Using a Process Flow to loop through Months in a Table
I hate having to maintain the same ETL logic in two different places; it violates everything I know about good coding practices. When using Java, PL/SQL, or even shell script, a good developer will modularize particular bits of his or her code to make sure distinct business logic is maintained in only one place. But this rule of thumb is difficult in ETL coding: mappings are set-based processes that encapsulate an entire load from source to target. Removing some portion of this logic into a distinct function or method, which is the paradigm for OLTP systems, usually won't scale in an ETL load. But developing one mapping that always performs efficiently no matter the data-set is also difficult: a mapping that runs efficiently for a days worth of data might not be the best alternative for running the historical load, for instance. A good example is with a partition by join process, which can cause data sets to increase exponentially with the more records that are processed.
One solution is to write two versions of the same mapping: one that executes the daily load, and one that executes the historical load, each optimized for the particular situation. But this violates the one immutable rule mentioned above: we just simply shouldn't maintain our business logic in two places. A bug-fix here and a bug-fix there, and pretty soon, one process is a rev or two behind the other. And with Agile approaches being more common in data warehouses than non-Agile methodologies, it's not uncommon to have to run historical versions of certain mappings more than once.
So I sometimes get around this by developing a single mapping within a process flow, and providing logic in the process flow that breaks up the load into sets... usually months or quarters. This allows me to optimize the mapping for smaller data-sets--which honestly is the most important--without requiring me to write it again with a different approach for the historical load. I can easily run the daily load through this same process without concern, because the process flow will simply iterate over the mapping a single time.
First, I'll create source and target versions of the SH.SALES table to use for my example. I'll also create a version of the SH.TIMES table in the source schema.
SQL> create table source.sales_stg as select * from sh.sales; Table created. Elapsed: 00:00:05.77 SQL> create table target.sales_fact as select * from sh.sales where 1=0; Table created. Elapsed: 00:00:00.09 SQL> create table source.times as select * from sh.times; Table created. Elapsed: 00:00:02.26 SQL>
I'll need to create two database functions: one that returns the distinct number of desired sets in our source table--in this case months--and another that returns the particular set based on a ranking value. This will allow me to use a WHILE LOOP activity in a process flow because I can determine: how many distinct sets to work through, and which set we should use on each iteration. I wrote these functions in generic fashion, so they are not tied to particular tables. Instead, the table name is passed as a parameter. The other parameter is the particular column I use to divide the source table into sets. In this example, the column is a DATE column, and to give me some textual attributes to use in the function, I join the source table to the TIMES table, but you could use whatever DATE dimension is currently in your warehouse.
The first function gives me the distinct number of sets in the source table. For increased performance, partitioning the source table on the dividing column is probably a good idea.
SQL> CREATE OR REPLACE FUNCTION get_num_months ( p_table VARCHAR2, p_column VARCHAR2 )
2 RETURN NUMBER
3 AS
4 l_num_months NUMBER;
5 l_sql LONG;
6 BEGIN
7
8 -- build the dynamic SQL statement
9 l_sql :=
10 'SELECT COUNT(DISTINCT calendar_month_desc) num_months '
11 ||'FROM '
12 ||p_table
13 ||' tt JOIN source.times dd ON (dd.time_id = trunc(tt.'
14 ||p_column
15 ||'))';
16
17 -- execute the statement binding the statement into a variable
18 EXECUTE IMMEDIATE l_sql
19 INTO l_num_months;
20
21 RETURN l_num_months;
22 END get_num_months;
23 /
Function created.
Elapsed: 00:00:00.42
SQL> select get_num_months('source.sales_stg','time_id') from dual;
GET_NUM_MONTHS('SOURCE.SALES_STG','TIME_ID')
--------------------------------------------
48
1 row selected.
Elapsed: 00:00:01.71
SQL>
The second produces a distinct year-month combination for each successive month that I'll be working with. This is why I use the CALENDAR_MONTH_DESC column in the function above: it's very easy to build a process that filters on a single textual column for ease of use, but you could modify the function to work on start and end dates instead. So when I'm looping through all the distinct sets in this table, I'll be passing this function a ranking number, which is the current iteration, to get back the distinct CALENDAR_MONTH_DESC column for this particular set.
SQL> CREATE OR REPLACE FUNCTION get_year_month ( p_table VARCHAR2, p_column VARCHAR2, p_rank NUMBER ) 2 RETURN VARCHAR2 3 AS 4 l_yearmo VARCHAR2(7); 5 l_sql LONG; 6 BEGIN 7 8 -- build the dynamic SQL statement 9 l_sql := 10 'SELECT calendar_month_desc ' 11 ||'FROM ( SELECT calendar_month_desc, Rownum rn ' 12 ||'FROM ( SELECT DISTINCT calendar_month_desc ' 13 ||'FROM ' 14 ||p_table 15 ||' tt JOIN source.times dd ON (dd.time_id = trunc(tt.' 16 ||p_column 17 ||')) ORDER BY calendar_month_desc )) WHERE rn = :rn'; 18 19 -- bind the statement into a variable 20 EXECUTE IMMEDIATE l_sql 21 INTO l_yearmo 22 USING p_rank; 23 24 RETURN l_yearmo; 25 END get_year_month; 26 / Function created. Elapsed: 00:00:00.00 SQL> select get_year_month( 'source.sales_stg','time_id',1 ) year_mo from dual; YEAR_MO ---------- 1998-01 1 row selected. Elapsed: 00:00:00.90 SQL> select get_year_month( 'source.sales_stg','time_id',2 ) year_mo from dual; YEAR_MO ---------- 1998-02 1 row selected. Elapsed: 00:00:00.74 SQL>
I use a bind variable for the filter on the ranking value to allow the database to only soft parse for each subsequent time it executes this function, which will be once for each distinct set. I would also recommend partitioning the source table by the column used to divide the sets, in this case, TIME_ID.
I build the following mapping to move the rows from the source table to the target table for a specific month. Notice the mapping INPUT PARAMETER operator that is being used as a filter in this operation to pull only the rows for the specific month at hand.
The source portion going into the joiner:
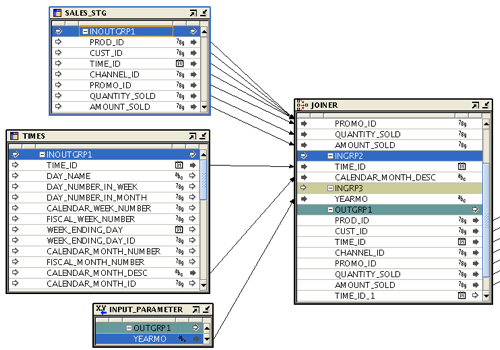
The join criteria:
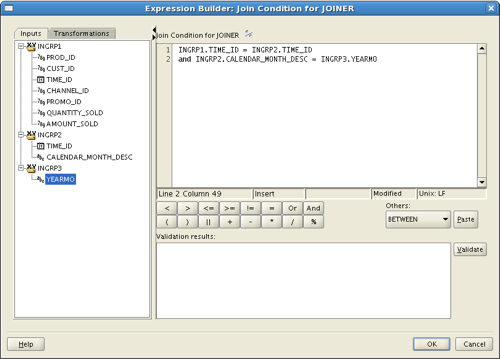
And the target portion coming out of the joiner:
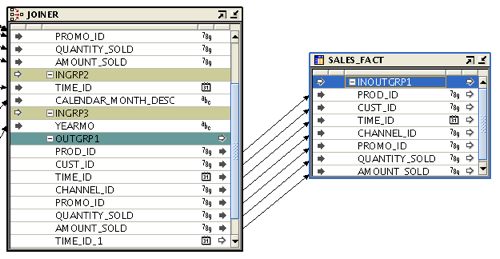
With the mapping in place, now I just need to put the whole thing together with a process flow. Note: for simplicity sake, and for ease of viewing, I didn't create any error or warning handling for this flow. Of course, I don't recommend that in practice.
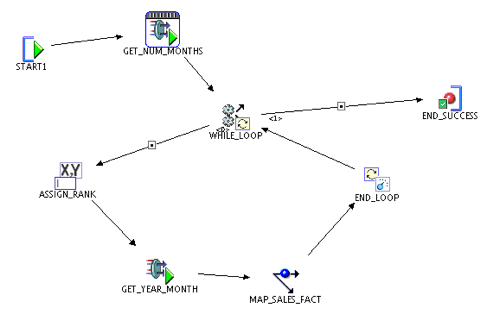
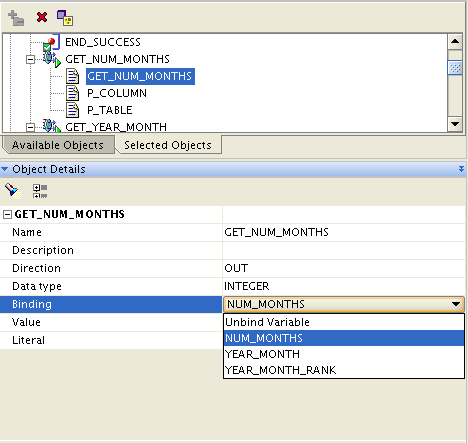
The first thing the process flow does is execute the GET_NUM_MONTHS function and store that value in a variable called NUM_MONTHS. This value is stored before the WHILE LOOP is entered, so the value persists for the entire process flow.
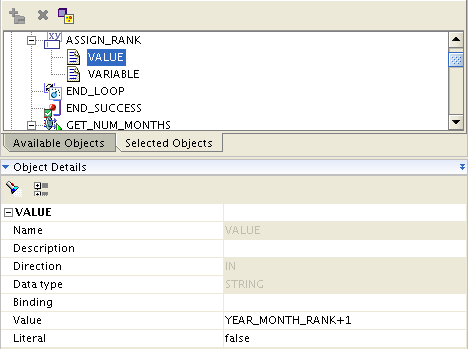
After this step, I formally enter the loop structure, and the first step is an ASSIGN activity. In this case, I am assigning the variable YEAR_MONTH_RANK to be the current value of YEAR_MONTH_RANK, plus 1. This variable starts out with a value of 0, so the first time it runs through, it gets assigned the value of 1. YEAR_MONTH_RANK is actually our iterator... it increases by one each time I loop through the process.
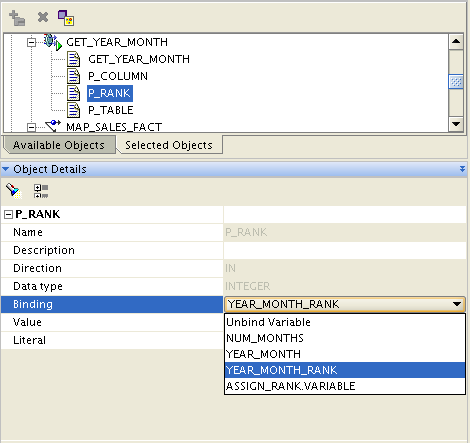
The next activity in the loop is to call GET_YEAR_MONTH, passing in the current value of YEAR_MONTH_RANK. The results of the function will give me a year-month combination, that will be stored in the variable YEAR_MONTH.
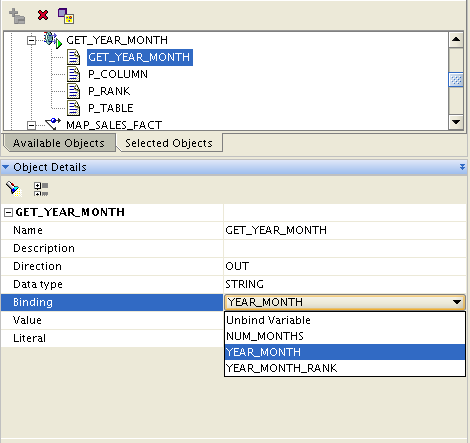
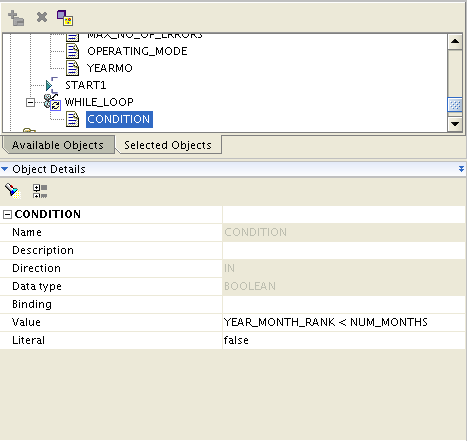
By the time the process flow executes the mapping, the variable YEAR_MONTH contains a textual attribute for the year-month combination that I want to run for this set. That variable gets passed into the mapping via the mapping input parameter, and the data set is filtered from the source table. This is a WHILE LOOP, meaning that focus stays inside the loop as long as the CONDITION is met. The condition for this loop is that YEAR_MONTH_RANK < NUM_MONTHS. So the loop will execute for every distinct month in the SALES_STG table.
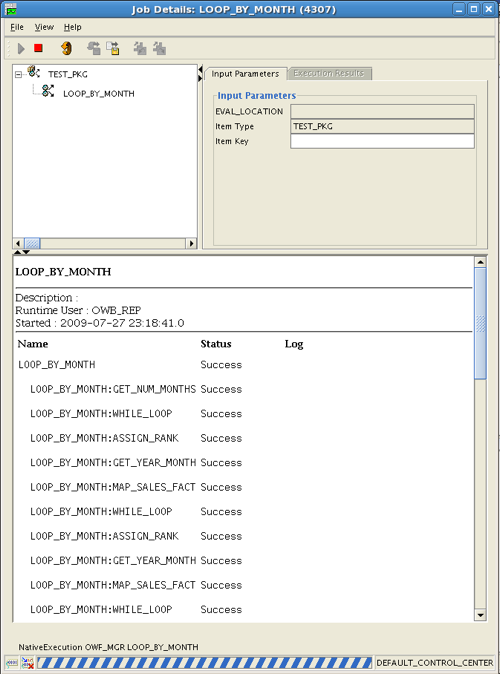
You can see from the Control Center job that the process flow is indeed looping through all the different months:
And you can also see that the count in the source and target tables is exactly the same:
SQL> select count(*) from source.sales_stg;
COUNT(*)
----------
918843
1 row selected.
Elapsed: 00:00:00.39
SQL> select count(*) from target.sales_fact;
COUNT(*)
----------
918843
1 row selected.
Elapsed: 00:00:01.65
SQL>