Running OWB10gR2 in a Production Environment
I've been giving some thought recently to how Oracle Warehouse Builder 10gR2 is configured and used when working in a production environment. Most people who "kick the tires" with OWB10gR2 do so on their own laptop, or on their own pc, with a local database on which the repository, source tables and target environment are all held. In real life though, things are often a bit more complicated:
- In production, you often have your source data on one or more databases, your repository on another, and the target data warehouse environment is usually on another box altogether.
- You'll want to use change management, so that the introduction of new data, modifications to data warehouse structures and alterations of mappings is done in a controlled, planned way.
- Objects, mappings and other project elements will need to be versioned, and you'll need to be able to roll back to previous project states if things go wrong with an upgrade.
- You'll usually have test and production environments, instead of just dev.
- There'll be more than just you as a developer, and you'll therefore want some sort of security and scoping of project elements
- You'll need to ensure you're licensed properly - a tricky area since parts of OWB are now chargeable on a per-CPU basis.
So, starting off with the first point - you'll be dealing with more than one database. In real life, and in the book I'm writing, you often want to have your repository and the target data warehouse held on different databases, often on different servers. This might be because your OWB repository is on a database running in ARCHIVELOG mode, as the repository is effectively an OLTP application that you need to be able to recover to the last committed transaction. Oracle recommends configuring the database holding your repository with an 8K block size, whilst your data warehouse database might be running in NOARCHIVELOG mode, with a 16K block size. The obvious thing is to put the repository and data warehouse on their own databases, as shown in the diagram below:
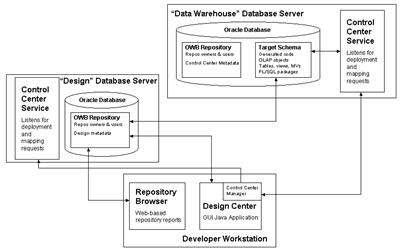
Now when you start working with multiple Control Centers, you need to use a new feature called Multi-Configurations in order to work with Control Centers other than the default one that's created with your main repository. (UPDATE: No you don't actually, as pointed out in the comments for this article, and in this subsequent blog post where I show how this can be done with just standard, ETL Core features. Multi-Configuration is still useful when handling more than one Control Center, but it's not essential. Bear that in mind when reading the rest of this posting, and check out the subsequent posting for how I handle this requirement now.) Multi-Configurations are an Enterprise ETL feature, which means to me that you can't run mappings on databases other than the one that contains your design metadata unless you pony up for the $10k per CPU license fee, and that's on both the (presumably small) repository database and the (presumably large, with lots of CPUs) data warehouse database. (UPDATE: Again, wrong, you can switch between more than one control center using standard features; see this article for more details.) Licensing aside though, what this does mean is that you need to be careful when you first set your project up, to ensure that you create all your locations, control centers and modules in the right order: (UPDATE: This is still correct)
- First of all, create your main repository as normal on the smaller of the two databases.
- Log in to the Warehouse Builder Design Center, and create any database modules that are held on this same database. The locations that get created along with the database modules will be owned by your default Control Center.
- Now, you need to create a second Configuration, give it a name, and then when prompted for the Control Center it will use, use the "New" button to create a new one on the data warehouse database.
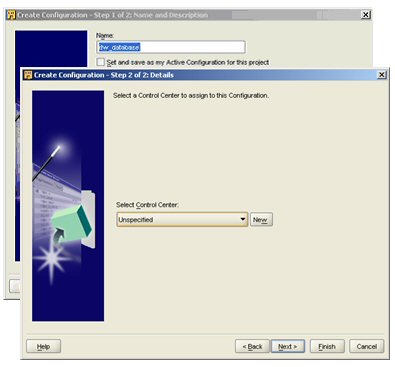
- Now, make this new configuration your active configuration.
- Next, create all the database modules that will be owned by this other Control Center whilst this other configuration is active; this ensures the right Control Center owns the right locations.
- When you finish creating these modules and locations, switch back to the default Control Center. Create your project as normal, but when you need to deploy and running objects and mappings to the locations owned by the other Control Center, make sure you switch beforehand to the other configuration that owns these locations.
UPDATE: You can do the same thing by registering the additional control center as above, but then switching the control center used by the DEFAULT_CONFIGURATION to this other one before registering the remote locations.
Multiple Configurations are useful for another reason as well; they allow you to associate different sets of physical attributes with your database objects. For example, you might have development, test and production environments, each with their own databases. Your development environment might just have a USERS tablespace, and you haven't licensed the partitioning option for that database. Your production environment, however, has a tablespace per objects, and you're looking to partition your fact tables into one partition per month. Using multiple configurations, you can associate different physical properties for your object, and switch between them by activating the correct configuration.So that deals with multiple databases and multiple environments, as long as each environment is running the same data model, same version of mappings and so on. But what if your development environment is further ahead that your test and production environments, and you need to keep a separate record of your project as deployed in development, compared to test and production? Well, the most practical approach I can think of is to keep with multiple configurations, but have separate repositories for each of the environments; each repository still contains references to all three configurations (to allow us to partition our tables in production, but not in development) and to promote code through dev to test to prod, you use the MDL export and import facility to move project elements between repositories. Not quite as elegant as CVS or Subversion, but it gets you there in the end.
Working with just the development environment for the time being, the question becomes: how to we control the impact of changes and modifications to the project metadata, and how do we introduce version control? In OWB10gR2, these two issues are handled by the Metadata Dependency Manager, and the Change Manager respectively.
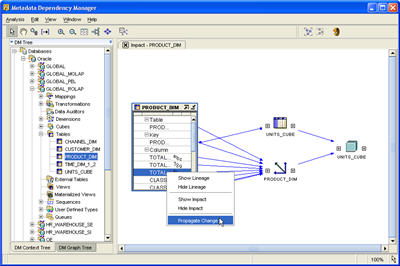
The Metadata Dependency Manager performs three functions:
- It allows you to interactively determine which objects in your project have metadata dependencies on and object - useful if you want to change an column datatype or definition, and you're wondering what other columns are loaded from it;
- It allows you to select an object and see how it was populated (known as "data lineage"), and
- If an object column has changed, you can propagate the changes through to the other objects that are dependent on it.
On to security now. In earlier versions of Warehouse Builder, you generally logged on to the Design Center as it was by using the repository owner username and password. You could set up Warehouse Builder to use existing database accounts as a login, with Warehouse Builder then presenting the user with a list of all the repositories they could connect to before starting the Design Center, but once in, there was no way of controlling what project items they could work with - all you could do was track who worked with what, and go and get them afterwards if they mucked anything up.
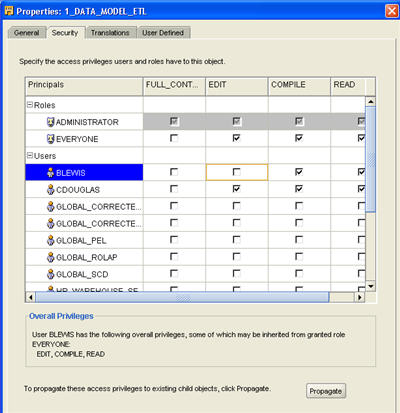
The 10g Release 2 version of OWB introduced proper access control to your Warehouse Builder projects, which is turned off by default but can be easily enabled by modifying the properties of an object, module or project. The first step is to either register existing developer database accounts, or create them from new, using the Global Explorer in the Design Center. This creates database accounts in the database that your active Control Center resides in, and registers them with Warehouse Builder, and optionally with the Control Center.

- Multiple configurations, required to access additional Control Centers, are an Enterprise ETL feature
- As are schedules, target load ordering, and for and while loops, together with notifcations and routes, in process flows
- ... and Slowly Dimension Type 2 and 3 support, and support for VARRAYs, deploying directly to a Discoverer End User Layer and transportable modules.
- Whilst all the data profiling functionality (including data rules, automatic corrections and data auditors) requires another database option, the Data Quality option at $15k per CPU.
Anyway, that's my thoughts on what's involved in running OWB10gR2 in real, multi-database environments with change and version control and code promotion between development, test and prod. An area I haven't covered is automating the whole process (including, critically, code promotion between environments and regression testing of the ETL build) using OMB*Plus, but if this sounds interesting (or if you've got some suggestions), add a comment or come along to the UKOUG Scottish SIG BI Event where I'll be presenting on the subject on March 15th.