Inside the Oracle BI Server Part 2 : How Is A Query Processed?
In the first article on this series about the Oracle BI Server, I looked at the architecture and functions within this core part of the OBIEE product set. in this article, I want to look closer at what happens when a query (or "request") comes into the BI Server, and how it translates it into the SQL, MDX, file and XML requests that then get passed to the underlying data sources.
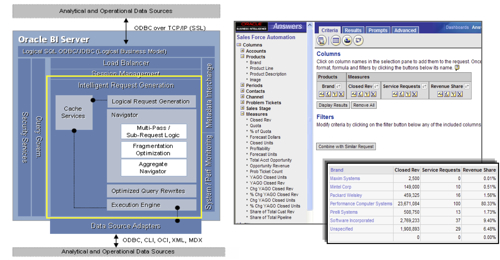
In the previous article, I laid out a conceptual diagram of the BI Server and talked about how the Navigator turned incoming queries into one or more physical database queries. As a recap, here's the architecture diagram again:
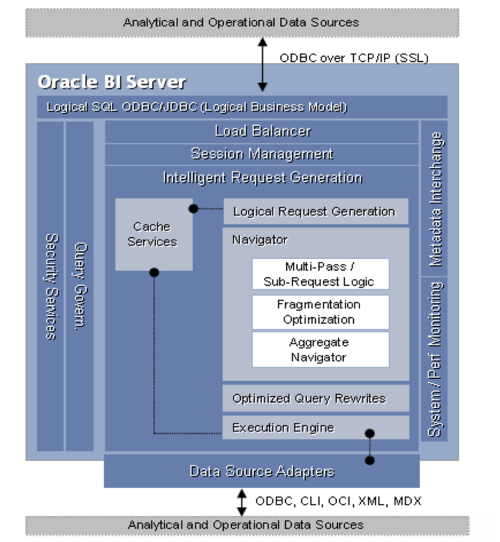
If you're used to the Oracle database, you'll probably know that it has various components that are used to resolve queries - the library cache, query rewrite, table and system statistics, etc - and both rule-based and cost-based optimizers that are used to generate a query plan. For most modern Oracle systems, a statistics-based cost-based optimizer (most famously documented by Jonathan Lewis in this book) is used to generate a number of potential execution plans (which can be displayed in a 10035 trace), with the lowest cost being chosen to run the query. Now whilst the equivalent process isn't really documented for the BI Server, what it appears to do is largely follow a rule-based approach with a small amount of statistics being used (or not used, as I'll mention in a moment). In essence, the following sources of metadata information are consulted when creating the query plan for the BI Server;
- The presentation (subject area) layer to business model layer mapping rules;
- The logical table sources for each of the business columns used in the request;
- The dimension level mappings for each of the logical table sources;
- The "Number of Elements at this Level" count for each dimension level (potentially the statistics bit, though anecdotally I've heard that these figures aren't actually used by the BI Server);
- Whether caching is enabled, and if so, whether the query can be found in the cache;
- What physical features are enabled for the particular source database for each column (and whether they are relational, multi-dimensional, file, XML or whatever)
- Specific rules for generating time-series queries, binning etc, and
- Security settings and filters
"A Day in the Life of a Query"
A good way of looking at what Oracle has termed "A day in the life of a query", is to take a look at some slides from a presentation that Oracle used regularly around the time of the introduction of Oracle BI EE. I'll go through it slide by slide and add some interpretation from myself.
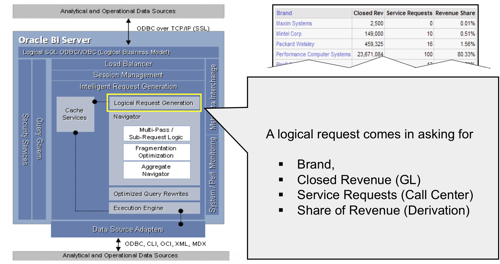
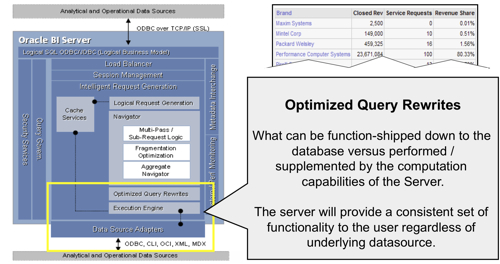
- A query comes in from Answers or any other ODBC query tool, asking for one or more columns from a subject area. Overall, the function within the BI Server that deals with this is called Intelligent Request Generation, marked in yellow in the diagram below.
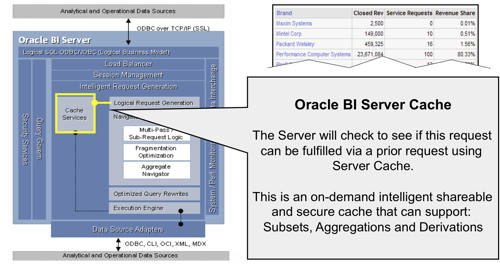
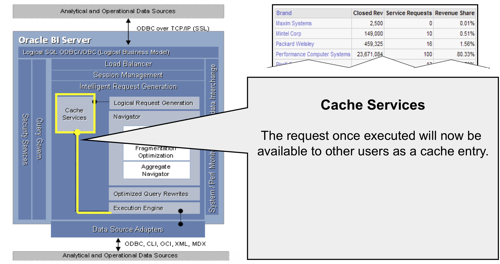
- Caching is enabled (CACHE=Y in the NQSConfig.INI file);
- The WHERE clause in the logical SQL is semantically the same, or a logical subset of a cached statement;
- All of the columns in the SELECT list have to exist in the cached query, or they must be able to be calculated from them;
- It has equivalent join conditions, so that the resultant joined table of any incoming query has to be the same as (or a subset of) the cached results
- If DISTINCT is used, the cached copy has to use this attribute as well
- Aggregation levels have to be compatible, being either the same or more aggregated than the cached query
- No further aggregation (for example, RANK) can be used in the incoming query
- Any ORDER BY clause has to use columns that are also in the cached SELECT list
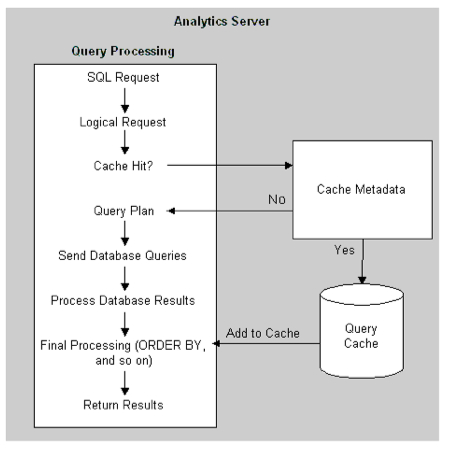
- If the cache can't provide the answer to the request, the request then gets passed to the Navigator. The Navigator handles the logical request "decision tree" and determines how complex the request is, what data sources (logical table sources) need to be used, whether there are any aggregates that can be used, and overall what is the best way to satisfy the request, based on how you've set up the presentation, business model and mapping, and physical layers in your RPD.
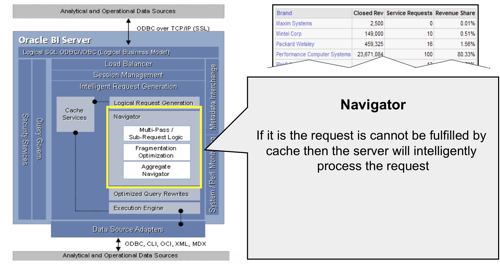
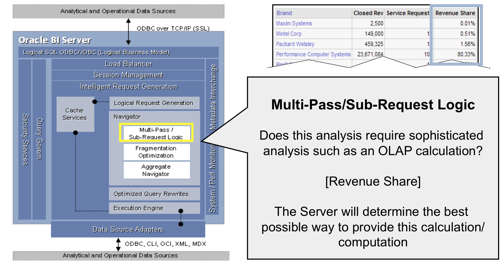
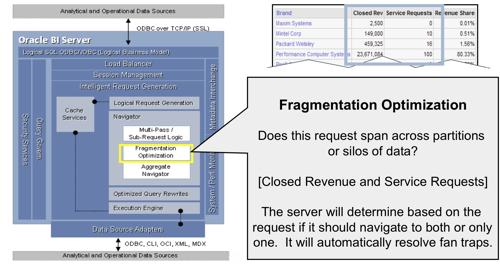
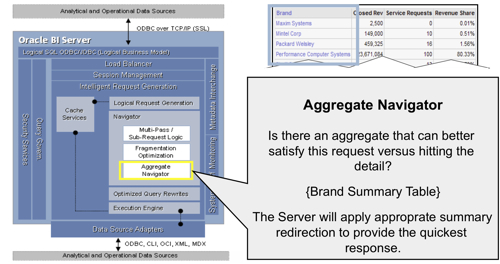
Level 5 Logging, and Logical Execution Plans
You can see what goes on when a complex, multi-pass request that requires multiple data sources is sent through from Answers and gets logged in the NQQuery.log file with level 5 logging enabled. The query requests "quantity" information that is held in an Oracle database, "quotas" that comes from an Excel spreadsheet, and "variance" which is derived from quantity minus quotas. Both columns need to be aggregated before the variance calculation can take place, and you can see from the logs the Navigator being used to resolve the query.
Starting off, this is the logical request coming through.
-------------------- Logical Request (before navigation):
RqList
Times.Month Name as c1 GB,
Quantity:[DAggr(Items.Quantity by [ Times.Month Name, Times.Month ID] )] as c2 GB,
Quota:[DAggr(Items.Quota by [ Times.Month Name, Times.Month ID] )] as c3 GB,
Quantity:[DAggr(Items.Quantity by [ Times.Month Name, Times.Month ID] )] - Quota:[DAggr(Items.Quota by [ Times.Month Name, Times.Month ID] )] as c4 GB,
Times.Month ID as c5 GB
OrderBy: c5 asc
Then the navigator breaks the query down, works out what sources, multi-pass calculations and aggregates can be used, and generates the logical query plan.
-------------------- Execution plan:
RqList <<993147>> [for database 0:0,0]
D1.c1 as c1 [for database 0:0,0],
D1.c2 as c2 [for database 3023:491167,44],
D1.c3 as c3 [for database 0:0,0],
D1.c4 as c4 [for database 0:0,0]
Child Nodes (RqJoinSpec): <<993160>> [for database 0:0,0]
(
RqList <<993129>> [for database 0:0,0]
D1.c1 as c1 [for database 0:0,0],
D1.c2 as c2 [for database 3023:491167,44],
D1.c3 as c3 [for database 0:0,0],
D1.c4 as c4 [for database 0:0,0],
D1.c5 as c5 [for database 0:0,0]
Child Nodes (RqJoinSpec): <<993144>> [for database 0:0,0]
(
RqBreakFilter <<993128>>[1,5] [for database 0:0,0]
RqList <<992997>> [for database 0:0,0]
case when D903.c1 is not null then D903.c1 when D903.c2 is not null then D903.c2 end as c1 GB [for database 0:0,0],
D903.c3 as c2 GB [for database 3023:491167,44],
D903.c4 as c3 GB [for database 0:0,0],
D903.c3 - D903.c4 as c4 GB [for database 0:0,0],
case when D903.c5 is not null then D903.c5 when D903.c6 is not null then D903.c6 end as c5 GB [for database 0:0,0]
Child Nodes (RqJoinSpec): <<993162>> [for database 0:0,0]
(
RqList <<993219>> [for database 0:0,0]
D902.c1 as c1 [for database 0:0,0],
D901.c1 as c2 [for database 3023:491167,44],
D901.c2 as c3 GB [for database 3023:491167,44],
D902.c2 as c4 GB [for database 0:0,0],
D902.c3 as c5 [for database 0:0,0],
D901.c3 as c6 [for database 3023:491167,44]
Child Nodes (RqJoinSpec): <<993222>> [for database 0:0,0]
(
RqList <<993168>> [for database 3023:491167:ORCL,44]
D1.c2 as c1 [for database 3023:491167,44],
D1.c1 as c2 GB [for database 3023:491167,44],
D1.c3 as c3 [for database 3023:491167,44]
Child Nodes (RqJoinSpec): <<993171>> [for database 3023:491167:ORCL,44]
(
RqBreakFilter <<993051>>[2] [for database 3023:491167:ORCL,44]
RqList <<993263>> [for database 3023:491167:ORCL,44]
sum(ITEMS.QUANTITY by [ TIMES.MONTH_MON_YYYY] ) as c1 [for database 3023:491167,44],
TIMES.MONTH_MON_YYYY as c2 [for database 3023:491167,44],
TIMES.MONTH_YYYYMM as c3 [for database 3023:491167,44]
Child Nodes (RqJoinSpec): <<993047>> [for database 3023:491167:ORCL,44]
TIMES T492004
ITEMS T491980
ORDERS T491989
DetailFilter: ITEMS.ORDID = ORDERS.ORDID and ORDERS.ORDERDATE = TIMES.DAY_ID [for database 0:0]
GroupBy: [ TIMES.MONTH_MON_YYYY, TIMES.MONTH_YYYYMM] [for database 3023:491167,44]
) as D1
OrderBy: c1 asc [for database 3023:491167,44]
) as D901 FullOuterStitchJoin <<993122>> On D901.c1 =NullsEqual D902.c1; actual join vectors: [ 0 ] = [ 0 ]
(
RqList <<993192>> [for database 0:0,0]
D2.c2 as c1 [for database 0:0,0],
D2.c1 as c2 GB [for database 0:0,0],
D2.c3 as c3 [for database 0:0,0]
Child Nodes (RqJoinSpec): <<993195>> [for database 0:0,0]
(
RqBreakFilter <<993093>>[2] [for database 0:0,0]
RqList <<993319>> [for database 0:0,0]
D1.c1 as c1 [for database 0:0,0],
D1.c2 as c2 [for database 0:0,0],
D1.c3 as c3 [for database 0:0,0]
Child Nodes (RqJoinSpec): <<993334>> [for database 0:0,0]
(
RqList <<993278>> [for database 3023:496360:Quotas,2]
sum(QUANTITY_QUOTAS.QUOTA by [ MONTHS.MONTH_MON_YYYY] ) as c1 [for database 3023:496360,2],
MONTHS.MONTH_MON_YYYY as c2 [for database 3023:496360,2],
MONTHS.MONTH_YYYYMM as c3 [for database 3023:496360,2]
Child Nodes (RqJoinSpec): <<993089>> [for database 3023:496360:Quotas,2]
MONTHS T496365
QUANTITY_QUOTAS T496369
DetailFilter: MONTHS.MONTH_YYYYMM = QUANTITY_QUOTAS.MONTH_YYYYMM [for database 0:0]
GroupBy: [ MONTHS.MONTH_YYYYMM, MONTHS.MONTH_MON_YYYY] [for database 3023:496360,2]
) as D1
OrderBy: c2 [for database 0:0,0]
) as D2
OrderBy: c1 asc [for database 0:0,0]
) as D902
) as D903
OrderBy: c1, c5 [for database 0:0,0]
) as D1
OrderBy: c5 asc [for database 0:0,0]
) as D1
Notice the "FullOuterStitchJoin" in the middle of the plan? We'll look into this more in the next posting in this series. For now though, this logical query plan is then passed to the Optimized Query Rewrites and Execution Engine, which then generates in this case two physical SQL statements that are then passed back, and "stitch joined", by the BI Server, before performing the post-aggregation calculation required for the variance measure.
-------------------- Sending query to database named ORCL (id: <<993168>>):
select D1.c2 as c1,
D1.c1 as c2,
D1.c3 as c3
from
(select D1.c1 as c1,
D1.c2 as c2,
D1.c3 as c3
from
(select sum(T491980.QUANTITY) as c1,
T492004.MONTH_MON_YYYY as c2,
T492004.MONTH_YYYYMM as c3,
ROW_NUMBER() OVER (PARTITION BY T492004.MONTH_MON_YYYY ORDER BY T492004.MONTH_MON_YYYY ASC) as c4
from
CUST_ORDER_HISTORY.TIMES T492004,
CUST_ORDER_HISTORY.ITEMS T491980,
CUST_ORDER_HISTORY.ORDERS T491989
where ( T491980.ORDID = T491989.ORDID and T491989.ORDERDATE = T492004.DAY_ID )
group by T492004.MONTH_MON_YYYY, T492004.MONTH_YYYYMM
) D1
where ( D1.c4 = 1 )
) D1
order by c1
+++Administrator:2b0000:2b000e:----2010/02/23 16:04:42
-------------------- Sending query to database named Quotas (id: <<993278>>):
select sum(T496369."QUOTA") as c1,
T496365."MONTH_MON_YYYY" as c2,
T496365."MONTH_YYYYMM" as c3
from
"MONTHS" T496365,
"QUANTITY_QUOTAS" T496369
where ( T496365."MONTH_YYYYMM" = T496369."MONTH_YYYYMM" )
group by T496365."MONTH_YYYYMM", T496365."MONTH_MON_YYYY"
Memory Usage and Paging Files
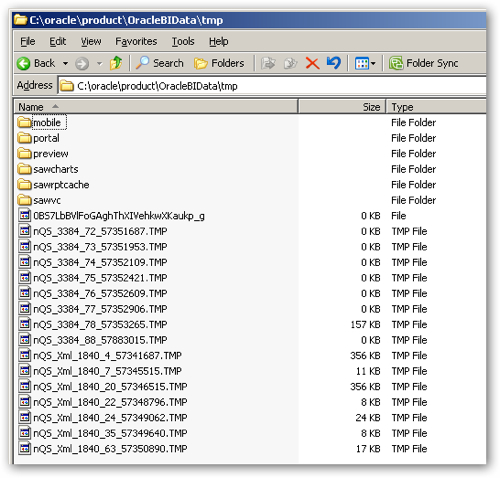
If you follow the BI Server at the process level during these steps, you'll find that memory usage is largely determined at startup time by the size and complexity of the RPD thats attached online, and then goes up by around 50MB when the first query is executed. After that, memory usage tends to go up the more concurrent sessions that are run, and also when cross-database joins are performed. You'll also find TMP files being created in $ORACLEBIDATA/tmp directory, which are used by the BI Server to hold temporary data as it pages out from memory, again typically when cross-database joins are used but also when it needs to perform additional aggregations that can't be put into the physical SQL query.
So that's the basics in terms of how basic queries are processed by the BI Server, and how the various BI Server components and engines process the query as it goes through the various stages. Again, if anyone knows any more, please add it as a comment, but for now that's it and I'll be back in a few days with part 3, on BI Server In-Memory Joins.