Oracle Open World 2008, Day 4 : OBIEE Action Framework, and OBIEE Performance Tuning
I'm just catching up now on my Open World notes, as I'm staying for an extra day to go to Redwood Shores tomorrow for a meeting with the OWB product development team. Wednesday (Day 4) was my first day without any presentations, and with Larry's keynote during the early afternoon I managed to go to a session on the OBIEE Action Framework in the morning, and - the session I'd been waiting all week for - the OBIEE Performance Tuning one, at the end of the day.
I blogged about the forthcoming Action Framework in OBIEE 11g in a blog post last year, and this year Nick Tuson and Adam Bloom, two of the OBIEE product managers based just down the road from me in Bristol, gave an update on the progress of this feature. The basic idea with the action framework is that you can define, in the web catalog, "actions" that represent calls to web services, java methods, scripts or URLs that you can then attach to data items in your reports. Actions have three parts to them; an action definition that contains the action name, parameter names, button names and so on; a set of parameter mappings, and an action implementation, that defines the java class, web service call and so on that the action uses.
Adam also introduced another new addition to the web catalog in 11g, "conditions", which are defined against data items and can be used by actions and other processes to run checks like "is the customer profitable", "do they have a checking account" and so on, I used a variation on this when doing my BI and SOA articles and it's a similar idea to the conditions that you can define in the Discoverer EUL. In terms of dates, we're still looking at "some date in calendar year 2009" for OBIEE 11g, but it certainly sounds like they're packing in the features. I was also amused to see that the quote on Nick's slides around the action framework came from my blog post last year, I was certainly happy to endorse the new feature as it's shaping up to be one of the most innovative features in this forthcoming release.
Apart from live blogging Larry's keynote just after lunch, I managed to get myself along to Bob Ertl's session on Optimizing Oracle Business Intelligence Enterprise Edition. I was particularly looking forward to this session as it was the only one that took a look at OBIEE internals; in previous years we've had Ed Suen doing sessions on the semantic object layer and Kurt Wolf doing ones on OBIEE architecture, however I understand both have left recently and therefore Bob looks to have taken up the mantle of chief internals specialist for OBIEE. The session itself was really good, I really enjoyed it, Bob was leapt on a bit by enthusiastic and questioning OBIEE architects and performance tuners at the end but I think this just illustrates the interest there is in this area. Anyway, here's a synopsis of what Bob had to say:
OBIEE queries can run slowly for three main reasons:
- They scan too many records on the disk, typically caused by tables being too large, too much data needing to be aggregated, transformations being too complex, too many joins or poor SQL. The typical database solution to this is to add indexes, partitioning, summary management, batch aggregation, move the aggregation to the ETL process, create star schemas and so on. In the OBIEE world, you typically address this by using aggregate navigation, use caching, follow BI data modeling best practices. Bob noted that customers often turn to caching as their first solution to problems in this area, but this only addresses part of the problem.
- Returning too many records over the network, due to poor SQL, using unsupported DB functions, doing a cross-join (OBIEE federated queries) involving large tables, poor prompt design. In the RDBMS world you can address this by centralizing your data into a data warehouse (therefore decreasing the network traffic caused by cross-database joins), following model practices, using the drive table join feature, setting prompts appropriately, and using caching.
- Interface and processing bottlenecks, such as incorrect connection pool settings, setting logging too too high, incorrect configuration settings, insufficeint hardware. Funnily enough at least the first two of these issues are addressed by the new database machine and exadata storage servers announced yesterday, but at least on smaller systems you've got to address these things yourself.
- Pre-aggregation functions and filters are applied to the data
- Aggregations are performed
- For the BI Server, multiple result sets from federated queries are "stitched" together, and
- Post-aggregation functions and filters are applied.
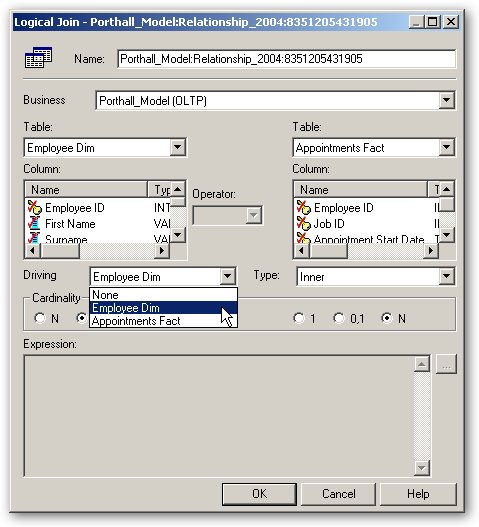
There was also talk about how the BI Server goes about stitching disparate results sets together. This is something where, for example, you define a fact table in the business model and mapping layer and then map this to two physical data sources. When a query runs, two separate SQL statements are generated and the BI Server "stitches" the data together. The problem here comes when you try and do this with large data sets, as all the data is accessed and loaded into data before the BI Server joins the data in memory using a common key column. Bob talked about a BI Server feature called "parameterized nested loop joins", where you can set the driving table for a federated query, like this:
Bob then went on to talk about Aggregate Persistence (I covered this in a previous blog posting) and talked about some features that might be coming in future releases, including parallel loading of aggregated data into the aggregate tables created by the wizard; automatic indexing (of the underlying data warehouse? or the aggregate tables created by the Aggregate Persistence Wizard?), an advisor function on which aggregates to create and which to drop; selective deletion of aggregates (currently it's all or nothing), and incremental loads of aggregate tables, although this is a bit trickier. I also asked about future integration with Oracle materialized views, this apparently is being looked at as of course it provides many of these features built into the (Oracle) database.
The final section of the talk was on logging, and the usage tracking repository tables and reports that ship with OBIEE and the BI Applications. Whilst logical and physical query logging is something you typically only turn on when diagnosing performance problems, usage tracking is something you can and should turn on permanently, the results of which you can store to file or better, to tables, so that you can generate dashboards and reports off of the usage data generated. The usage tracking reports themselves contain data such as when reports are run, what reports are the most popular, statistics (time of day, total time, compile time, number of rows returned and so on), these can also be reported on by the BI Administration plug in that you can obtain for Oracle Enterprise Manager. There are some best practices around setting up the usage tracking system; the BI Server should connect to the usage tracking tables via it's own connection pool, writes are batched to every five minutes, run the usage tracking system on the same database server as the business content. Apparently an Oracle by Example tutorial is coming soon for the usage tracking system, keep an eye out on OTN for this.
Anyway, as I said it was an excellent session, and I suggested at the end that those who had come along and expressed an interest in the area should stay in contact. So, if you're interested in setting up an informal "OBIEE Performance Tuning User Group", let me know and I'll put us all in contact.