In the first posting in this series on code templates in OWB11gR2, I went through the background to the feature and showed how it provided access to both Oracle, and non-Oracle sources. In this posting I'm going to look at how code templates work by starting off with something simple and based just around Oracle sources and targets, then I'll make it more interesting by adding in some data from files and Microsoft SQL Server.
Working with the Project Explorer view in OWB11gR2, there's a new entry at the top of the project tree for Code Template mappings, which you can create alongside traditional OWB-style mappings to best suit the type of integration you are carrying out.
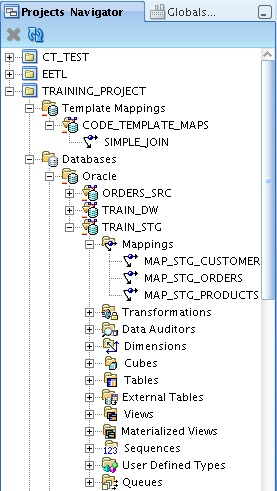
In the example above, I've created a code template mapping module called CODE_TEMPLATE_MAPS, under which I've created a code template mapping called SIMPLE_JOIN. Code template modules are associated with Agent locations (Agents are the equivalent to Control Center Services in OWB), with a default agent shipping with OWB11gR2 running on an OC4J instance.
You can of course set up agents on servers other than the one that OWB is running on, and I've heard rumours that future releases of WebLogic will ship with ODI agents built-in, which would explain why this one is running using the (now sidelined) OC4J.
To start off then, I create a simple code template mapping that moves data from two tables in one schema, through a join, into a target table in another schema. Looking at the mapping canvas, there's a couple of points to note here:
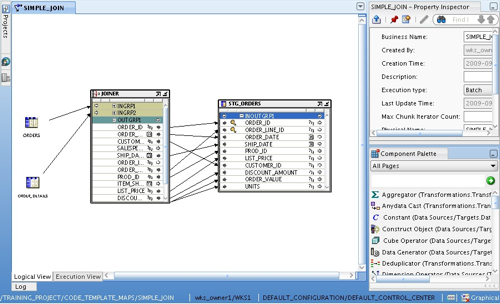
First of all, although we are using code templates, the way we lay out the mapping is exactly the same as with traditional OWB mappings. There's a bunch of transformation operators (join, splitter, deduplicator etc), source and target operators, object properties and so on. Now this is very significant, as it means that existing OWB mappings can just be cut and pasted into the code templates mapping area to transfer them across, and you can add far more complexity and logic into your mappings compared to the simple table joins and filters that you get in ODI.
The second point to note is the Logical View and Execution View tabs at the bottom of the canvas. What we are working with now is the Logical View, and this looks just like the mapping canvas that you get with regular OWB mappings. When you switch to the Execution View though, this is the place where you start to make decisions about code templates, and what are called "Execution Units".
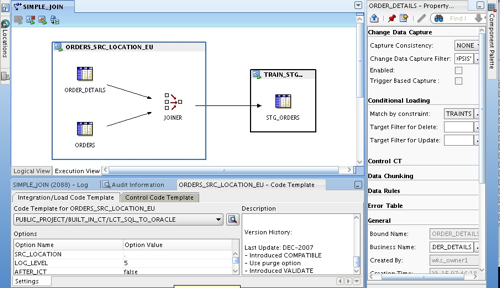
In the example above, we have two execution units, one around the source tables and their join, the other around the target table. The source tables are extracted from using the LCT_SQL_TO_ORACLE load code template, the join takes place on the source, and then data is loaded into the Oracle target table using the ICT_ORACLE_INCR_UPDATE integration code template. Now this is a bit of an artificial example as you'd probably use just a regular OWB mapping for this Oracle-to-Oracle data movement (or use an Oracle Module code template, more on this later in the week), but illustrates what extraction and loading code templates look like whilst keeping our data sources to just Oracle for the time being.
Moving back to the logical view, like regular OWB mappings you can add new columns to a table operator and then synchronize those changes outbound to the repository copy, and you can define whether the mapping operation is an update, insert, insert/update or delete. Using these settings you can define which columns are matched, which are inserted and updated when updates and inserts occur and so on, in the same way as previous versions of OWB.
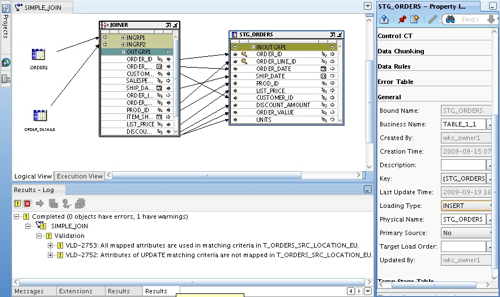
One slightly confusing thing when working with code templates though, is that certain code templates (incremental load ones, for example) require you to set update keys, column update settings and so on in separate "code template loading properties" sections, which means that you can end up defining the behavior of the load in several places some of which can appear contradictory. I'm sure it's just a case of getting used to the UI, and of course reading the instructions for the knowledge module you are using, but it is a big confusing at the start and it's hard not to always end up with lots of warning messages when you try to validate your code template mapping.
You can usually ignore these warnings though, and instead move on to the deployment and run stage. Code Template mappings are deployed using the same Control Center Manager application that you use to deploy regular OWB mappings (though they are deployed to an agent, not to a control center), and when you deploy them, OWB publishes the mapping logic, the code template, JDBC data sources and other information that the agent needs to execute the mapping autonomously from the OWB environment.
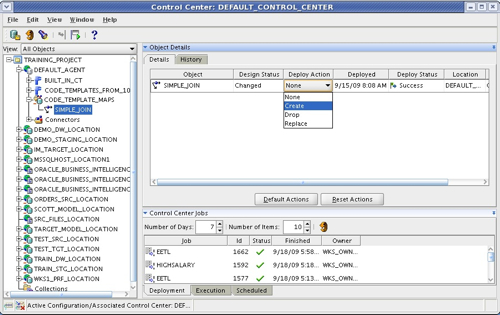
Running the mapping is done in the same way as regular OWB mappings, you just select the mapping and press the Start button. OWB then displays the outcome of the mapping (success, warning, failure) and shows you the steps it took with the various execution units afterwards.
So far, we've run a mapping where we've moved data from one Oracle schema to another using a table join. Where things start to get more interesting is when you bring in non-Oracle data (which is what this feature is really designed for). How does that work? To test this out, I have a table in Microsoft SQL Server that contains some customer data, and to keep things simple I'm going to bring what's in it into an Oracle staging table. I firstly define another SQL Server database module, and import the customer table definition into it.
My Oracle staging table has already had its metadata imported, and so I go ahead and create a new code template mapping that loads data from the SQL Server table into the Oracle one, via a filter, like this:
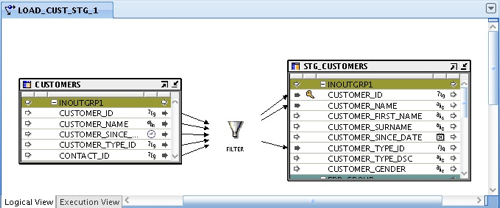
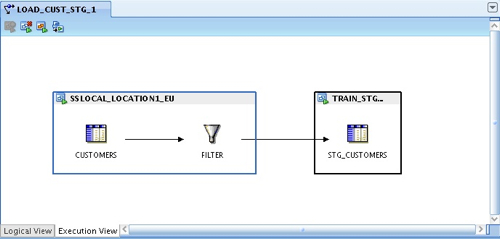
So this is the logical view, and I can drop any transformations onto the mapping (certain ones that are specific to Oracle can only be used on Oracle targets, but more on that in a moment) to create my transformation logic. Now, when I switch over to the execution view and press the button to create the default execution units, I can see that one has been created for the SQL Server source, another for the Oracle target, and the filter has been placed in the most efficient place.
The next step is to choose the code templates for each of these execution units. For the SQL Server one, I choose LCT_SQL_TO_ORACLE, like this:
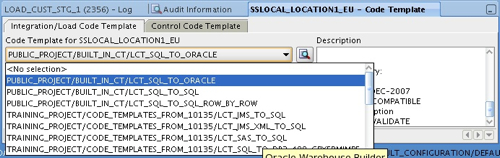
whereas for the Oracle one, I select ICT_ORACLE_INCR_UPD. Then, after I deploy the new code template mapping (along with the datasources, and the code template details) to the agent, I can run it and check that data has gone in correctly.
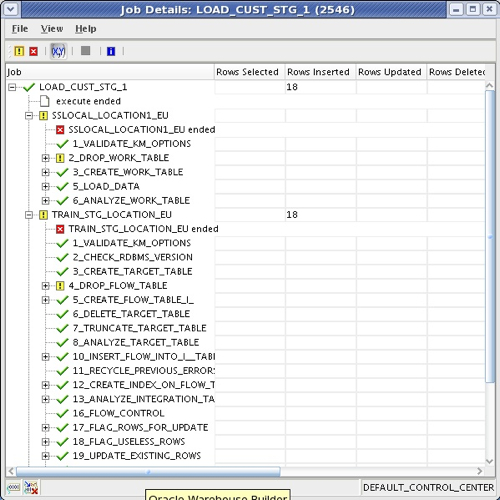
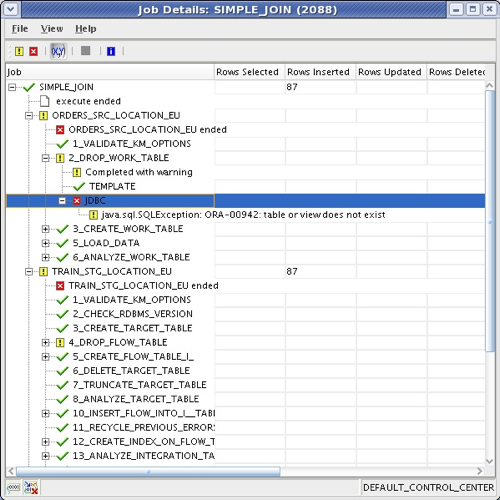
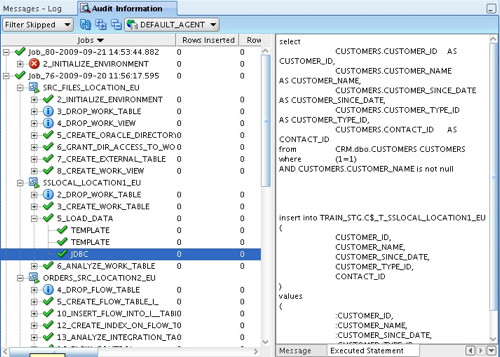
Whilst this job details view is useful, if you're used to ODI you will have used the Operator application to look in more detail at the execution of interfaces and packages, what SQL was issued and what errors might have occurred. In OWB10gR2 the equivalent screen can be accessed by selecting View > Audit Information, and you can use this screen to see the scripts that are generated, errors that occur and so on.
So far so good. What if we want to add a file into the mapping as well? My contacts information is held in a file that's currently sitting in a file module within the OWB project, like this:
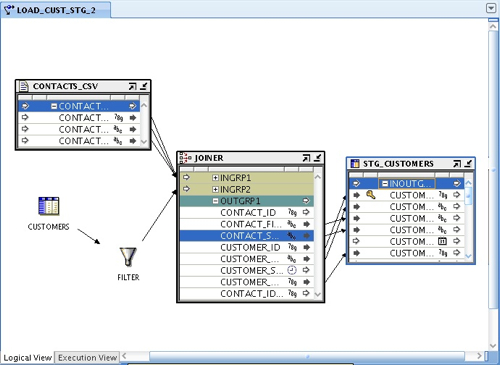
I now take a copy of my code template mapping, and then bring this file into the mapping, joining it to the SQL Server table after the filter is applied to it.
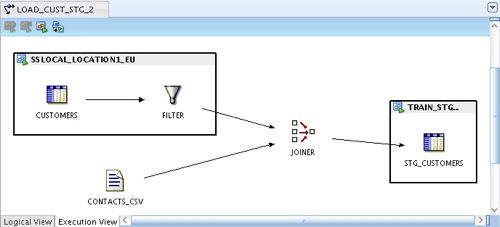
Moving back to the execution view, in the first instance the file and the joiner are outside the existing execution views.
Now as I've got an Oracle database in the mapping, my plan is to load the CONTACTS_CSV file using an external table LCT template, and to move the join into the TRAIN_STG_EU existing execution unit, so that the SQL Server file is joined to the external table over the file and loaded directly into the Oracle database.
I start this process by selecting the CONTACTS_CSV file and then pressing the "Create Execution Unit" button in the top left-hand corner.
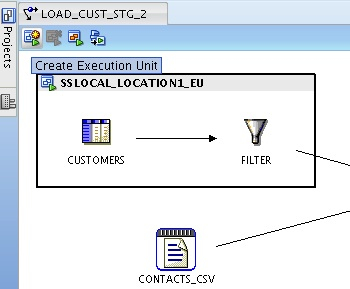
This creates a new execution unit around the CONTACTS_CSV file, and I then select the LCT_FILE_TO_ORACLE_EXTER_TABLE code template to extract from it, as this will work well with the Oracle target that I am loading in to. Setting the SRC_LOCATION option for this LCT code template to the TRAIN_STG_LOCATION used by the TRAIN_STG_LOCATION_EU execution unit will ensure that the physical external table is created in the correct Oracle schema.
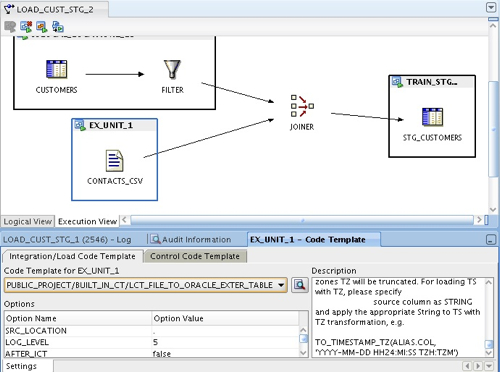
I then click on the Joiner operator, and with the shift key held down then select the TRAIN_STG_EU execution unit, and then press the "Add Operator to Execution Unit" button to add the joiner to the existing execution unit.
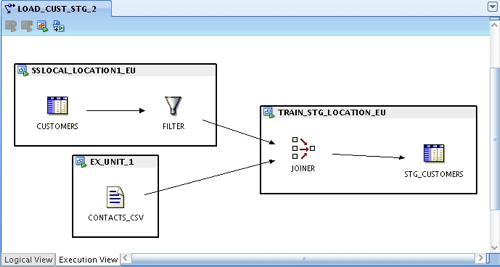
So now I"m going to natively extract from SQL Server, filter the data at the source, bring in file data via an external table and then join the lot on the Oracle database before loading into the target table.
Deploying and then running the mapping shows the new file execution unit now part of the ETL run, and if I looked at the underlying tables during the ETL run I'd see an external table being created to read in data from the contacts file.
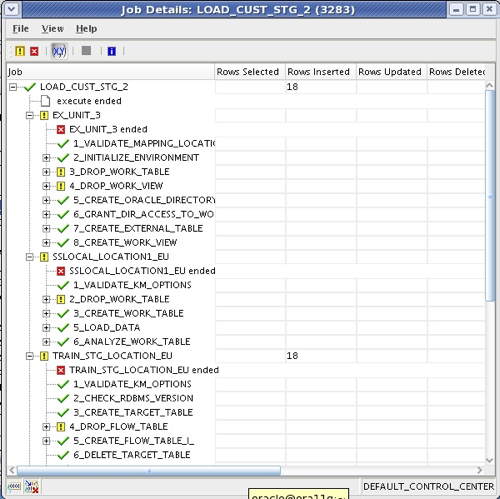
So there you go, I've loaded in some data from my SQL Server database and joined it with data from a file to load into my staging area. The last thing in this task that I now have to do is bring in some additional lookup data from an Oracle database, which I initially add to the logical view in my mapping, add into the joiner and then bring the relevant columns into the target table.
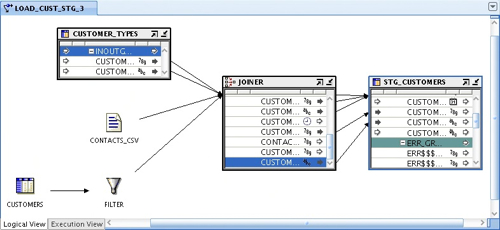
Switching now to the execution view, as before the new table is initially on its own, outside any execution units.
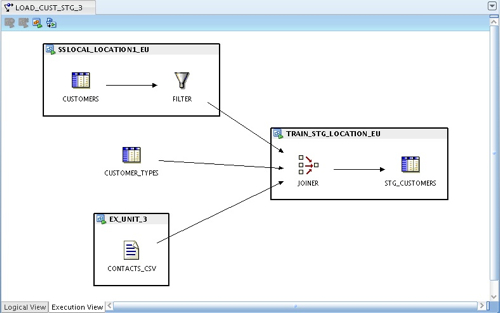
What would make sense now would be for this new table to be moved into the TRAIN_STG_LOCATION_EU execution unit, so that it can be joined to the other sources (the table is located in a different schema to the STG_CUSTOMERS table, but on the same physical database). I do this by shift-selecting the CUSTOMER_TYPES table and the TRAIN_STG_LOCATION_EU execution unit, and then pressing the Add Operator to Execution Unit button that appears in the top left-hand side menu bar, so that my execution view now looks like this:
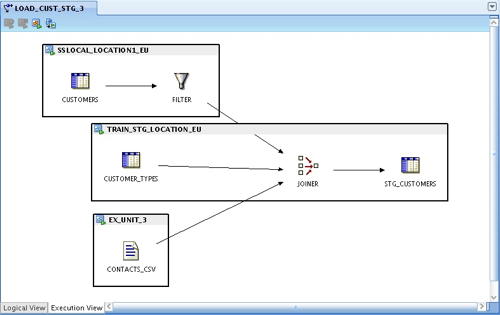
Finally, after deploying and running this new version of the code template mapping, all my data is in the staging table ready for loading in to my customer dimension, defined elsewhere in my OWB project. Which raises an interesting point: in OWB, we have got some very useful mapping operators for loading dimensions and cubes, and it would be great if we could use these as part of this set up - either by using them in code template mappings, or by including this code template mapping into a regular OWB process flow. How does this work? - check back tomorrow for the next part in this series, on OWB11gR2 "hybrid mappings".