Moving Global Electronics Data using Sunopsis
I'm writing this whilst sitting in the departure lounge at Vienna Airport, and as my flight's been delayed, I thought I'd do the next posting in my "Sunopsis on Oracle" writeup. The other week, I worked through the demo that comes with Sunopsis Data Conductor and said at the time I'd try the software out again with some Oracle data; and last night in the hotel I managed to get it up and running with the Global Sample Schema. My objectives with this were twofold; firstly, see how well the software worked outside of a scripted demo environment, and secondly, to have a look at the quality of the SQL and PL/SQL code it generated.
As I mentioned one of the previous postings on Sunopsis, connecting the environment to an Oracle database was fairly straightforward. Using the "Topology" application, I registered two "Data Servers"; one pointing towards the source data in the Global Sample Schema (GLOBAL), and the other pointing towards the target schema (GLOBAL_SUNOP_DW_TARGET). Both were on the same Oracle database on the same Oracle server, and I was interested to see whether it brought the schemas together using database links, or whether it worked out they were on the same database and just selected across schemas - the latter being more efficient than the former.
Anyway, I registered the Data Servers, and got to the point where I specified the Schema and the Work Schema. In the special situation where you connect to Oracle data, you can nominate the Schema (the schema where the data will be taken from, or copied to) and the Work Schema (the one where all the temporary objects used for the ETL process will be placed).
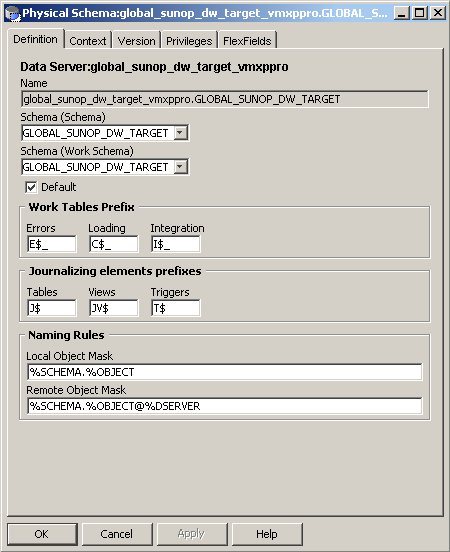
I just used the same user name for both entries, which turned out to be a mistake later on, as even in the source schemas, Sunopsis creates views, synonyms and so on which should really be kept away from the source data. For me, the ETL process still worked, but next time I'll actually create a separate user in the source and target databases to register as Work Schemas, as this will make it all a bit tidier.
Anyway, once I registered the sources and targets, I used the Designer application to reverse-engineer the source and target objects into the tool.
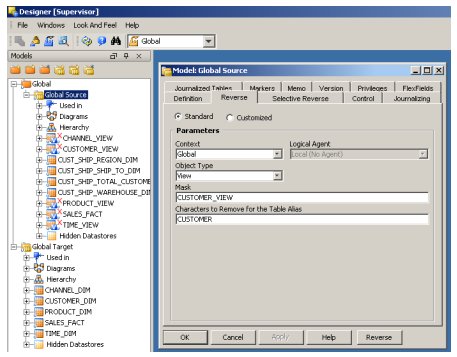
At this point one of the limitations of the tool became apparent: it's not really a data modelling tool, you can't create dimensions, or cubes, or partitioned tables, or any other proper "data warehouse" structures using Data Conductor. If you think about it, it makes sense as Data Conductor covers all database platforms, not just Oracle, and it would be impracticable to for it to contain an Oracle dimensional data modeller, a Teradata data modeller, an Essbase data modeller and so on, buit for those of us used to Warehouse Builder, it does mean that we'll have to design our objects outside of the tool, perhaps using OWB or maybe Oracle Designer, and reverse-engineer them into the tool. Interestingly though, once you bring objects into the tool (which are then referred to as "datastores" from then on), you say whether the object is a fact table, a dimension or a slowly-changing dimension - I didn't look into this too much but it's obviously going to be used somewhere else in the special case of loading dimensional objects, I'll have to have a poke around later on and see what this signifies.
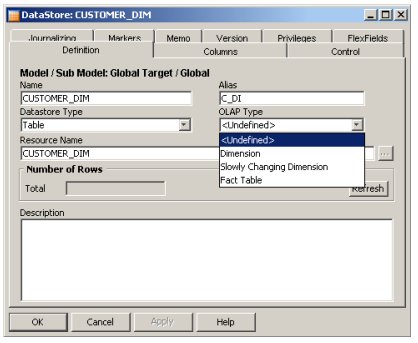
One problem I did have later on was with the "Alias" settings for the imported tables; in a couple of instances, the aliases started with an underscore ("_"), which weren't valid view or table names when Sunopsis tried to create them later - I got around this by going back to the datastore definitions and putting a letter in front of the alias names, but until I worked this out it caught me out a couple of times.
Anyway, once the source and target datastores were imported, I set about putting the interfaces (mappings) together. This was pretty straightforward, with the first step being to define the business rules - the column to column mappings - and the second step being to decide on the method by which the data was copied.
Defining the business rules was pretty easy, even for those source that required a number of table joins.
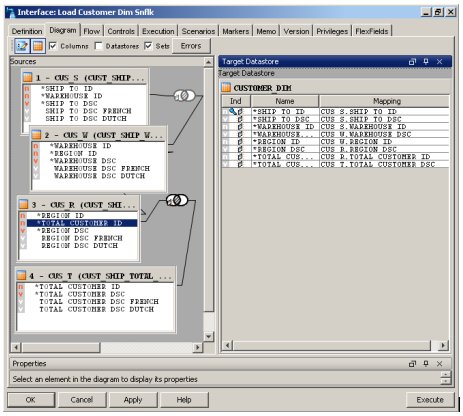
As I mentioned in one of the previous postings on Sunopsis, this ETL tool splits the data mapping into the business rules (which columns map to where) and the implementation, which is specific to the target platform and can encompass techniques such as change data capture, slowly changing dimensions, incremental loads, merge (in the case of an Oracle target) and PL/SQL row-by-row loading (ditto). For this particular mapping, I moved on to the Flow tab, where I specified the technicalities of how the data is loaded.
The data loading is actually specified in two parts; firstly, how the data is loaded, and secondly, how it is integrated. The load method is specified by choosing an "LKM" (Load Knowledge Module), whilst the integration is specified by choosing an "IKM" (an Integration Knowledge Module". Various LKMs and IKMs are provided by Sunopsis for each platform, and it's possible to extend this by writing your own.
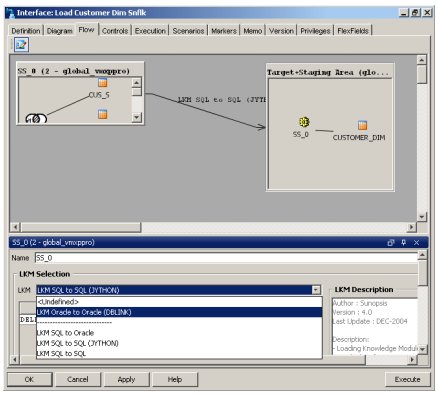
For loading data onto an Oracle target, you've got four LKMs provided by default:
- LKM Oracle to Oracle (DBLink), which brings data across via a database link - the option I chose
- LKM SQL to Oracle, which loads data from any SQL92-compliant database, and moves the data across via the Sunopsis Agent, a sort of multi-platform Control Center Service, into an Oracle temporary table, from which it will be later integrated into the target datastore
- LKM SQL to SQL, which does the same but between any two SQL92 databases
- LKM SQL to SQL (JYTHON), which does the same but through the use of a Jython script rather than the Sunopsis Agent
For integrating the data, you've got a number of IKMs you can use with an Oracle target:
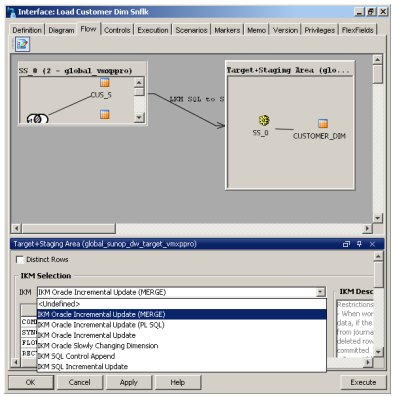
- IKM Oracle Incremental Update (MERGE), which relies on a primary key being on the target and uses the MERGE SQL command
- IKM Oracle Incremental Update (PL/SQL), the same but row-by-row using PL/SQL
- IKM Oracle Incremental Update, which does the same but with individual INSERT and UPDATE steps
- IKM Slowly Changing Dimension
- IKM SQL Control Append, and
- IKM SQL Incremental Update - the last three of which I need to find out more on how they work.
So, to go back to the question, what sort of Oracle code does Sunopsis generate when extracting and loading data. Well to be honest, it's only going to be as good or as bad as the knowledge modules, but it'd be interesting to see how well it performs out of the box, so I built interfaces for all the dimension tables and fact tables in the Global Sample Schema, then ran them and had a look at the code. Pulling at the interfaces together into a package, and then a scenario (a published version of a package with a unique version number), I checked it all looked ok...
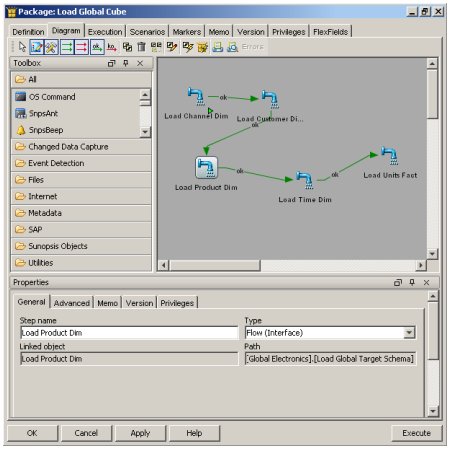
... and then pressed the "Execute" button. Starting up the Operator applicatiion, I took a look at the execution status of the individual interfaces, which looked fine.
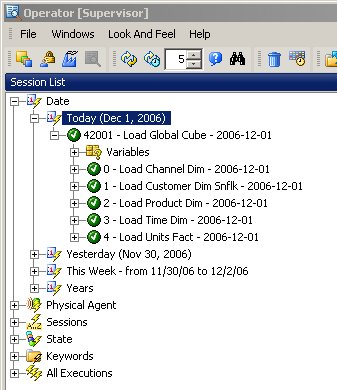
Taking a look in more detail at one of the interface runs, you can see the steps the tool performs to extract and load the data.

Then, doubling-clicking on the "52 - Integration - Merge Rows" step, you can see the SQL that the tool is generating:

A straightforward MERGE into the target table.
For the Channel dimension load, I chose the "IKM Oracle Incremental Update" integration method, and this time it split the load into several steps, presumably for when the MERGE command isn't available. You can take a look at an excerpt from the code here, and bear in mind that it uses staging tables and view to move the data around, hence the funny table names
So you can see what's going on here. Sunopsis have written, presumably using some form of templating system, a number of ways of getting data into a target platform, which you can choose from depending on the version you're deploying to, what you're trying to achieve and what features you want to use.
The PL/SQL load follows a similar approach (view code here)
So in terms of the question - does it write good Oracle code; well, looking at the PL/SQL implementation, you could probably improve by using BULK COLLECT and FORALL, but that's not really the point - the system is designed to be extensible and you could write your own Integration Knowledge Module to use these features if you really wanted them.
And of course - all of this works across all platforms, not just Oracle. Looking through the list of IKMs, LKMs, JKMs (Journal Knowledge Modules, used for setting up change data capture) you've got the equivalent for DB2, Sybase and so on, plus things like Logminer reads for Oracle and so forth. So it certainly looks fairly interesting.
So now, I'm at the point where I can more or less do what I normally do with Oracle Warehouse Builder. Now this is only scratching the surface really; so far from poking around with the tool there's features for handling data issues and error handling, you can publish to and read from Web Services, load to and from files and so on. For the time being though, I'm going to leave it at that and get cracking on with the book, but if anyone else has a crack with the tool, let me know and we can compare notes.