Testing Advanced (OLTP) Compression in Oracle 11g
Another new feature in Oracle 11g of interest to data warehouse developers is Advanced Compression. This new feature extends the capabilities of segment compression first introduced with Oracle 9i, but crucially makes it work for all DML operations, not just direct path inserts, direct path SQL*Loader operations and CREATE TABLE ... AS SELECT operations. As such I've seen it also referred to as "OLTP Compression" as it makes compression now available to OLTP, transaction applications as well as data warehouses. It's also (wait for it) a pay-extra option, which means that it's not just a feature upgrade for traditional segment compression and instead requires you to pay an extra license fee on top of the regular Enterprise Edition license. That aside though, how does it work, and more importantly, given that the old 9i and 10g compression only worked for direct path operations with regular, conventional path operations causing the compression to be lost, does it use a new compression algorithm or is there something clever going on behind the scenes?
To do a quick recap on segment compression prior to Oracle 11g, tables and other segments (except index-organized tables) could be designated as compressed by adding the COMPRESS clause to the CREATE TABLE statement. For partitioned tables partition compression would be inherited from the table or could be designated at a partition level within the create table command. Table compression could be switched on or off after the table or partition was created by using using an ALTER TABLE...MOVE... command. Anyway, creating a compressed table and in this case loading it directly using a CREATE TABLE ... AS SELECT statement looked like this, with the command that follows afterwards comparing the size of the new compressed table with the table that provided its data.
SQL> CREATE TABLE comp_customer COMPRESS AS SELECT * FROM copy_customer; Table created. SQL> SQL> SELECT segment_name "Table_Name", bytes / 1024 / 1024 "Megabytes" 2 FROM user_segments 3 WHERE segment_type = 'TABLE' AND segment_name LIKE 'CO%CUST%' 4 ORDER BY segment_name, tablespace_name; Table_Name Megabytes ------------------------------------------------------------- ---------- COMP_CUSTOMER 5 COPY_CUSTOMER 8
You can actually influence the degree of compression by choosing the order in which you load the table; depending on the nature of your data often one columns will give better compression ratios than another, and you also need to factor in the way in which the table is accessed. This presentation by Jeff Moss at a UKOUG Business Intelligence & Reporting Tools SIG Meeting a couple of years ago goes through the factors and how you can come up with the optimal column ordering. Anyway, to show the sort of different this can make, I'll now create the same table again but this time sort by the customer last name.
SQL> DROP TABLE comp_customer; Table dropped. SQL> CREATE TABLE comp_customer COMPRESS AS SELECT * FROM copy_customer ORDER BY cust_last_name; Table created. SQL> SQL> SELECT segment_name "Table_Name", bytes / 1024 / 1024 "Megabytes" 2 FROM user_segments 3 WHERE segment_type = 'TABLE' AND segment_name LIKE 'CO%CUST%' 4 ORDER BY segment_name, tablespace_name; Table_Name Megabytes ------------------------------------------------------------- ---------- COMP_CUSTOMER 4 COPY_CUSTOMER 8
So now by ordering the compressed table data load by the customer last name, I've reduced the space required by the table by 20%.
Of course as I mentioned before, Oracle 9i and 10g compression only works with direct path operations. If, for example, you went and inserted another batch of the same records into the same table but didn't use a direct path operation, you will find that the new data takes up more or less the same space as the data it was copied from, showing that compression hasn't been applied.
SQL> INSERT INTO comp_customer SELECT * FROM copy_customer ORDER BY cust_last_name; 55500 rows created. SQL> commit; Commit complete. SQL> SELECT segment_name "Table_Name", bytes / 1024 / 1024 "Megabytes" 2 FROM user_segments 3 WHERE segment_type = 'TABLE' AND segment_name LIKE 'CO%CUST%' 4 ORDER BY segment_name, tablespace_name; Table_Name Megabytes ------------------------------------------------------------- ---------- COMP_CUSTOMER 11 COPY_CUSTOMER 8
It's even worse for updates, as any data that you update then loses its compression, taking up space and slowing the update down whilst the decompression takes place.
SQL> CREATE TABLE comp_customer COMPRESS AS SELECT * FROM copy_customer ORDER BY cust_last_name; Table created. SQL> SELECT segment_name "Table_Name", bytes / 1024 / 1024 "Megabytes" 2 FROM user_segments 3 WHERE segment_type = 'TABLE' AND segment_name LIKE 'COMP%CUST%' 4 ORDER BY segment_name, tablespace_name; Table_Name Megabytes ------------------------------------------------------------- ---------- COMP_CUSTOMER 4 SQL> UPDATE comp_customer SET cust_year_of_birth=1900; 55500 rows updated. SQL> SELECT segment_name "Table_Name", bytes / 1024 / 1024 "Megabytes" 2 FROM user_segments 3 WHERE segment_type = 'TABLE' AND segment_name LIKE 'COMP%CUST%' 4 ORDER BY segment_name, tablespace_name; Table_Name Megabytes ------------------------------------------------------------- ---------- COMP_CUSTOMER 7
Now it's this issue with updates removing the compression from tables, that makes compression quite tricky to work with in certain data warehouses; the ones that need to go back and alter data in the fact table, for example, after it's been loaded. Now if you've read papers and presentations by the likes of Tim Gorman, Jeff, even myself you'll have read references to the general best practice of loading data into the warehouse once, compressing it, backing it up, making the new partitions read-only and thereby reducing the work required to backup your data and store it to disk. In theory this is all well and good, but in practice I often come across customers who for whatever valid reason need to regularly go back and reload fact data into their warehouse, which reduces the value of compression as each update will remove the compression on the blocks that contain the rows affected. It's for this reason that I was interested when Advanced Compression was announced, as it potentially means that these customers can also use compression (as long as they pay the extra license fee) and not worry about going back and updating their data. They still face the problem that it's tricky to work out when data is "closed-off" and safe to mark read-only, but at least they won't need to worry about the disk requirement for their data creeping up and up after it is initially loaded.
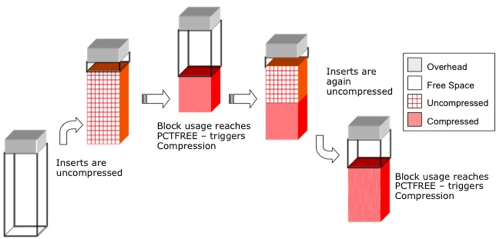
So how does this new Advanced Compression feature work then? According to the manuals, my understanding is that it's not a new "decompression-safe" algorithm that used, what actually happens with advanced compression is this:
- A table created using the advanced compression feature is initially actually uncompressed
- New data is loaded using conventional path (and direct path) inserts, updated as neccessary
- When the table's PCTFREE limit is reached, the compression algorithm kicks in and compresses the data
- Inserts and updates then carry on, with updates decompressing the table rows as before
- When the table's PCTFREE limit is again reached, compression kicks in again to pack down the rows.
So let's give it a try then. To test the feature out, I'm going to create one table with no compression (REG_CUSTOMER), one with traditional 10g compression (COMP_CUSTOMER) and one with 11g advanced compression (ADV_COMP_COMPRESSION). I'm going to load the uncompressed and advanced compressed tables using conventional path loads, and the traditionally compressed table using a direct path load. Note that I've specifically defined the PCTFREE for each table as 10, as setting the table to traditional COMPRESS seems to set it to 0 by default whereas (at least with my default USERS tablespace) regular tables and tables with COMPRESS FOR ALL OPERATIONS get a default PCTFREE of 10, which would skew the results if I didn't equalize them.
SQL> create table reg_customer pctfree 10 as select * from copy_customer;
Table created.
SQL> create table comp_customer pctfree 10 compress FOR DIRECT_LOAD OPERATIONS as select * from copy_customer;
Table created.
SQL> create table adv_comp_customer pctfree 10 compress FOR ALL OPERATIONS as select * from copy_customer where 1=2;
Table created.
SQL> insert into adv_comp_customer select * from copy_customer;
55500 rows created.
SQL> pause
SQL> SELECT segment_name "Table_Name", bytes / 1024 / 1024 "Megabytes"
2 FROM user_segments
3 WHERE segment_type = 'TABLE' AND segment_name in ('REG_CUSTOMER','COMP_CUSTOMER','ADV_COMP_CUSTOMER')
4 ORDER BY segment_name, tablespace_name;
Table_Name Megabytes
------------------------------------------------------------- ----------
ADV_COMP_CUSTOMER 6
COMP_CUSTOMER 5
REG_CUSTOMER 8
So the advanced compressed table is taking up less space than the uncompressed table, but a bit more than the traditionally-compressed table. Given the way advanced compression works I suspect this is down to some of the blocks not reaching their PCTFREE level and therefore being either fully uncompressed or partially compressed but in need of further compression. Of course this leads to the strange situation where a table can end up with certain rows compressed and not others, I guess it all comes out in the wash though.
SQL> set timing on
SQL> update reg_customer set cust_first_name = 'Mark';
55500 rows updated.
Elapsed: 00:00:01.79
SQL> commit;
Commit complete.
Elapsed: 00:00:00.04
SQL> update comp_customer set cust_first_name = 'Mark';
55500 rows updated.
Elapsed: 00:00:04.65
SQL> commit;
Commit complete.
Elapsed: 00:00:00.00
SQL> update adv_comp_customer set cust_first_name = 'Mark';
55500 rows updated.
Elapsed: 00:00:20.00
SQL> commit;
Commit complete.
Elapsed: 00:00:00.01
SQL>
SQL> SELECT segment_name "Table_Name", bytes / 1024 / 1024 "Megabytes"
2 FROM user_segments
3 WHERE segment_type = 'TABLE' AND segment_name in ('REG_CUSTOMER','COMP_CUSTOMER','ADV_COMP_CUSTOMER')
4 ORDER BY segment_name, tablespace_name;
Table_Name Megabytes
------------------------------------------------------------- ----------
ADV_COMP_CUSTOMER 8
COMP_CUSTOMER 9
REG_CUSTOMER 8
OK, so that's interesting. Updating the uncompressed table took just under 2 seconds, whereas updating the traditionally compressed table took around 4 seconds. Updating the advanced compressed table took 20 seconds though, which I guess has something to do with the block compression kicking in in the background. The traditionally compressed table has also increased in size to 9MB compared to the uncompressed and advanced compressed tables, which would indicate that the advanced compression bit (i.e. not leading to block decompression) is working.
Let's add some more data in and see what happens.
SQL> insert into reg_customer select * from copy_customer;
55500 rows created.
Elapsed: 00:00:00.15
SQL> insert /*+ APPEND */ into comp_customer select * from copy_customer;
55500 rows created.
Elapsed: 00:00:03.06
SQL> insert into adv_comp_customer select * from copy_customer;
55500 rows created.
Elapsed: 00:00:02.61
SQL>
SQL> commit;
Commit complete.
Elapsed: 00:00:00.00
SQL>
SQL> SELECT segment_name "Table_Name", bytes / 1024 / 1024 "Megabytes"
2 FROM user_segments
3 WHERE segment_type = 'TABLE' AND segment_name in ('REG_CUSTOMER','COMP_CUSTOMER','ADV_COMP_CUSTOMER')
4 ORDER BY segment_name, tablespace_name;
Table_Name Megabytes
-------------------------------------------------------------- ----------
ADV_COMP_CUSTOMER 13
COMP_CUSTOMER 14
REG_CUSTOMER 16
That's as I would expect, the conventional path insert into the advanced compressed table has taken up as little space as the direct path insert into the traditionally compressed table. Going back to the updates now, let's really hammer the tables and insert some values that are bound to increase the space required for each row.
SQL> update adv_comp_customer set cust_credit_limit = 500 where cust_id between 9000 and 10000;
2002 rows updated.
Elapsed: 00:00:00.39
SQL> update comp_customer set cust_credit_limit = 500 where cust_id between 9000 and 10000;
2002 rows updated.
Elapsed: 00:00:03.34
SQL> update reg_customer set cust_credit_limit = 500 where cust_id between 9000 and 10000;
2002 rows updated.
Elapsed: 00:00:01.17
SQL> update adv_comp_customer set cust_year_of_birth = 1990 where mod(cust_id, 19) = 1;
5842 rows updated.
Elapsed: 00:00:00.25
SQL> update comp_customer set cust_year_of_birth = 1990 where mod(cust_id, 19) = 1;
5842 rows updated.
Elapsed: 00:00:00.82
SQL> update reg_customer set cust_year_of_birth = 1990 where mod(cust_id, 19) = 1;
5842 rows updated.
Elapsed: 00:00:00.29
SQL> update adv_comp_customer set cust_marital_status = 'Separated' where substr(cust_last_name,1,1) = 'M';
5370 rows updated.
Elapsed: 00:00:00.93
SQL> update comp_customer set cust_marital_status = 'Separated' where substr(cust_last_name,1,1) = 'M';
5370 rows updated.
Elapsed: 00:00:00.48
SQL> update reg_customer set cust_marital_status = 'Separated' where substr(cust_last_name,1,1) = 'M';
5370 rows updated.
Elapsed: 00:00:00.67
SQL>
SQL> commit;
Commit complete.
Elapsed: 00:00:00.01
SQL>
SQL> SELECT segment_name "Table_Name", bytes / 1024 / 1024 "Megabytes"
2 FROM user_segments
3 WHERE segment_type = 'TABLE' AND segment_name in ('REG_CUSTOMER','COMP_CUSTOMER','ADV_COMP_CUSTOMER')
4 ORDER BY segment_name, tablespace_name;
Table_Name Megabytes
------------------------------------------------------------- ----------
ADV_COMP_CUSTOMER 13
COMP_CUSTOMER 14
REG_CUSTOMER 16
So, as before, the advanced compressed table is still smaller than either the traditional compressed table or the uncompressed table, which would indicate that it's still keeping its compression ever after lots of updates, although it's interesting to note that the traditional compression table requires less space than the uncompressed table, even after all the updates.
So, on the face of it, this new feature appears to work. If you're in that situation where you need to go back and update your fact table but you still want to use compression, it may be worth running some tests on your own data to see if you'll get this sort of benefit. There's still an advantage to eliminating updates if at all possible, as using inserts only allows you to put these into time-based partitions and then close them off an mark them as read-only as data is loaded, but if your main concern is around saving space and having more rows returned faster during full table scans, this might be an interesting new feature to test out.