I'm currently sitting on the plane going over to Open World, and as I've got a few hours free I thought I'd work through some of the new features in OWB11gR2. If you followed my postings a few weeks ago on heterogeneous connectivity in OWB11gR2, and the code template and hybrid mappings that accompany it, you might have seen references to changed data capture support that's based on the same technology. Changed Data Capture in OWB11gR2 uses the journalize knowledge modules (or change data capture code templates as they are called on OWB) originally supplied by Oracle Data Integrator, and this latest release of OWB ships with modules to support changed data capture against Oracle, SQL Server and IBM DB/2 databases.
So how does the feature work? Well if you've read my article on OTN on Real-Time Data Integration using ODI, it's the same technology and approach, but adapted for Warehouse Builder. To show an example, I'll be setting up changed data capture (CDC for short) against a table in a SQL Server database, and feeding the changes into an Oracle 11g database. To get things started, I create the SQL Server database module and after creating the location, I enable CDC for this database.
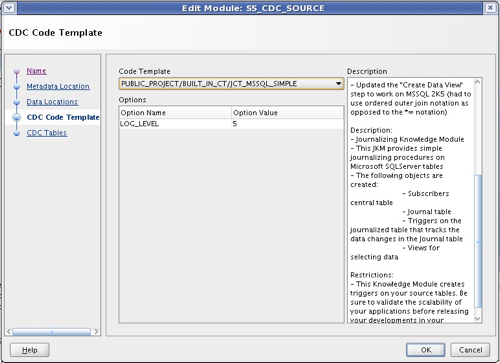
To keep things simple, I choose simple change data capture rather than the "consistent" version that takes a bit more administration and captures changes to sets of related tables. I then close the module properties and import the source tables into my project.
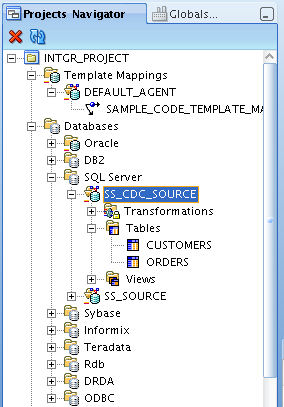
Now I've got some tables, I select one of them for changed data capture. With the "simple" CDC code template, I can capture changes for more than one table but these changes won't be consistent, so I might end up with an order for a new customer before I get the new customer's details. But for now, I just select the CUSTOMERS table for capture.
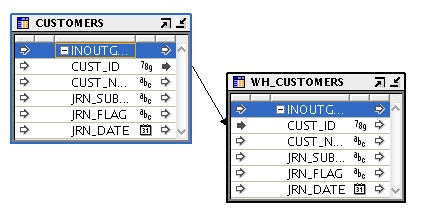
So far so good. The next step is to create a code template mapping (they have to use code templates, you can't use database-resident mappings for this) to consume the new and changed data. In this case, I simply map the incoming data into a warehouse staging table so that I can check it's coming in properly.
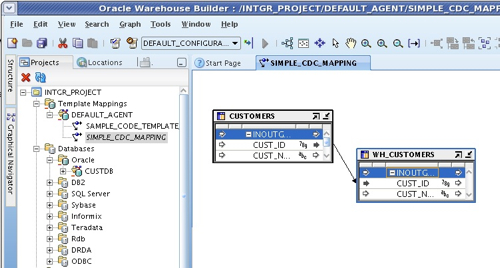
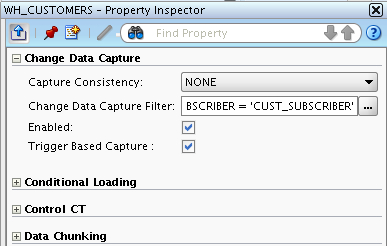
Now at the moment, the mapping knows that the source table has the potential to be tracked by CDC, but this is not enabled (in this mapping) yet. To enable it, I edit the table operator properties and tick the Enabled box for CDC. Notice the Change Data Capture Filter setting that defaults to 'SUNOPSIS' in the properties?
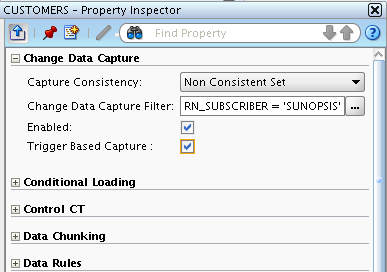
This filter is actually referencing a new column in the source table operator that appears when I turn on CDC, and I can use it to select a particular subscriber set when reading in CDC data. If I switch back to the logical view, you can see the new columns in the table operator that appeared when I turned CDC on.
Initially, the filter value is set to 'SUNOPSIS', but I'll change this in a moment once I've set up CDC on the SQL Server database and defined my subscriber group.
So far, I've been working with the logical view of my code template mapping. Now I need to switch to the execution view so that I can choose the code templates for my mapping. In terms of choice of templates, I just choose regular LCT and ICT templates as the CDC element is taken care of by my database module settings.
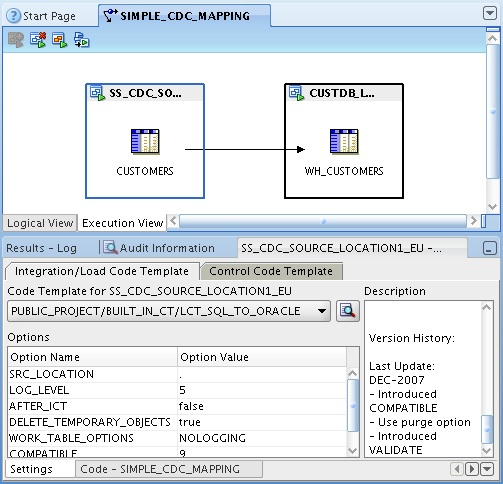
Now the mapping is set up, it's time to set up CDC on the SQL Server database. CDC on SQL Server is done using triggers on the tables we are selecting on, and to set these up you need to use a new menu that only appears on database modules that have had CDD enabled on them. I therefore right-click on the SQL Server database module, select Change Data Capture > Start, and if you're familiar with the journalize modules in ODI you'll recognize the other commands that are available.
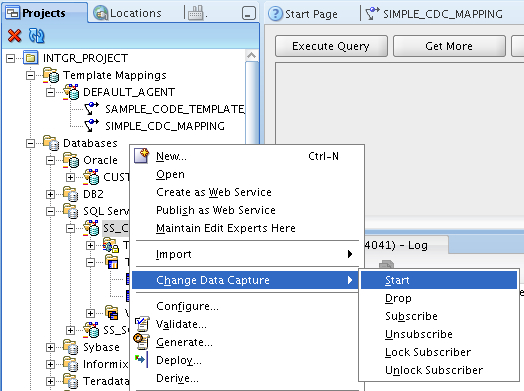
The Start option sets up the triggers and subscriber tables, whilst Drop drops them. I run the Start command and check the progress of the deployment.
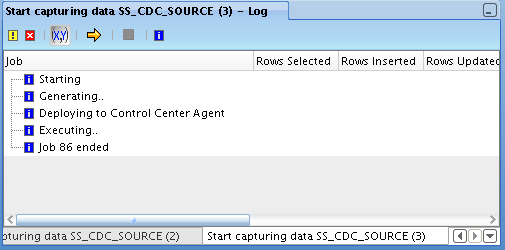
A bit ambiguous as to whether it's passed or not, but I'll work on the basis that it has and move on to the suscriber part. Subscribe lets you define one or more subscriber groups so that different mappings can consume changes at different rates, and we'll use this subscriber name to replace the 'SUNOPSIS" that the code template mapping is currently using.
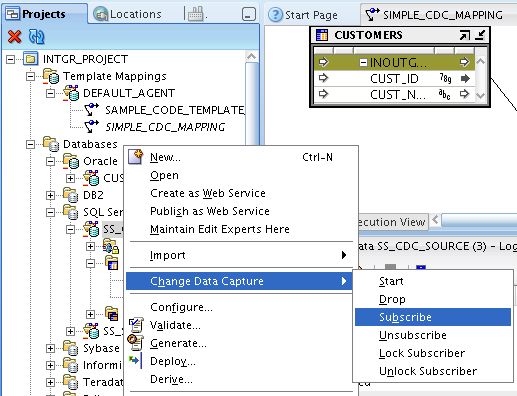
In the subscriber screen, I define a new one called "CUST_SUBSCRIBER" and press OK to save it.
Again this deploys and appears to be OK. Now I need to go back to the mapping and change the subscriber filter to 'CUST_SUBSCRIBER'.
Everything seems to be set up now, so it's over to the Control Center Manager to deploy the mapping to the default agent. This will upload the mapping logic, the code templates (if they are not on the agent already), and the JDBC data sources (ditto) so that I can run the mapping and start capturing new and changed data.
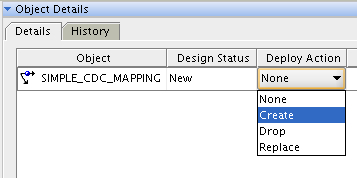
Now we're ready to go. I've got a table in my warehouse staging area that currently has no data in it.
SQL> desc wh_customers;
Name Null? Type
----------------------------------------- -------- ----------------------------
CUST_ID NUMBER(10)
CUST_NAME VARCHAR2(50)
SQL> truncate table wh_customers;
Table truncated.
I've also got a table in SQL server that will provide the changed data.
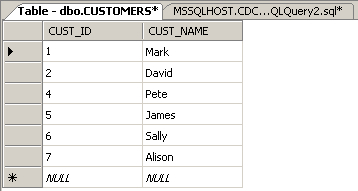
Let's put some data into it.
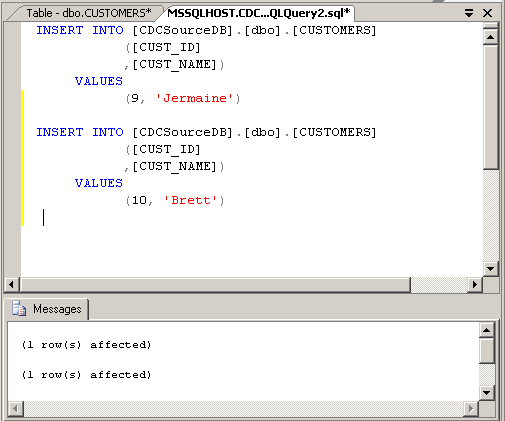
Now it's back to Warehouse Builder to execute the mapping. Whilst the SQL Server table originally had six rows in it, the test of whether CDC has worked is whether just these two new additions comes through.
I therefore go back to the Control Center Manager and execute the code template mapping.
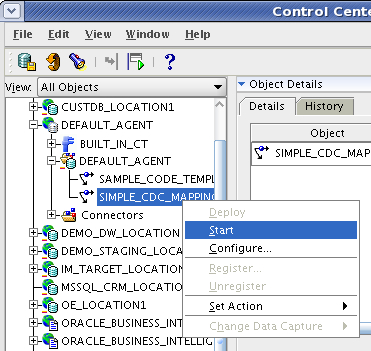
So has it worked? I check the audit log output and see that, yes, only two rows have been brought across.
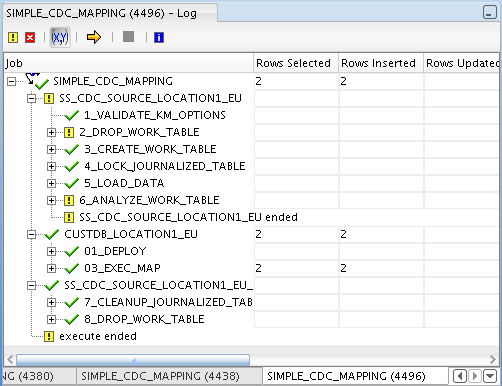
Running a quick SELECT statement on my target table shows the rows are present and correct.
SQL> select count(*)
2 from wh_customers;
COUNT(*)
----------
2
So how does it all work? Well to a certain extent, you don't need to know as the code template approach is to hide the complexity under the covers, allowing you to just concentrate on the logic of the mapping. But if you're interested, you can take a look at the JCT_MSSQL_SIMPLE that does all of the work, and see the steps that it executes.
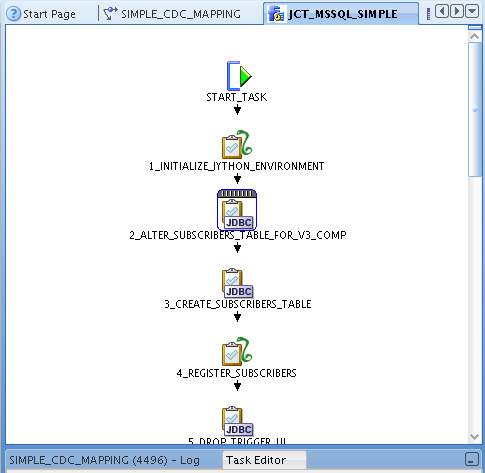
What the code template does is set up subscriber tables, tables to hold the incoming new and changed data, and triggers on the source tables to feed inserts and updates into these tables. You can view the template code that's used in the templates (I don't find OWB11gR2 as useful for viewing the actual code that's executed, which makes it a bit trickier to work out what's going on and where) but you can get the basic gist of what's happening from deconstructing the template steps.
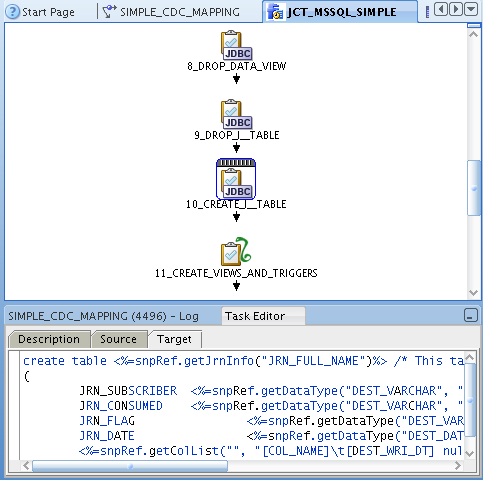
All of this will work for Oracle and DB/2 as well as SQL Server, and it should also be able to access the native, asynchronous CDC that Oracle supports as well. One thing I wasn't sure about though was how to run the Start, Drop, Subscribe and Unsubscribe commands from either OMB or from a process flow; running these from the GUI is fine for simple CDC where you just set it up and consume changes, but for consistent CDC you get two more options to extend and purge the CDC window (ODI users will be familiar with this), but without a programmatic way to run these two commands I can't see how you can use CDC consistently in OWB - in ODI you could include commands to do this in packages (the equivalent to OWB process flows) but I can't see any mention of this in the documentation.
Anyway, that's changed data capture in a nutshell. So far, I've covered OBIEE integration, heterogeneous connectivity and code template mappings, and there's one more subject I want to cover: web-service enabled mappings. Keep an eye on the blog and I'll be covering this last topic in the next few days.