Hybrid Columnar Compression in Oracle Exadata v2
Along with In-Memory Parallel Execution, another new feature that came along with release 11gR2 of the Oracle Database (or more correctly, version 2 of Exadata Storage Server) is Hybrid Columnar Compression. You'll need Exadata to use this (though at one point is was part of the standard 11gR2 database beta, without an Exadata dependency), but if you've got either the HP or Sun versions of the Exadata hardware, are running the v2 Exadata software and your database is running version 11gR2, then you can give this is a spin.
If you've been following the wider analytic database market over the past few years (Curt Monash's DBMS2 website is a good place to start), you'll probably be aware of products such as Sybase IQ and Vertica Analytic Database that store data in columns as opposed to rows. Interestingly, a lot of former ex-Oracle data warehousing server tech people ended up at Vertica, including Lilian Hobbs (author of "Oracle 10g Database Data Warehousing") , and over the past couple of years vendors such as these have achieved some success in the marketplace with their column store approach. In fact I ran an interview with Mike Stonebraker, CTO of Vertica, on this blog a few months ago (prior to the release of Exadata 2) where he set out the case for column-based storage and the "shared nothing" architecture that his product uses.
Fast forward to the weeks before Open World, and Oracle announce the Sun Database Machine and version 2 of the Exadata Storage software that comes with it. Apart from Flash Cache (primarily aimed at OLTP environments) the major innovation from my perspective, and a bit of a volte-face from Oracle, was this halfway-house approach to column-based storage which they termed "Hybrid Columnar Compression". The idea behind this is as follows:
- The Oracle database is still primarily a row-based engine, but there is a new type of segment compression that compresses data in columns
- This is only available if you are using Exadata Storage Server - Kevin Closson says that this is due to technical (as opposed to marketing) reasons
- It comes in two forms; Warehouse Compression (add COMPRESS FOR QUERY to your table definition script) and Archive Compression (add COMPRESS FOR ARCHIVE to your table script).
- Compress for query is optimized for DSS-style queries (the same market as Vertica/Sybase IQ), whilst Compress for Archive burns up more CPU but achieves greater compression than Warehouse compression.
- It all works through a feature introduced in Exadata 2 / Oracle Database 11gR2 called "Compression Units".
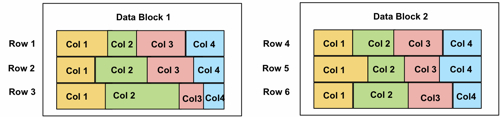
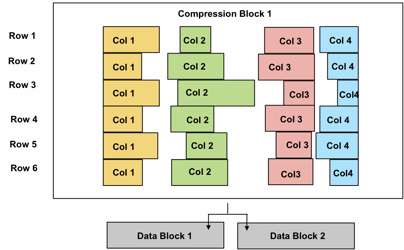
For me though, the interesting test of this will be to see how hybrid columnar compression compares to the "pure-columnar" approach used by vendors such as Vertica. I would imagine Vertica would argue that whilst its great that these compression units store their data organized by column, their approach would be superior for DSS customers as their equivalent of blocks stores just the data for individual columns, not all the columns for a set of rows. As such, their approach may well require even less disk I/O as you won't be pulling back all the (compressed) columns that are stored with the columns you require (as you do with Oracle's compression units), though I'm not close enough to either of the technologies to know if this is the case.
I doubt we'll ever really see an apples-to-apples benchmark test of both technologies side-by-side (if only because most vendors' license terms prohibit publishing benchmarks), but for Oracle customers I guess this is by-the-by; even if columnar compression isn't as DSS-efficient as pure column-based storage, it's still a huge boost to queries and it keeps it all in the familiar, manageable Oracle environment, a benefit not to be dismissed if you have thousands of databases to manage and you're aiming for vendor and hardware consolidation. For customers already sold on Exadata and SmartScan and for whom this is if anything a bit of a bonus, it'll be interesting to try this out on your own data and see how much benefit it brings.