One of the less well-known features in recent releases of Warehouse Builder is Data Rules, and how they can help you gracefully handle consistency issues in your data. Data Rules act as virtual constraints on your data and add error handling tables to your mappings to allow you to divert off, or reprocess data that fails one or more consistency checks. Let's take a look at an example to see how they work.
To create an example, we have a table called CUSTOMERS_TGT that has a column called GENDER. We want to enforce a data rule that says this column cannot be null. However we want our Warehouse Builder mapping to catch rows coming in that have null in this column, and replace the nulls with an "Unknown" value. To start this process we open up the target table in the Data Object Editor (I'm using version 11gR1 of Warehouse Builder, but the feature works the same in 10gR2 and 11gR2), click on the Data Rules tab at the bottom, and click on the Apply Rule button.
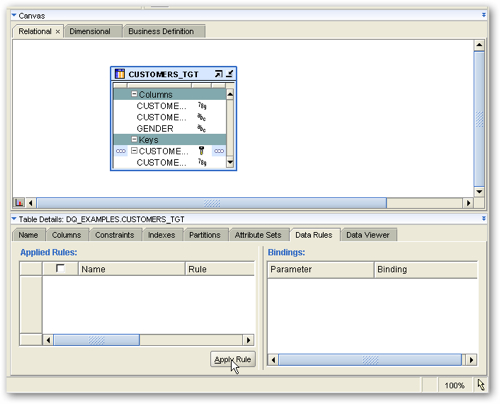
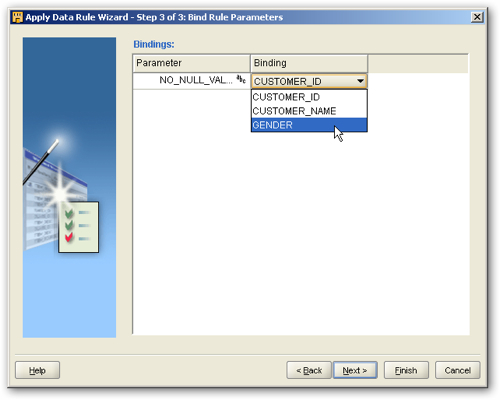
I am then presented with the first page of a wizard, and then I'm shown a list of pre-defined data quality checks that I can select from. I select the NOT NULL check and press Next to continue, I then name the data quality check and are then asked which table column the check should be "bound" to. I select the GENDER column and press Next to continue.
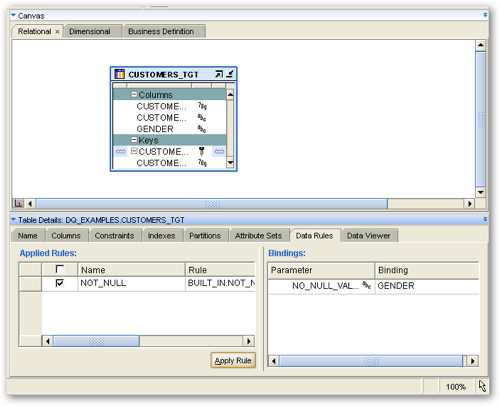
Once the wizard is complete, my table now has an entry under Data Rules, with this Not Null rule shown as applying and bound to the GENDER column.
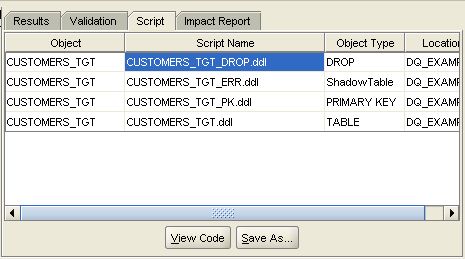
I then use the Control Center Manager to redeploy this table, not because the new data rule has caused a physical NOT NULL constraint to be added to the target table (all of these constraints are "virtual" and handled within the Warehouse Builder mapping), but because of a "Shadow Table" that needs to be deployed alongside the target table to handle the errors. You don't see this table listed in the set of tables within the OWB database module, it only appears as a script when you go to redeploy the table, but it's important you deploy this (or create your own of the same definition) otherwise the mappings later on will fail.
Note also that your target table shouldn't have a real NOT NULL constraint on it , as this can cause your mapping to fail even when error handling is enabled in the mapping, as the real constrain gets in there first before your mapping can gracefully handle the error. The target table should however have a primary key as this is used later on when moving incoming rows around that fail the error check.
Over to the mapping editor now, where I've got a simple mapping that loads from a source table into this target table. Note that my target table, the one above, has some extra rows in the table operator now due to the data rule that I've added to it.
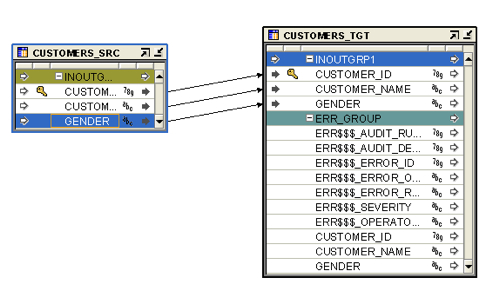
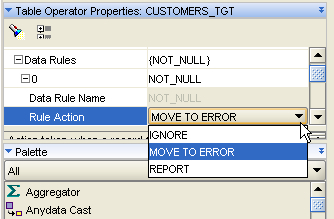
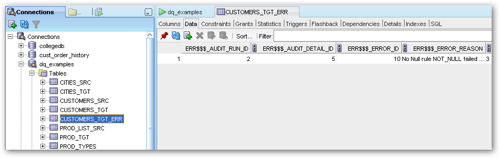
As you can see, the target table has some extra rows that are used to hold any incoming rows that fail data rule checks, with the ERR$$$ columns holding the reason for the error. Before the error handling will take place though you need to tell OWB, via the target table properties editor, to move the errors to the error handling table rather than just ignore, or report on them.
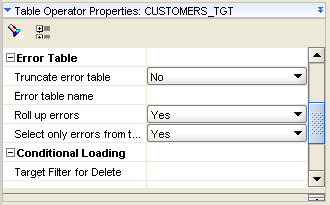
Note also the Error Table section of the table properties, which lets you substitute your own, pre-built error handling table if you want to, and to fine-tune how error records are stored in the table.
So now we're ready to go. I deploy the mapping (if the mapping deployment fails because of a table it can't find, check that you've deployed the error (shadow) table mentioned above) and then run it. Even though my incoming data had one row with a null value in the GENDER column, the mapping completes successfully.
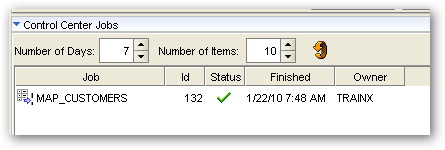
However the Job Details page shows that some incoming data was diverted to my error handling table.
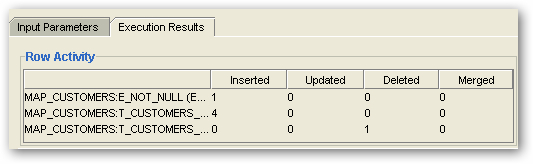
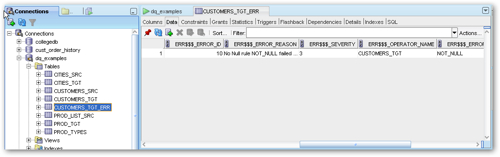
SQL Developer shows that the new error handling table does in fact contain the row that's failed the data quality check.
Checking the target table shows that all of the remaining rows are compliant with the NOT NULL data rule.
But what if we wanted to correct data that failed the check, as well as record it in this error handling table. Well, we can take the output of the error rows in the target table operator, apply a transformation to it and then load just these back into the target table, if there's a "not known" value for example that we wish to apply to values that would otherwise be null.
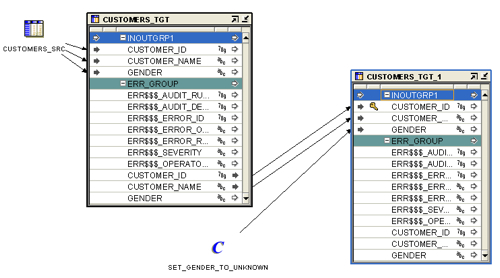
Make sure you set the error handling action of this new target table operator to also reject rows that fail the not null check (otherwise you might inadvertently add the row back with data that might still fail the data rule check).
Running the mapping again shows it executing correctly, but this time if I check SQL Developer, I can see a new row appearing that has had its otherwise null GENDER value converted to a "U", for unknown.
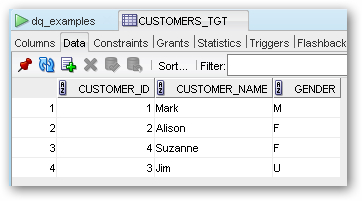
The mapping execution still added a row to the error table though for this row, so that I can see where the mapping has corrected data in the background.
The process works in the same way for other data rules you might apply, such as domain check rules, foreign key rules, "not number" rules and so forth. One thing to bear in mind though is that these mappings run in PL/SQL (as opposed to SQL, set-based) mode and therefore might not perform as well as ones without data rules applied [This was fixed from 10.2.0.3, see the note from David Allen in the comments below, these mappings now run set-based in the same way as other mappings]. However if you think about the benefits in terms of graceful error handling, the "self-documenting" nature of mappings that use this feature and so on, it's certainly a good way of handling data quality issues in your staging or integration layer before bulk-loading the data into your main warehouse tables.