Inside the Oracle BI Server Part 1 : The BI Server Architecture
The session that I'm giving at the BI Forum in Brighton in May is entitled "Inside the Oracle BI Server", and I'm aiming to take a closer look at the architecture and functionality of this key OBIEE component. We're all fairly aware of what the BI Server does at a high level, but I thought it'd be interesting to take a closer look at what the BI Server does, particularly when it parses queries and joins datasets together.
At a very high level, the main function of the BI Server is to process inbound SQL requests against against a virtual database model, build and execute one or more physical database queries, process the data and then return it to users. The BI Server is one part of the Oracle BI Enterprise Edition Plus product family, and presents itself to query tools as one or more databases in a simple relational (star schema) model, that can then point to a much more complex set of relational, multidimensional, file and XML data sources (and in 11g, ADF objects).
Taking the standard OBIEE architecture diagram, the BI Server sits in the middle of the OBIEE set of servers and provides the query capability, security, interfaces to data sources and calculation logic for OBIEE (all of this is based on the current, 10g set of products).
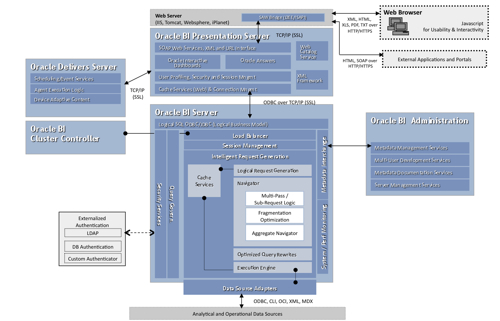
The BI Server Logical Components
Taking a look specifically at the BI Server, it has a number of logical components.
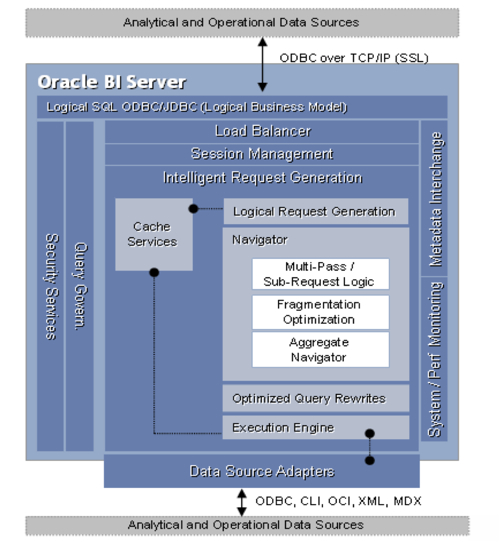
- The ODBC interface, that is used by Oracle BI Answers and other third-party tools to pass requests to the BI Server, and to receive the output from queries;
- The Logical Business Model, the three-layer metadata model that describes the data available for queries;
- The Intelligent Request Generator, a module responsible for taking the incoming queries and turning them into physical queries against the connected data source, which is made up of several sub-components including:
- The Navigator, probably the most important part of the BI Server, and the part that takes the incoming query, compares it against cached answers, navigates the logical model and generates the physical queries that will best return the data required for the query
- Within the Navigator, there are modules for determining whether multiple physical queries are needed, whether stored aggregates can be used, and whether fragmented data sources can be used for partitioned measures;
- An Optimized Query Rewrite engine for handling aggregate navigation and fragments, and for translating to the correct physical SQL dialect, and
- An Execution Engine for firing off the queries to the relational, multi-dimensional, file and XML sources required to satisfy the query.
- Cache Services stores the results of previously run queries, matches incoming SQL against that used before and returns data from the cache rather than making the BI Server query the underlying databases again
- Data Source Adapters for Oracle, ODBC, SQL Server, DB/2, Teradata, file, XML and other sources;
- System and Performance Monitoring through JMX counters and other technologies;
- Security Services for setting up users and groups in the RPD, filters, subject area security, links to outside LDAP servers and custom authenticators;
- Query Governance, for placing limits on numbers of rows returned and length of query execution for users and groups;
- Load Balancing, and Session Management
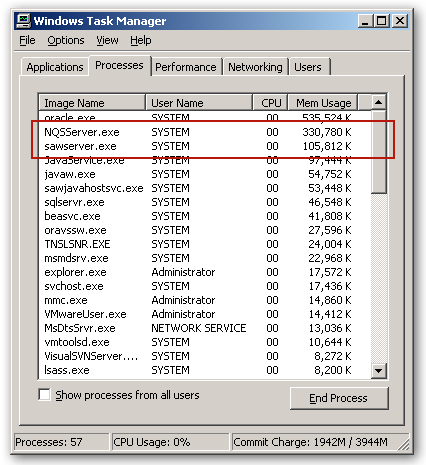
If you take a closer look at the NQSServer.exe process using a tools such as Microsoft's Process Explorer utility, you can see that it's a multi-threaded server application:
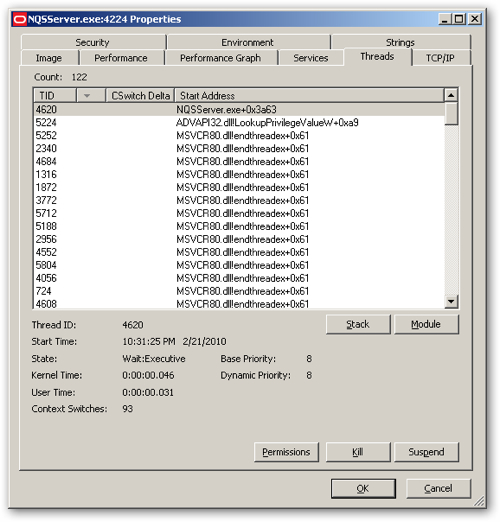
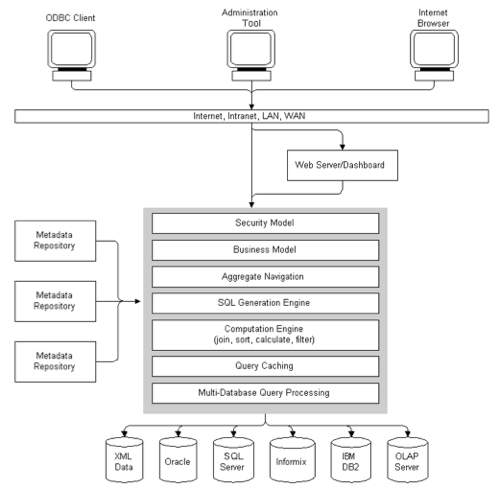
- The Security Model, presumably the users and groups in the RPD, plus the filters and subject area security in the repository;
- The Business Model, the three-layer metadata model;
- Aggregate Navigation, for rewriting queries to use mapped in aggregate tables;
- SQL Generation Engine and Multi-database Query Processing, presumably the bit that takes the database capabilities matrix and generates the correct physical SQL for the various data sources;
- The Computation Engine, for performing in-memory stitch joins, post-aggregation filters and functions, and sorting,
- Query cachiing
- The Metadata Repositories that can be connected to the BI Server (with one marked as "default", and
- The various data sources, such as Oracle, DB/2, Informix and SQL Server
The BI Server has one main configuration file, held at $ORACLEBI/server/config/NQSConfig.INI, which contains parameter settings in plain text. The full set of possible parameters are held in the Server Administrators' Guide within the Oracle docs, and this method of holding parameter settings looks like it'll be carried across to 11g, although the settings themselves will be maintained through Enterprise Manager rather than the Administration tool as is the case with 10g and earlier.
For now though, that's it for architecture and components and in the next posting, I'll be looking at how the BI Server, and in particular the Navigator, handles incoming requests.