Comparing ODI and OWB's Data Profiling and Quality Options
Now that Oracle Data Integrator and Oracle Warehouse Builder are starting to converge, I thought it worth taking a closer look at what's new with the 10.1.3.4 and 10.1.3.5 releases of ODI. One of the most interesting new features introduced with ODI 10.1.3.4 was new data quality and profiling capabilities, and so given the new interest in ODI I thought it'd be worth downloading the new release and seeing how these new features work.
The new data quality features in ODI comes in the form of a separate application to ODI, called Oracle Data Profiling and Quality for Oracle Data Integrator (or ODQ for short), that runs alongside ODI and creates data cleansing jobs that can be executed as part of the ODI workflow. ODQ was actually developed by Oracle in association with Trillium, and as such has a different user interface to ODI, is a Windows native executable, and at this stage apart from the job export facility doesn't really have many hooks into ODI. If you're used to using the OWB Data Quality Option though, it's certainly an interesting piece of software and I'll try and draw some comparisons between the two tools as we go along.
To see how this new feature works, I worked my way through the tutorial that's available on OTN and started working through the project. Assuming that you want to profile some data first and then clean it up, the first task you have to perform is to create what's called a "metabase" that stores the detailed profile that you generate for your source data. As such this metabase is similar to the _PRF profiling schema that gets created when you start profiling data in OWB, except it seems to be bit easier to set up and doesn't require an instance of Oracle to store the data in. Of course as the product is separate from ODI the metabase you create here is different from the repository you create for ODI.

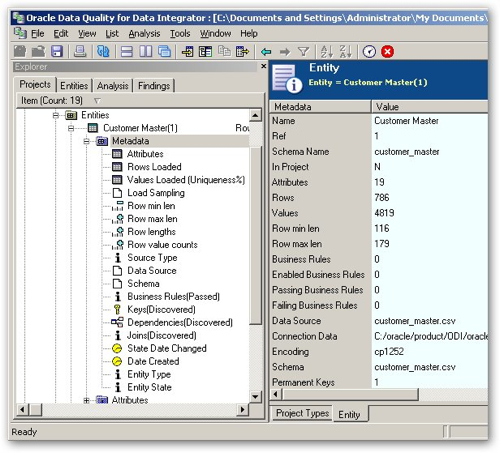
Once your data is initially profiled, you can start to view information at the individual entity level, such as this overall profile "metadata":
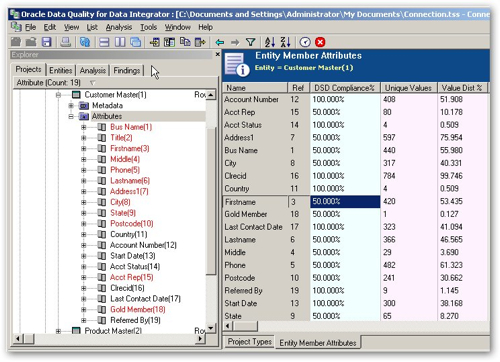
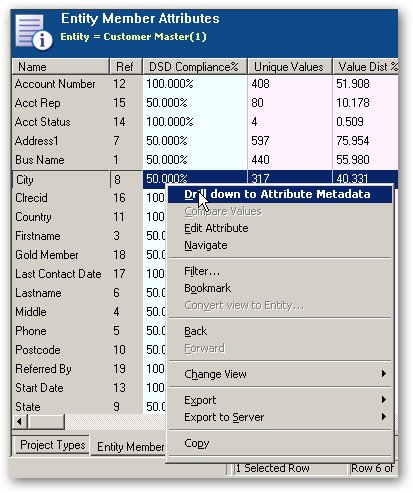
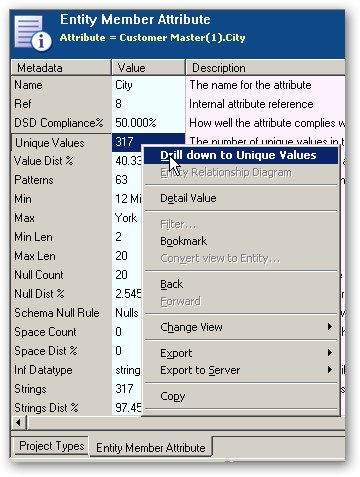
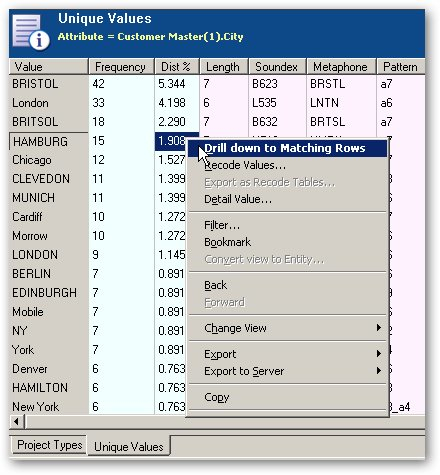
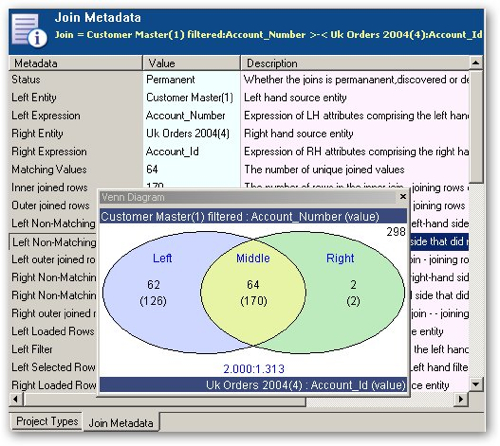
Like the OWB Data Profiler, you can generate statistics and venn diagrams about table joins, like this:
The OWB Data Quality Option has the concept of Data Rules, where you can define rules and constraints which then get applied to your data in order to ensure compliance with these rules downstream in your ETL process. OWB goes one better in that it auto-detects and proposes data rules for you (where, for example, 90% of your column values are one of five values, and the rest are probably spelling mistakes), whereas in ODQ you set these up yourself manually. Again the ODQ interface is very slick although you obviously have to know what the rules are before you apply them.
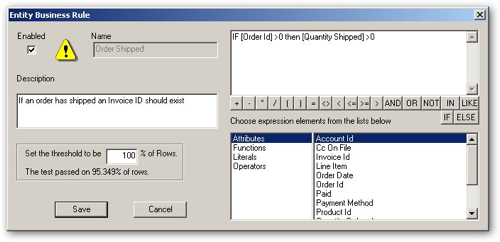
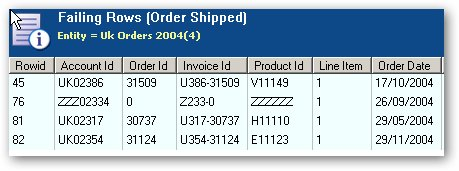
- Discovers a lot of metadata for you, suggests business rules and more appropriate data type definitions, but
- Suffers from the clunky OWB Java Interface, non-standard cut-and-paste of results and so on
- Makes you set up more profile data yourself, and involves more work in creating the profile in the first place, but
- Covers more than just Oracle databases, and
- Has a really fast, easy-to-use interface for exploring your profile information.
Well up until now, what we've been creating in the tool is referred to as a "Profiling" project, You can also create "Quality" projects are the equivalent the auto-generated OWB mappings that the OWB Data Profiler creates, except that you need to manually set all the rules and define the inputs/outputs yourself. Taking a look at one such Quality project, this cleanses names and addresses and moves the source data through a number of stages, indicated by the book icons, and transformations, indicated by the arrows.
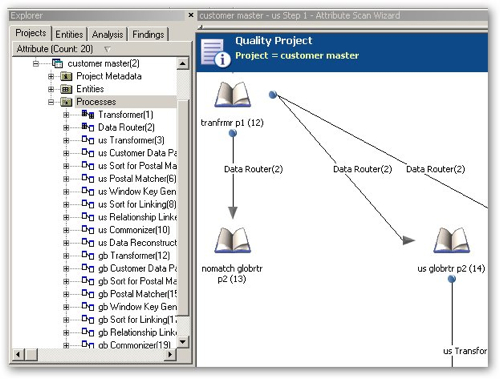
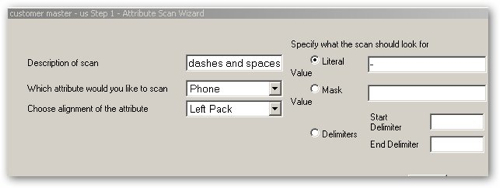
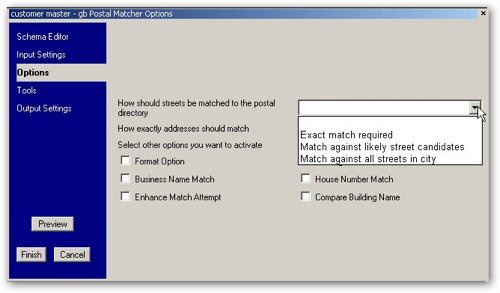
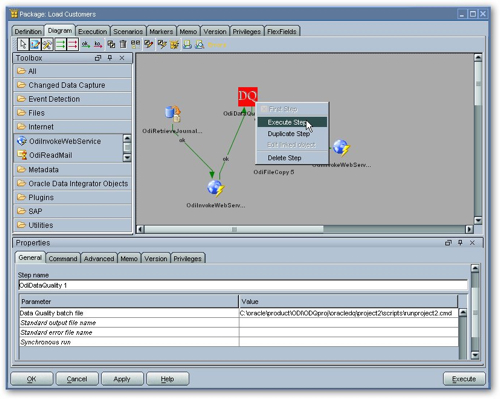
From the aspect of processing data against data rules, the "Quality" element of the ODI product, I'd say that the tool again looks very well featured, with some particularly strong support for name and address cleansing. The OWB Data Quality Option has the advantage that it generates standard OWB mappings, whereas the mapping element of ODQ is quite separate to ODI's interfaces, and of course the metadata is quite separate. The ODI OdiDataQuality tool offers basic integration between the two toolsets, also my understanding is that at some point ODQ can work off of ODI sources and targets (known as models) though I work out how to do this during my tests.
It's also worth considering how the two sets of tools are priced. According to the price list, the OWB Data Quality Option (now officially renamed the "Data Profiling and Quality Option") costs $17.5k/CPU on top of the $47.5k/CPU for the Enterprise Edition of the Oracle Database. The equivalent features for ODI are broken down in the price list into Oracle Data Profiling, which costs costs $34.5k per named user, whereas Oracle Data Quality for Oracle Data Integrator (mapping and transformation part of ODQ together with the tool you plug into an ODI package) costs $70k per CPU, which probably explains why Oracle didn't throw it into the ODI Enterprise Edition bundle. Pricing for ODI is already a little bit complex as you'll also need to license ODI Enterprise Edition itself ($23k/CPU), you can license it as an option to OBIEE or you can license Data Integration Suite for $70k, but I'm not sure if the latter includes ODQ (I suspect not, as why would you then license ODQ on it's own?). Whichever way it goes it's probably fair to say that ODQ is going to be more expensive than the OWB Data Profiling and Quality Option, but then you'd expect it as it's more of an enterprise-class solution, and these are generally priced a lot higher (think OBIEE vs Discoverer) than their historic Oracle equivalent.
Any, that's the basics on the new data quality and profiling features in Oracle Data Integrator. In a few days, I'll post something similar on Oracle OLAP and Essbase support in the recent versions of ODI, and try and wrap-up with something on the new Lightweight Designer.