CHANNEL_DIM dimension tables ...
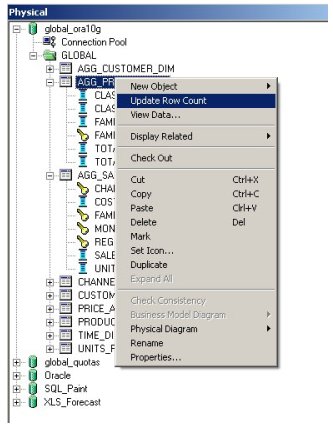
... and then finally, update the row counts on the new tables.
We're now at the point where we can map these aggregate tables to the existing logical tables in the business model layer.
The way we do this is similar to the way I mapped an Excel spreadsheet in a few weeks ago; you identify the existing logical tables in the business model that have columns that correspond to the incoming data, and then drag the columns you want to match on over from the new, physical table on top of the existing logical columns you want to "join" on. This creates a new logical table source for the logical table, and tells the BI Server that in our instance, the region description, and the family and class descriptions, can now also be found in our aggregate dimension tables.
We then do the same for the unit column, but instead of - as we did with the Excel source - adding it as a new column the fact table, we just drop it on top of the existing units measure.
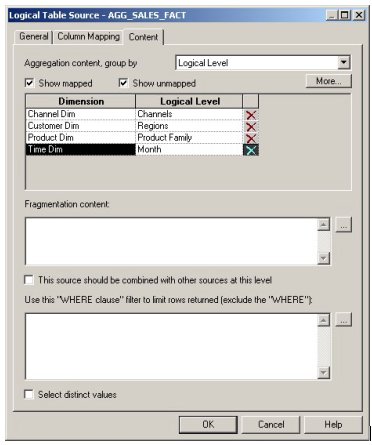
The final step is to tell the BI Server that this new data source for the units measure, is only valid at the month, channel, product family and customer region level.
Now, when a query comes in against the units measure at the product class and customer region level, the BI Server will use the AGG_SALES_FACT aggregate table instead of the UNITS_FACT table, as it's row count is so much less than the detail-level table (5k rows rather than 200k).
To test this out, I run a query to return a crosstab at the detail level, like this:
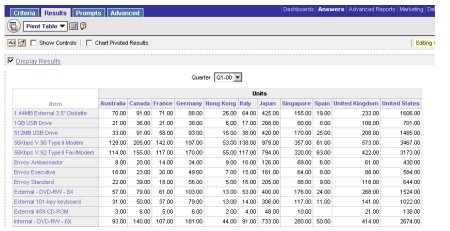
Checking the query log, I see that the detail-level tables are being used in the physical SQL.
select D1.c1 as c1,
D1.c2 as c2,
D1.c3 as c3,
D1.c4 as c4
from
(select sum(T682.UNITS) as c1,
T625.ITEM_DSC as c2,
T645.QUARTER_DSC as c3,
T591.WAREHOUSE_DSC as c4
from
GLOBAL.TIME_DIM T645,
GLOBAL.PRODUCT_DIM T625
GLOBAL.CUSTOMER_DIM T591,
GLOBAL.UNITS_FACT T682
where ( T645.MONTH_ID = T682.MONTH_ID and
T591.SHIP_TO_ID = T682.SHIP_TO_ID and
T625.ITEM_ID = T682.ITEM_ID )
group by T591.WAREHOUSE_DSC,
T625.ITEM_DSC, T645.QUARTER_DSC
) D1
order by c2, c3, c4
Then running a query at the higher level, which corresponds to the aggregate table, I get the following results (rather quickly, I note)...
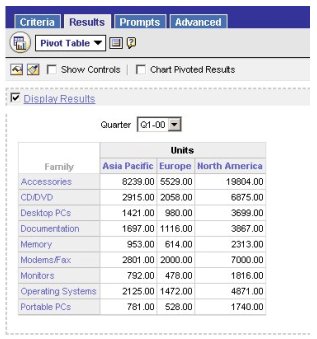
... and, checking the physical SQL issued, I see the aggregate tables being used instead.
select D1.c1 as c1,
D1.c2 as c2,
D1.c3 as c3,
D1.c4 as c4
from
(select sum(T2386.UNITS) as c1,
T645.QUARTER_DSC as c2,
T2374.REGION_DSC as c3,
T2379.FAMILY_DSC as c4
from
GLOBAL.TIME_DIM T645,
GLOBAL.AGG_PRODUCT_DIM T2379,
GLOBAL.AGG_CUSTOMER_DIM T2374,
GLOBAL.AGG_SALES_FACT T2386
where ( T2379.FAMILY_ID = T2386.FAMILY_ID
and T645.MONTH_ID = T2386.MONTH_ID
and T2374.REGION_ID = T2386.REGION_ID )
group by T645.QUARTER_DSC, T2374.REGION_DSC, T2379.FAMILY_DSC
) D1
order by c2, c3, c4
Not bad. Later on, I run other queries at higher levels of aggregation, and see that the aggregates are still being used.
So, I guess the obvious question here is whether you'd use this, when you have materialized views and query rewrite already in place? Well, I guess this was a feature Siebel put into the BI Server for databases that didn't have query rewrite, and therefore Siebel Analytics needed to handle aggregate navigation for them. Even if you've got an Oracle Enterprise Edition database, you might still want to use this if the intricacies of Oracle summary management are a bit too much for you.
One thing that this would be useful for though, is where an aggregate is stored in one database (possibly an OLAP server?), and the detail in another - using this feature the measure seems seamless to the user, but under the covers two separate databases are being used to return the data. Looking to the future, this ability to store aggregates remotely is being used by a future version of the BI Server, which will come with a utility that automatically creates aggregates for you based on previous query response times, and stores these aggregates on whatever database server is handy, mapping the aggregates back to the existing measures and subsequently speeding up queries against them that require summarized data. Quite a useful feature.