A First Look at Oracle OLAP 11g
Now I'm on the flight over to London back from Open World, I've got a few hours spare to take a proper look at the 11g release of Oracle OLAP. In particular I'm trying to find out whether it runs ok without any show-stopper bugs, whether there are any new features in Analytic Workspace Manager, how well the Materialized View integration works, whether it's any faster to query than previous releases, and - and this is the killer question, the thing that I'm most interested in - is it a viable way to speed up slow-running relational Discoverer reports?
So, to get things set up, I installed the Windows version of Oracle 11g together with the Client CD, which has AWM11g contained within it. I copied across the relational source data from the Global schema on my 10g database (not the analytic workspace within it, just the source data), and set up the 11g Global schema with the usual connect, resource etc priviledges, together with these extra ones;
connect system/password@ora11ggrant olap_user, create materialized view, olap_xs_admin to global;
The OLAP_USER role is required in order to access the OLAP metadata in the Oracle database, whilst the CREATE MATERIALIZED VIEW role is needed in order to access the materialized view functionality now available in Oracle OLAP 11g and Analytic Workspace Manager 11g. The OLAP_XS_ADMIN role is new with 11g and, as we'll see later, is used when working with cube security in AWM.
Now, I start up Analytic Workspace Manager 11g and log in for the first time. With this new version of AWM, I'm prompted to select a "Cube Type" at the start - I can either create cubes with the 11g metadata format, or the old 10g metadata format for backwards compatibility.
This new 11g OLAP cube metadata format adds a bunch of new functionality that we'll see in a moment in AWM. What this does mean though is that tools like Discoverer Plus OLAP, Oracle Warehouse Builder and the Spreadsheet Add-in won't work yet with 11g OLAP unless you select the backwards-compatible 10g metadata format, but as I don't intend to use these tools, and instead use Discoverer relational and AWM to build my cubes, I select the 11g format.
Once I log in, one thing that's immediately noticable is that there's a whole bunch of SQL reports now available for displaying the size of AWs, the progess of jobs and so on.
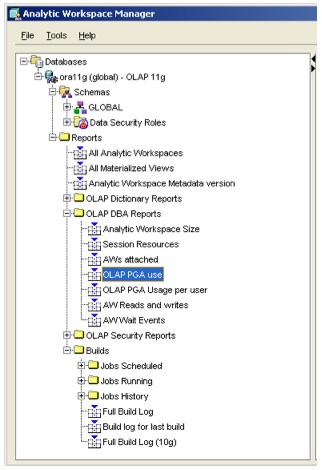
I was especially interested to note a "wait events" script as well - I don't know whether this had anything to do with it, but I suggested this to the product management team a similar time ago, I'll be interested to see what activities and waits this provides diagnostics on. If it works as it should do, it will give the same sort of insight into AW read and build activity that we currently get when working with the relational part of an Oracle data warehouse. Cool.
If you want to run the various OLAP DBA reports in AWM, you'll need to run the following script to grant the required object priviledges. Make sure you run the SQL that follows as the SYS user (not SYSTEM), once these grants are set up OK the reports run without a problem.
conn sys/password@ora11g as sysdba/* ------------------------------------------------------------------------------ /
/ Script to Allow AWM DBA Reports to run for user GLOBAL /
/ ------------------------------------------------------------------------------ */-- This script grants SELECT privileges on a series of tables and views to user GLOBAL,
-- which allows that user to run the "DBA Reports" in AWM 11g (11.1.0.6)
-- Run this script as the SYSTEM user./* Analytic Workspace Size
-------------------------------------------------- */
grant SELECT on dba_lobs to global;
grant SELECT on dba_segments to global;/* Session Resources
/* -------------------------------------------------- */
grant SELECT on v_$sesstat to global;
grant SELECT on v_$statname to global;
grant SELECT on v_$session to global;/* AWs attached
/* -------------------------------------------------- */
grant SELECT on v_$aw_olap to global;
grant SELECT on v_$aw_calc to global;
grant SELECT on v_$session to global;/* OLAP PGA use
/* -------------------------------------------------- */
grant SELECT on v_$aw_calc to global;
grant SELECT on v_$pgastat to global;/* OLAP PGA Usage per user
/* -------------------------------------------------- */
grant SELECT on v_$aw_calc to global;
grant SELECT on v_$session to global;
grant SELECT on v_$process to global;/* AW Reads and Writes
/* -------------------------------------------------- */
grant SELECT on gv_$aw_calc to global;
grant SELECT on gv_$session to global;
grant SELECT on gv_$aw_olap to global;
grant SELECT on gv_$aw_longops to global;/* AW Wait Events
/* -------------------------------------------------- */
grant SELECT on v_$active_session_history to global;
grant SELECT on v_$session to global;
grant SELECT on v_$aw_olap to global;
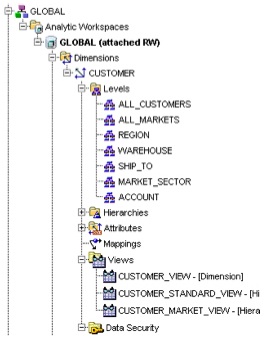
So I start off then by creating the CUSTOMER dimension in the Global model, which I create in exactly the same way as with earlier versions, starting first with the dimension, then the levels, then the hierarchies, and finally the mapping. What's new about this version though is firstly a new "Materialized View" tab within the dimension dialog, secondly a new "Views" entry under the dimension listing and thirdly an entry under the views, called "Data Security".
Clicking on the dimension itself shows the Materialized View tab, and provides a list of options and properties for refreshing the dimension using the MV refresh mechanism. Using this presents the opportunity for your regular Oracle DBAs to refresh your AWs in the same way as MVs, and the fact it's regarded as an MV in the first place opens it up to being used by the query rewrite mechanism, which is where the "speed up relational Discoverer reports" thing comes in - if we can add an AW over some relational data, and register the AW for query rewrite, it might solve the perennial problem of getting relational Discoverer reports to perform well when there's lots of data and complicated user queries.
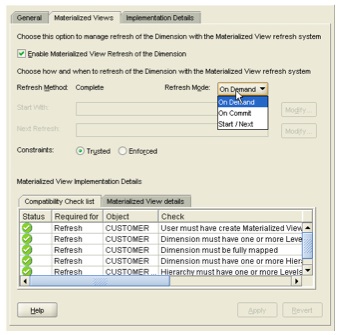
For the time being, I check the "Enable Materialized View Refresh of the Dimension" checkbox, set the refresh type to "On Commit", and then go on to create the PRODUCT, TIME and CHANNEL dimensions in the same way.
Just to check it's all working ok, I then select the option in AWM to load the CUSTOMER dimension, which brings up the usual dialog where you select the dimension(s) to load, when to run the load and so on. After selecting the option to output the build script to the filesystem, I run the load against the CUSTOMER dimension and check the build log at the end.

I haven't got an old copy of AWM to hand at the moment, but the build log output looks a little more detailed than before, in terms of the level of detail about the steps. Also, next to the LOAD SYNCH entry is a button that, when pressed, displays a log output detailing the SQL statements that were used to populate the analytic workspace - this will be useful in future when trying to track back to the particular SQL statements that were used when loading the analytic workspace.
Now, if I take a look at the script that AWM generated to build the dimension (which I handily output to the filesystem a minute ago, when generating the maintain dimension process) you can see that it's in fact the DBMS_MVIEW call that then goes on to load the dimension, as I chose to link the dimension to a materialized view.
BEGIN
DBMS_CUBE.BUILD(
'GLOBAL.CUSTOMER',
NULL,
false, -- refresh after errors
1, -- parallelism
false, -- atomic refresh
true, -- automatic order
true); -- add dimensions
END;
/
When DBMS_MVIEW.REFRESH is called in this way, it knows that the underlying MV points to an analytic workspace and triggers the normal refresh routine for that dimension, instead of running the normal relational MV refresh process.
The dimension itself looks fine:
so I move on to the other dimensions. One thing I notice when maintaining the other dimensions is an option to analyze each AW object.
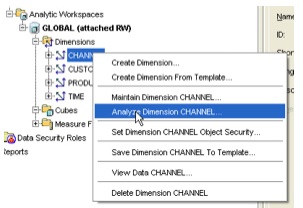
Selecting this brings up a dialog with the following message: "You are about [to] generate optimizer statistics which are used to create execution plans for certain types of queries involving materialized views or ET views associated with CHANNEL. Do you wish to proceed?" Very interesting. This is obviously gathering stats on the MV object over the AW dimension so that it gets considered for query rewrite. Very good. I'll leave this for them moment and come back to it once the cube is built.
I next create the cube, calling it UNITS, and take a look at the new features in the Create Cube dialog. The first thing I notice is that the Aggregation tab now has two sub-tabs, "Rules" and "Precompute". The rules sub-tab has the same features as previous AWM versions (set the aggregation order and method), however the new precompute tab now offers the ability to precompute by levels, as per previous AWM versions, or by percentage of the cube, which is new.
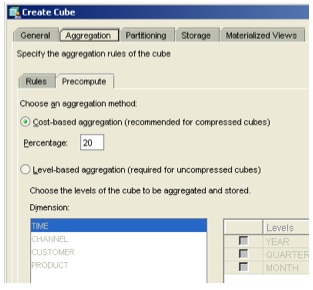
The precompute option is interesting. It tells AWM to either precompute nothing (set it to zero) and have all aggregates calculated on the fly, set it to 100 and have everything precomputed, or some figure in between. Choosing any non-zero number incurs the overhead of setting the aggregate structure up, so presumably there's some minimum figure you'd want to go for - say, 10% - but it's an interesting answer to the question I've had on seminars before when people ask which levels should they preaggregate in a cube.
Looking through the online help, you can see that if you partition the cube, you can set different percentages for the levels at or below the selected partitioning level of the cube, and the levels above, which is interesting as in the 10g version of Oracle OLAP, you couldn't preaggregate levels above the partitioning level (the "capstone level") - this was the reason why you didn't partition at too low a level in your cube - most of the cube then would need to have it's aggregates calculated on the fly.
In this new release, you can pre-aggregate the capstone levels, which is certainly interesting and potentially gives us the ability to make our cube partitioning very granular, the benefit of this being that we can isolate cube refreshes and recalculations to just those very granular partitions that have changed (something that's even more beneficial, at least in 10g, when you're using compressed composites). My guess is that there'll come a point where your cube is too granular, there'll be a trade-off between granularity of refreshes and the sheer number of AW objects to manage, but anyway, it obviously is an improvement over the 10g release and I'll be keen to see how performance stacks up for partitioned cubes moving to 11g.
Although "cost-based" aggregation is good, IMHO it could be made even better if another two options, "size-based" aggregation and "time-based" aggregation were added. In my experience, when you come to aggregate a cube, you don't really think "what percentage of the cube shall I aggregate", you really think "how much time shall I allocate to the cube build", or "how much disk space should I allocate" - if we could aggregate based on the likely amount of disk space a cube will take up (something Discoverer Administrator used to do, with it's Summary Advisor, and Enteprise Manager does (I think) when recommending MVs to create) this would be even more useful. As it is, you can choose a percentage figure that aggregates up from the bottom levels of the cube, and if you're trying to estimate how much disk space this will equate to, think of it as adding the equivalent percentage to the base size of your cube, assuming you're using compression.
Anyway, I set the cost-based figure to 50% and then go and create the measures, or measure, in this case, as it's just one measure, UNITS. I create it and then map it to the source data, and then switch back to the Materialized View tab for the cube.
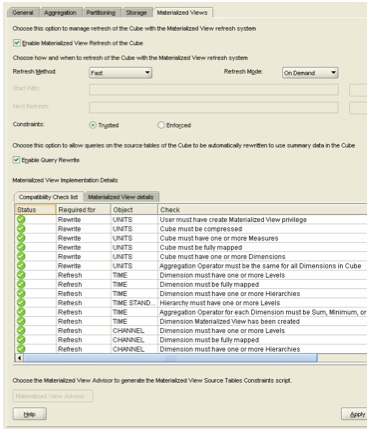
On this tab, you can enable the cube for MV refresh, set the refresh method and refresh mode, and also enable it for query rewrite, so that the analytic workspace is considered when queries come in against the source tables used to populate it.
Down the bottom of the dialog is the compatibility checklist, which when putting together my example checked out ok with no problems. Looking down the compatibility checklist was quite interesting; apart from the obvious ones ("dimension must be fully mapped, dimension must have one or more hierarchies" and so on) there were some ones I hadn't expected:
- Dimension must have one or more levels (so that rules out parent-child dimensions then)
- Cube must be compressed (why?)
- Aggregation operator for each dimension must be Sum, Minimum or Maximum (presumably, like the compression feature in 10gR1, this will be extended to other aggregation methods in the 11gR2 release)
- Aggregation operator must be the same for all dimensions in the cube (probably because the concept of dimensions having different aggregation operators doesn't really exist in SQL, and therefore MVs)
Going over to the Partitioning tab in the Cube dialog, I notice a new Partitioning Advisor button:

Pressing this brings up the following dialog
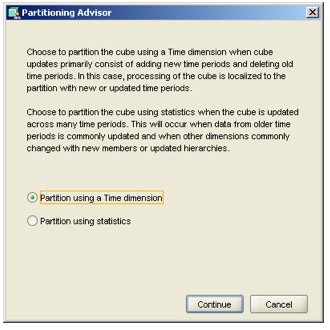
The message on the dialog reads: "Choose to partition the cube using a Time dimension when cube updates primarly consist of adding new time periods and deleting old time periods. In this case, processing of the cube is localized to the partition with new or updated time periods. Choose to partition the cube using statistics when the cube is updated across many time periods. This will occur when data from older time periods is commonly updated and when other dimensions commonly changed with new members or updated hierarchies"
That's pretty good actually. If you've read my previous posting on Analytic Workspace partitioning, you'll know that it primarily affects the load process - the AW engine only has to update and recalculate those partitions that have changed (when you use it in conjunction with compressed composites (aka "compression"), so if you can partition your cube by month, and only a month's worth of new data comes in, leaving the other month partitions unchanged, you get away without having to recalculate the whole cube (with the proviso, at least in 10g, that the levels above month couldn't be presummarized, meaning you had a trade-off between load time and query time, but as I mentioned above that might have changed with 11g). As partitioning takes a bit of judgement and it's always obvious when you first use it, these choices sum it up pretty well and will help new developers make some intelligent choices. Very good. I choose the Time Dimension option, whereapon the disk whirs a bit and comes up with the following recommendation:
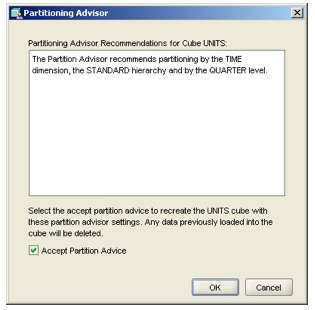
"The Partition Advisor recommends partitioning by the TIME dimension, the STANDARD hierarchy and by the QUARTER level."
I'm not sure on what basis it picked the "Quarter" level, except perhaps that it's the middle one between month and year, but I press cancel for the moment and go back to the advisor, this time picking the Statistics option instead.
This time it recommends partitioning on the Warehouse level of the CUSTOMER dimension:
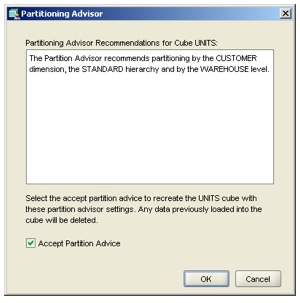
"The Partition Advisor recommends partitioning by the CUSTOMER dimension, the STANDARD hierarchy and by the WAREHOUSE level."
Again, not sure how it came to this conclusion, presumably it's down to the numbers of dimension members in each of the hierarchy levels, as the actual cube data hasn't been read in yet.
I decide to go for the Time Dimension partitioning option, let the advisor drop and recreate the cube (partitioning creates lots of individual variables in the AW, one for each partition, rather than the single one that there previously was for UNITS, which requires a drop and rebuild of the variable), and then move on to the Storage Advisor, which is where I make the decision about cube (or more properly, dimension) sparsity.
Again, there's a new button for this, and also notice how Compression (aka compressed composites) is automatically selected, and in fact greyed out so I can't unselect it - I suspect this is because I've chosen to create materialized views off of my cube, which as we saw earlier require that the cube is compressed (again, why though?) As compression is pretty much a no-brainer from 10gR2 onwards though, that's not a problem (the restriction on types of aggregation that were originally in 10gR1 were lifted with 10gR2), and so I press the Advisor button and see what happens:
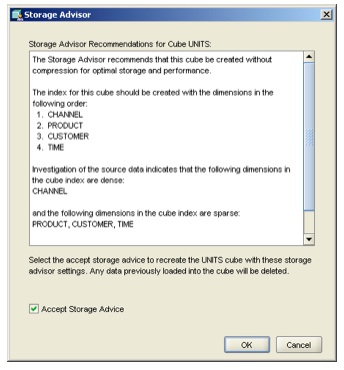
Ah, that's interesting. It's recommending that I don't use compression.
Curious. This must be like the old Sparsity Advisor in 10gR2, which actually samples the source data and calculates the actual sparsity value for each dimension. The recommendation is interesting though - first of all,not using compression would stop me using materialized views, which would be a shame, but I wonder why it didn't recommend using compression in the first place - the data is sparse (it's sales performance data, which is usually sparse, as compared to accounts type data, which is usually dense) and there's usually little downside at all to using compression, even if your data is fairly dense. Interesting.
Anyway, I choose to ignore the advice, and leave the cube as compressed, which removes the need to order the dimensions anyway, and instead right-click on the cube and select the Maintain option.
Going over to the filesystem to see the build script that AWM generated, again it's a DBMS_MVIEW script:
BEGIN
DBMS_CUBE.BUILD(
'GLOBAL.TIME, GLOBAL.CHANNEL, GLOBAL.CUSTOMER, GLOBAL.PRODUCT, GLOBAL.UNITS',
NULL,
false, -- refresh after errors
1, -- parallelism
false, -- atomic refresh
true, -- automatic order
true); -- add dimensions
END;
/
And looking at the cube in the cube viewer, it all looks fine:
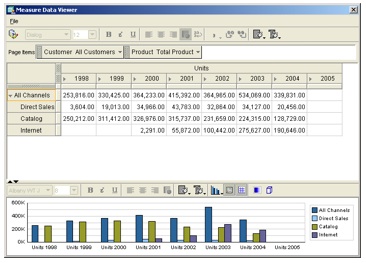
One of the new features I'd heard about with 11g was a new calculation builder, and so I navigate back to the UNITS cube and use the menu to create a new calculated measure. The calculation I'm going to create is "Units Percentage Change Prior Year", which Oracle OLAP should do easily due to the time dimension that I created earlier, so I enter that into the name section and take a look around the dialog.
Now this is quite a change from the 10g version of AWM. The "Calculation Type" drop-down menu lists out all the same calculations as AWM10g (simple calculations, time-series calculations and so on) plus what appears to be a new category (parallel calculations) and a section where you can add your own expression.
I select the percentage difference from prior period calculation, whereapon the dialog changes and reflects the chosen calculation:
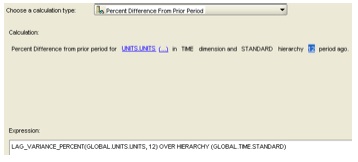
To go back a year, I'd have to change the "1" at the end of the calculation to "12", as the lowest level in the TIME dimension is month, and I need to go back 12 months. If you look underneath the calculation, there's an expression displayed that corresponds to the calculation I've just defined:
LAG_VARIANCE_PERCENT(GLOBAL.UNITS.UNITS, 12) OVER HIERARCHY (GLOBAL.TIME.STANDARD)
This is the new expression language that comes with Oracle OLAP 11g - the idea here is that DBAs might find OLAP DML a bit tricky to understand, whilst SQL doesn't have the capability of expressing some of the more advanced OLAP, time-series etc calculations. This OLAP expression language is a bit of a half-way house that has a similar syntax to SQL but that is designed for expressing OLAP calculations. It's the language that's used for 11g OLAP calculations, and you can enter your own expressions using the EXPRESSION calculation type.
Before I finish up with AWM, I've just noticed one more feature that I've not seen before, the "Cube Scripts" section within the cube definition.
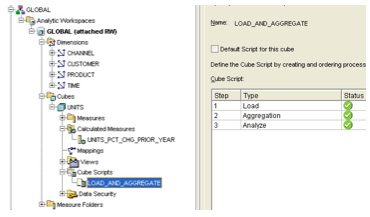
This seems similar in function to the Calculation Plans feature in AWM10g, a fefature that most people didn't really know about but that gets used to run custom aggregation scripts, allocations, forecasts and so on. Under the list of current steps are three buttons to create new steps, edit an existing step or delete a step, and pressing the New Step button displays a whole new set of build options.
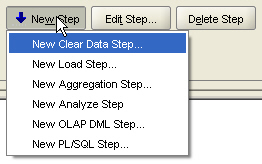
- "Create a new Data Step", which lets me nullify the dimensions or cube prior to a load
- "New Load Step", which gives me the option to load in new data into the cube, i.e. insert or update, or sychronize the cube, i.e. insert, update and delete
- "New Aggregation Step", which like AWM10g lets me aggregate, say, a forecasted measure where the forecast just generates the lowest-level values and I subsequently need to aggregate up the rest of the values in the dimension hierarchies
- "New Analyze Step", which does the materialized view analyzing that I mentioned earlier
- "New OLAP DML Step", and "New PL/SQL Step", which lets me execute arbitrary OLAP DML or PL/SQL as part of the process.
Now this looks like a very neat new feature. I especially like the New Load Step feature, this makes it very clear whether the cube is incrementally loaded or synchronized (deleting old data out of the cube was always a headache in previous AWM versions, and most new developers didn't realize this didn't happen by default) and it strikes me that this is a very nice, very welcome new bit of functionality. Excellent.
Anyway, now the cube's been created, I pop over to SQL Developer and take a look at what's been generated.
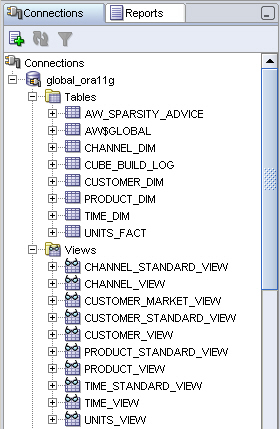
The first thing I notice is that the views over the AW dimensions and cube have been built automatically. In AWM 10g, you could do this through a plug-in to AWM, in Oracle Database 11g the views are created automatically (plus the types that you need to make the views work) whenever you create AW objects using a tool such as AWM (the magic is done I think through AW/XML, the Java API for maintaining AWs, I guess if you just went in to the OLAP Worksheet and typed in OLAP DML to create a dimension, this wouldn't happen).
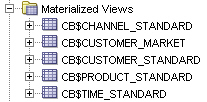
If I take a look down at the materialized view section though, I can see MVs for the dimensions, but not for the cube. What's happened here?
Going back into AWM, bringing up the Cube dialog shows that all of the compatibility checklist is marked with green ticks, but the Materialized View Details tab shows that this feature hasn't been enabled.
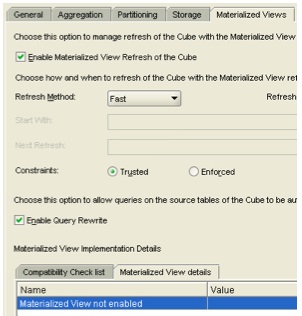
I wonder what's going on here then. Taking a look at the online help, it says the following:
"Note: If a cube is enabled with materialized view capabilities, then you cannot execute a cube script for that cube." 1. To create materialized views: Select a cube in the navigation tree. 2. Display the Materialized View tab. 3. Correct any errors in the definition of the cube that appear on the Refresh and Rewrite subtabs. Analytic Workspace Manager checks the cube for the prerequisites for adding materialized view capabilities. 5. Complete the Materialized View tab. 6. Click Create.
OK, sounds like I need to drop the cube script that I noticed a minute ago, I guess this is because it introduces the possibility of dropping OLAP DML or PL/SQL code into the cube refresh, setting dimensions and cubes to NA and so on, but then again this script was generated automatically for me when I defined the cube. Right, let's try again and this time keep an eye out for anything that might generate a cube script.
This time, I create the cube again, select the same options, press the Apply button on the cube dialog, and it creates the materialized view for me. I can only think that by mucking around with the various option (or perhaps mucking around with the cube script feature, when I had a look at what it could do) has set some flag to say the cube won't be permissable for a materialized view. Anyhoo, it looks like it's working now, plus there's also another button just below the MV details panel that launches a Materialized View Advisor.
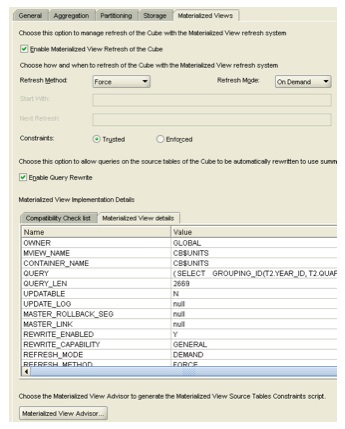
To use this feature, the account you're logged in as has to have the ADVISOR role granted:
grant advisor to global;
Now I could be wrong here, but I think this needs one of the Enterprise Manager management packs to be licensed (the same one that makes the SQL Access Advisor in 10g available) so you'll need to have the relevant license to use this.
Once it runs, it displays a script that will make query rewrite and your MV refresh process work more efficiently.
Looking through the script, it appears to do three major things:
- Create some standard Oracle dimensions, which are then used by query rewrite to roll up from one materialized view, at a certain level of aggregation, to another. My original source data didn't have these, so adding them is a good idea, although I'd be interested to see how the dimension feature (and query rewrite, to think about it) works when your querying a full-solved cube, or a partially-solved cube come to think about it.
- Create constraints on the AW source tables that ensures they qualify for query rewrite, and
- Create some materialized view logs, so that the fast refresh feature can be used. If you don't run these particular scripts, your MV (or should this be, your cube) won't benefit from the trickle-feed, incremental load that MVs can perform (in theory, as we'll come on to in a moment)
So, looks like this script is useful to run. I go back to AWM first though, build the cube again, which works ok and I see from SQL Developer that a materialized view has been created for the cube. Interestingly though, when I go back into AWM and set the cube refresh method to "Fast" rather than "Force", which was the original setting, it marks the accompanying materialized view as being unavailable again, which I think is where the issue was a minute ago. My guess here is that, in this initial release, it it does't actually support fast-refresh materialized views, certainly selecting this option makes the MV unavailable - I expect this will become available as a feature in a later patch release.
Using SQL Developer, I take a look at the SQL that shows for each of the AWM-generated materialized views, to see how they map to the AW. Here's the product dimension one:
CREATE MATERIALIZED VIEW "GLOBAL"."CB$PRODUCT_STANDARD"
ORGANIZATION CUBE ON "GLOBAL"
( DIMENSION "PRODUCT" IS "DIM_KEY"
ATTRIBUTE "PRODUCT_LEVELREL" IS "LEVEL_NAME"
ATTRIBUTE "PRODUCT_LONG_DESCRIPTION" IS "LONG_DESCRIPTION"
ATTRIBUTE "PRODUCT_MARKETING_MANAGER" IS "MARKETING_MANAGER"
ATTRIBUTE "PRODUCT_PACKAGE" IS "PACKAGE"
ATTRIBUTE "PRODUCT_SHORT_DESCRIPTION" IS "SHORT_DESCRIPTION"
ATTRIBUTE "__AW_GENERATED_19" IS "PRODUCT_ALL_PRODUCTS_ID"
ATTRIBUTE "PRODUCT_PRODUCT_CLASS_ID_UNIQU" IS "PRODUCT_CLASS_ID"
ATTRIBUTE "PRODUCT_PRODUCT_FAMILY_ID_UNIQ" IS "PRODUCT_FAMILY_ID"
ATTRIBUTE "PRODUCT_PRODUCT_ITEM_ID_UNIQUE" IS "PRODUCT_ITEM_ID"
)
BUILD DEFERRED
REFRESH COMPLETE ON DEMAND
USING TRUSTED CONSTRAINTS DISABLE QUERY REWRITE
AS (
SELECT
(CASE GROUPING_ID(T4.TOTAL_PRODUCT_ID, T4.CLASS_ID, T4.FAMILY_ID, T4.ITEM_ID)
WHEN 7
THEN TO_CHAR(T4.TOTAL_PRODUCT_ID)
WHEN 3
THEN TO_CHAR(T4.CLASS_ID)
WHEN 1
THEN TO_CHAR(T4.FAMILY_ID)
ELSE TO_CHAR(T4.ITEM_ID) END) DIM_KEY,
(CASE GROUPING_ID(T4.TOTAL_PRODUCT_ID, T4.CLASS_ID, T4.FAMILY_ID, T4.ITEM_ID)
WHEN 7
THEN TO_CHAR('ALL_PRODUCTS')
WHEN 3
THEN TO_CHAR('CLASS')
WHEN 1
THEN TO_CHAR('FAMILY')
ELSE TO_CHAR('ITEM') END) LEVEL_NAME,
T4.TOTAL_PRODUCT_ID PRODUCT_ALL_PRODUCTS_ID,
T4.CLASS_ID PRODUCT_CLASS_ID,
T4.FAMILY_ID PRODUCT_FAMILY_ID,
T4.ITEM_ID PRODUCT_ITEM_ID,
(CASE GROUPING_ID(T4.TOTAL_PRODUCT_ID, T4.CLASS_ID, T4.FAMILY_ID, T4.ITEM_ID)
WHEN 7
THEN MAX(T4.TOTAL_PRODUCT_DSC)
WHEN 3
THEN MAX(T4.CLASS_DSC)
WHEN 1
THEN MAX(T4.FAMILY_DSC)
ELSE MAX(T4.ITEM_DSC) END) LONG_DESCRIPTION,
(CASE GROUPING_ID(T4.TOTAL_PRODUCT_ID, T4.CLASS_ID, T4.FAMILY_ID, T4.ITEM_ID)
WHEN 7
THEN CAST (NULL AS VARCHAR2(20) )
WHEN 3
THEN CAST (NULL AS VARCHAR2(20) )
WHEN 1
THEN CAST (NULL AS VARCHAR2(20) )
ELSE MAX(T4.ITEM_MARKETING_MANAGER) END) MARKETING_MANAGER,
(CASE GROUPING_ID(T4.TOTAL_PRODUCT_ID, T4.CLASS_ID, T4.FAMILY_ID, T4.ITEM_ID)
WHEN 7
THEN CAST (NULL AS VARCHAR2(20) )
WHEN 3
THEN CAST (NULL AS VARCHAR2(20) )
WHEN 1
THEN CAST (NULL AS VARCHAR2(20) )
ELSE MAX(T4.ITEM_PACKAGE_ID) END) PACKAGE,
(CASE GROUPING_ID(T4.TOTAL_PRODUCT_ID, T4.CLASS_ID, T4.FAMILY_ID, T4.ITEM_ID)
WHEN 7
THEN MAX(T4.TOTAL_PRODUCT_DSC)
WHEN 3
THEN MAX(T4.CLASS_DSC)
WHEN 1
THEN MAX(T4.FAMILY_DSC)
ELSE MAX(T4.ITEM_DSC) END) SHORT_DESCRIPTION
FROM
GLOBAL.PRODUCT_DIM T4
GROUP BY
(T4.TOTAL_PRODUCT_ID) ,
ROLLUP ((T4.CLASS_ID) , (T4.FAMILY_ID) , (T4.ITEM_ID) )
) ;
That's interesting. Note the CREATE MATERIALIZED VIEW ... ORGANIZATION CUBE ON "GLOBAL", that's one of the new features in Oracle Database 11g (along with CUBE_TABLE, which complements the previous OLAP_TABLE) that makes accessing AWs a lot simpler. Note also the GROUP BY ... ROLLUP at the end as well, I wonder if the MV rewrite will work if your original SELECT statement doesn't include ROLLUP - we'll have to find out in a minute.
The MV over the cube is similarly interesting:
CREATE MATERIALIZED VIEW "GLOBAL"."CB$UNITS"
ORGANIZATION CUBE ON "GLOBAL"
( DIMENSION "CHANNEL" IS "CHANNEL"
ATTRIBUTE "__AW_GENERATED_23" IS "CHANNEL_ALL_CHANNELS_ID"
ATTRIBUTE "CHANNEL_CHANNEL_CHANNEL_ID_UNI" IS "CHANNEL_CHANNEL_ID",
DIMENSION "CUSTOMER" IS "CUSTOMER"
ATTRIBUTE "CUSTOMER_CUSTOMER_ACCOUNT_ID_U" IS "CUSTOMER_ACCOUNT_ID"
ATTRIBUTE "__AW_GENERATED_3" IS "CUSTOMER_ALL_CUSTOMERS_I"
ATTRIBUTE "__AW_GENERATED_7" IS "CUSTOMER_ALL_MARKETS_ID"
ATTRIBUTE "__AW_GENERATED_11" IS "CUSTOMER_MARKET_SECTOR_I"
ATTRIBUTE "CUSTOMER_CUSTOMER_REGION_ID_UN" IS "CUSTOMER_REGION_ID"
ATTRIBUTE "CUSTOMER_CUSTOMER_SHIP_TO_ID_U" IS "CUSTOMER_SHIP_TO_ID"
ATTRIBUTE "__AW_GENERATED_15" IS "CUSTOMER_WAREHOUSE_ID",
DIMENSION "PRODUCT" IS "PRODUCT"
ATTRIBUTE "__AW_GENERATED_19" IS "PRODUCT_ALL_PRODUCTS_ID"
ATTRIBUTE "PRODUCT_PRODUCT_CLASS_ID_UNIQU" IS "PRODUCT_CLASS_ID"
ATTRIBUTE "PRODUCT_PRODUCT_FAMILY_ID_UNIQ" IS "PRODUCT_FAMILY_ID"
ATTRIBUTE "PRODUCT_PRODUCT_ITEM_ID_UNIQUE" IS "PRODUCT_ITEM_ID",
DIMENSION "TIME" IS "TIME"
ATTRIBUTE "TIME_TIME_YEAR_ID_UNIQUE_KEY" IS "TIME_YEAR_ID"
ATTRIBUTE "TIME_TIME_QUARTER_ID_UNIQUE_KE" IS "TIME_QUARTER_ID"
ATTRIBUTE "TIME_TIME_MONTH_ID_UNIQUE_KEY" IS "TIME_MONTH_ID",
FACT "UNITS_STORED"("UNITS_MEASURE_DIM" 'SYS_COUNT') IS "SYS_COUNT",
FACT "UNITS_STORED"("UNITS_MEASURE_DIM" 'UNITS') IS "UNITS",
GROUPING ID ("TIME_CGID", "CHANNEL_CGID", "CUSTOMER_CGID", "PRODUCT_CGID") IS "SYS_GID"
)
BUILD DEFERRED
REFRESH FORCE ON DEMAND
USING TRUSTED CONSTRAINTS ENABLE QUERY REWRITE
AS (
SELECT
GROUPING_ID(T2.YEAR_ID, T2.QUARTER_ID, T2.MONTH_ID, T4.TOTAL_CHANNEL_ID, T4.CHANNEL_ID, T5.TOTAL_CUSTOMER_ID, T5.REGION_ID, T5.WAREHOUSE_ID, T5.SHIP_TO_ID, T5.TOTAL_MARKET_ID, T5.MARKET_SEGMENT_ID, T5.ACCOUNT_ID, T6.TOTAL_PRODUCT_ID, T6.CLASS_ID, T6.FAMILY_ID, T6.ITEM_ID) SYS_GID,
(CASE GROUPING_ID(T2.YEAR_ID, T2.QUARTER_ID, T2.MONTH_ID)
WHEN 3
THEN TO_CHAR(T2.YEAR_ID)
WHEN 1
THEN TO_CHAR(T2.QUARTER_ID)
ELSE TO_CHAR(T2.MONTH_ID) END) TIME,
T2.YEAR_ID TIME_YEAR_ID,
T2.QUARTER_ID TIME_QUARTER_ID,
T2.MONTH_ID TIME_MONTH_ID,
(CASE GROUPING_ID(T4.TOTAL_CHANNEL_ID, T4.CHANNEL_ID)
WHEN 1
THEN TO_CHAR(T4.TOTAL_CHANNEL_ID)
ELSE TO_CHAR(T4.CHANNEL_ID) END) CHANNEL,
T4.TOTAL_CHANNEL_ID CHANNEL_ALL_CHANNELS_ID,
T4.CHANNEL_ID CHANNEL_CHANNEL_ID,
(CASE NULL
WHEN 7
THEN TO_CHAR(T5.TOTAL_CUSTOMER_ID)
WHEN 3
THEN TO_CHAR(T5.REGION_ID)
WHEN 1
THEN TO_CHAR(T5.WAREHOUSE_ID)
ELSE TO_CHAR(T5.SHIP_TO_ID) END) CUSTOMER,
T5.TOTAL_CUSTOMER_ID CUSTOMER_ALL_CUSTOMERS_I,
T5.REGION_ID CUSTOMER_REGION_ID,
T5.WAREHOUSE_ID CUSTOMER_WAREHOUSE_ID,
T5.SHIP_TO_ID CUSTOMER_SHIP_TO_ID,
T5.TOTAL_MARKET_ID CUSTOMER_ALL_MARKETS_ID,
T5.MARKET_SEGMENT_ID CUSTOMER_MARKET_SECTOR_I,
T5.ACCOUNT_ID CUSTOMER_ACCOUNT_ID,
(CASE GROUPING_ID(T6.TOTAL_PRODUCT_ID, T6.CLASS_ID, T6.FAMILY_ID, T6.ITEM_ID)
WHEN 7
THEN TO_CHAR(T6.TOTAL_PRODUCT_ID)
WHEN 3
THEN TO_CHAR(T6.CLASS_ID)
WHEN 1
THEN TO_CHAR(T6.FAMILY_ID)
ELSE TO_CHAR(T6.ITEM_ID) END) PRODUCT,
T6.TOTAL_PRODUCT_ID PRODUCT_ALL_PRODUCTS_ID,
T6.CLASS_ID PRODUCT_CLASS_ID,
T6.FAMILY_ID PRODUCT_FAMILY_ID,
T6.ITEM_ID PRODUCT_ITEM_ID,
SUM(T3.UNITS) UNITS,
COUNT(*) SYS_COUNT
FROM
GLOBAL.TIME_DIM T2,
GLOBAL.UNITS_FACT T3,
GLOBAL.CHANNEL_DIM T4,
GLOBAL.CUSTOMER_DIM T5,
GLOBAL.PRODUCT_DIM T6
WHERE
((T2.MONTH_ID = T3.MONTH_ID)
AND (T4.CHANNEL_ID = T3.CHANNEL_ID)
AND (T5.SHIP_TO_ID = T3.SHIP_TO_ID)
AND (T6.ITEM_ID = T3.ITEM_ID) )
GROUP BY
(T2.YEAR_ID) ,
ROLLUP ((T2.QUARTER_ID) , (T2.MONTH_ID) ) ,
(T4.TOTAL_CHANNEL_ID) ,
ROLLUP ((T4.CHANNEL_ID) ) ,
GROUPING SETS ((T5.TOTAL_CUSTOMER_ID) , (T5.TOTAL_CUSTOMER_ID, T5.REGION_ID) , (T5.TOTAL_CUSTOMER_ID, T5.REGION_ID, T5.WAREHOUSE_ID) , (T5.TOTAL_CUSTOMER_ID, T5.REGION_ID, T5.WAREHOUSE_ID, T5.SHIP_TO_ID, T5.TOTAL_MARKET_ID, T5.MARKET_SEGMENT_ID, T5.ACCOUNT_ID) , (T5.TOTAL_MARKET_ID) , (T5.TOTAL_MARKET_ID, T5.MARKET_SEGMENT_ID) , (T5.TOTAL_MARKET_ID, T5.MARKET_SEGMENT_ID, T5.ACCOUNT_ID) ) ,
(T6.TOTAL_PRODUCT_ID) ,
ROLLUP ((T6.CLASS_ID) , (T6.FAMILY_ID) , (T6.ITEM_ID) )
) ;
Again note the ORGANIZED_CUBE, and the GROUP BY .... ROLLUP ... GROUPING SETS later on - again I wonder whether standard, vanilla, SQL will rewrite to this properly. Well, there's only one way to find out...
First of all though, I clear down all the constraints that already exist in the source schema, and run the script generated by the Materialized View advisor to make sure everything's set up just right for query rewrite. Then, I run the following explain plan for a simple SQL SELECT statement, that in theory should rewrite to use the analytic workspace I've just built:
explain plan for select sum( u.units), c.market_segment_dsc, t.year_dsc, p.family_id from units_fact u, customer_dim c, time_dim t, product_dim p where u.ship_to_id = c.ship_to_id and u.month_id = t.month_id and u.item_id = p.item_id group by c.market_segment_dsc, t.year_dsc, p.family_id;PLAN_TABLE_OUTPUT
Plan hash value: 3517365018
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 19 | 2375 | 37 (6)| 00:00:01 |
| 1 | HASH GROUP BY | | 19 | 2375 | 37 (6)| 00:00:01 |
|* 2 | HASH JOIN | | 19 | 2375 | 36 (3)| 00:00:01 |
|* 3 | HASH JOIN | | 19 | 2071 | 33 (4)| 00:00:01 |
|* 4 | CUBE SCAN PARTIAL OUTER| CB$UNITS | 20 | 2000 | 29 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | TIME_DIM | 96 | 864 | 3 (0)| 00:00:01 |
| 6 | TABLE ACCESS FULL | CUSTOMER_DIM | 61 | 976 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("C"."SHIP_TO_ID"=SYS_OP_ATG(VALUE(KOKBF$),8,9,2))
3 - access("T"."MONTH_ID"=SYS_OP_ATG(VALUE(KOKBF$),4,5,2))
4 - filter(SYS_OP_ATG(VALUE(KOKBF$),23,24,2)=5)20 rows selected
So, a partial success. Oracle has rewritten the statement to use the UNITS analytic workspace, you can see that from the CUBE SCAN PARTIAL OUTER in the explain plan. What it has also done though is join to the dimension tables to retrieve the dimension attributes, from speaking to people within the development team I think this is a limitation 11g OLAP has got now, but that will disappear with subsequent releases, as it should be able to get all the dimensional attribute data from the big, denormalized view over the cube and it's dimensions. For the time being though, it does make this (unnecessary) join to the dimension tables to retrieve the dimension data, although from other tests I've done on larger data sets, this is still faster than accessing relational summaries.
So, there we have it; a potted introduction the 11g release of Oracle OLAP, with a special emphasis on the new Cube Organized Materialized View feature. On a later date, I'll be seeing how much it can speed up a series of relational Discoverer workbooks, this for me is the major payoff for this new technology, as it offers two main benefits - the ability to keep on using Discoverer relational (or Answers Plus, when it comes out) but with the speed and calculation ability of Oracle OLAP.