Drilling Down in the Oracle Next-Generation Reference DW Architecture
If you've read this blog over the past year or heard me present at conferences on Oracle data warehouse architecture, you'll probably have seen this architecture diagram used at some point, put together by Doug Cackett, Simon Griffiths, Kevin Lancaster, Andrew Bond and Keith Laker from Oracle in the UK (and to which I had a bit of input back at the conception):
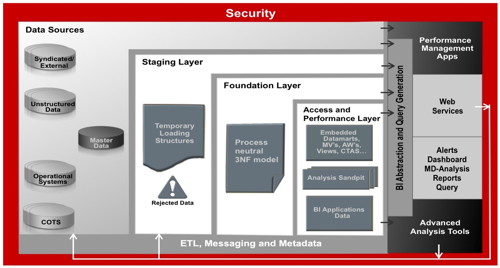
Setting aside the middleware and BI tools aspects for a while though, the data warehouse model has been something we've used a few times recently to some considerable success. When we suggest it though I tend to get a few questions about the actual details of each of the layers, and whilst Staging is fairly obvious, the purpose of the foundation and performance & access layers is sometimes initially a bit confusing and so I'll try and set out in this posting what they are actually for.
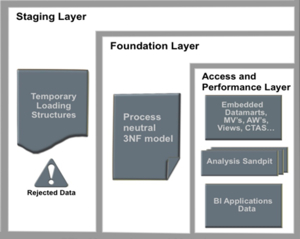
Now most people who have worked in data warehousing for the past ten years or so are aware of the dimensional modeling concept (Rittman Mead even helped to organize a seminar on this topic with Kimball University a few months ago). Dimensional modeling, with its facts, dimensions, hierarchies, drill paths and so on are a great way of presenting data out to users, and to BI tools such as Oracle BI Enterprise Edition. By embedding the drill paths in the data, and by denormalizing the data into simple tables, you make life easier for the Oracle query optimizer, you minimize the number of joins and you present users with a data model that's easy to understand. This is what we've got with the Performance and Access Layer in this model.
Whilst a dimensional model is therefore great for information access, it's not a great way to store data for the long-term, particularly if you think your analysis requirements might change over time. What if you choose to use Essbase or Oracle OLAP as your query tool, or indeed a tool like Qlikview or Microsoft's forthcoming Gemini that don't use a dimensional model? What if you want to reconfigure your stars, perhaps make what's currently a fact into a dimension, change around some hierarchies or perhaps add a new product line that has completely different attributes to your existing product dimension? If you've perhaps "painted yourself into a corner" with a dimensional model, or worse maybe aggregated your data or otherwise lost some level of detail, then making changes to your warehouse might well end up being tricky.
Because of this, the Foundation Layer in the reference architecture acts as your information management layer, storing your detail-level warehouse data in a business and query-neutral form that will persist over time, regardless of what analysis requirements and BI tools you have to support. Data in this layer is typically stored in normalized, third normal form with hierarchies stored in column values, rather than hard-coded table structures, so that it is space efficient but flexible in its design.
The Foundation Layer typically contains entities for all of the key data items in the warehouse, typically with a "current value" table and a "history of changes" table for each entity. Business keys together with source system identifiers are used in this layer, and all data should be cleansed, transformed and conformed with any erroneous data being pushed back into the rejected data area of the Staging layer. The aim for this area should be for it to be "lossless", with source system codes being retained particularly if a new, warehouse-wide coding system loses detail that might be required for future analysis. Note that in this layer, there are no surrogate keys, no slowly changing dimensions, no hard-coded hierarchies and so on as these are an aspect of dimensional modeling that should therefore only be found in the performance and access layer.
The Performance and Access Layer is where you will find your star schemas, either snowflaked or in denormalized tables, and you do everything you can in this layer to optimize your data for the query tools you are using, safe in the knowledge that you've got your original data in the Foundation layer should you need to reconfigure your stars.
My belief is that this approach has several key benefits. Firstly, as much as us OBIEE developers would like to think it's the case, not everything is a dimensional query especially once you set outside of the world of sales analysis, financial analysis and the like. If you use a toolset like OBIEE, you can provide access to both the Performance and Access Layer and the Foundation Layers within the same query environment, either by transforming the 3NF model in the Foundation Layer into a virtual star schema on the fly, or by providing access to the 3NF model in its "raw" form through Oracle BI Publisher (or indeed, Discoverer).
The key benefit though is that your data warehouse should now last beyond the immediate requirements that your users have for a dimensional model. Whilst Ralph Kimball would argue that you can gracefully adapt your dimensional model over time to incorporate changes and new data, it's my experience that this is a far trickier task that maintaining a 3NF intermediate layer and spinning off a new conformed dimensional model if your requirements change significantly. Moreover, as I said earlier not everything is a dimensional model, and if you make your warehouse data available in a query and business-neutral form as well as a dimensional form, and particularly if you use technologies such as Exadata, range/hash partitioning and the like, you should be able to provide fast query access for those users who need either transactional-level data or data that doesn't fit into a dimensional model.