Real-time BI: Federated OLTP/EDW Reporting
The typical approach in Federated OLTP/EDW reporting environments is to use a BI tool such as OBIEE to do horizontal federation. This means combining data from multiple sources at the same grain in a single logical table. One note of clarification: my use of the word "federated" might be a misnomer, and I apologize in advance. As I argued in the last post, the best practice for performance reasons is to actually stream, or "GoldenGate" the source system data to a foundation layer on the data warehouse instance. But old habits die hard, so I'll continue to refer to this as "federation" even though it may not be technically accurate. Thanks for the latitude.
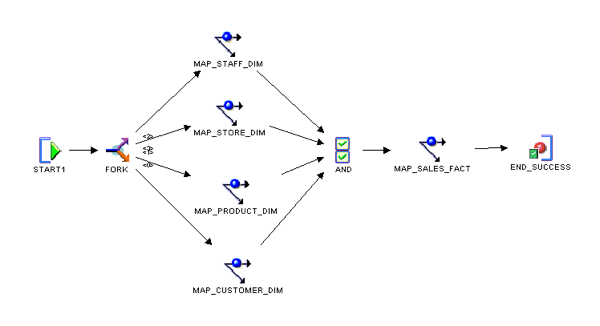
One of the sources for federation is a classic, batch-loaded EDW, with ETL processes that load conformed dimension tables, followed by fact tables that store the measures and calculations for the enterprise. Oracle Warehouse Builder (OWB), the ETL tool built inside the Oracle Database, is a standard choice for data warehouses built on the Oracle Database, and below, I show a sample process flow of what that batch load might look like:
Logical table sources (LTS’s) are a key feature within the OBIEE semantic model but are often misunderstood. Each LTS represents a single location for data to exist for either a logical fact table, or logical dimension table. A logical table in the BMM can have multiple LTS’s for any of the following reasons:
-
Including different table sources into a single logical table at different levels of granularity. Tables containing data pre-aggregated at a different level in a hierarchy is a common example of this scenario, and is known as "vertical fragmentation".
-
Including different table sources into a single logical table at the same level of granularity. Having data exist in two different locations, but wanting them to be combined in particular situations, is a common example of this scenario, and is known as "horizontal fragmentation".
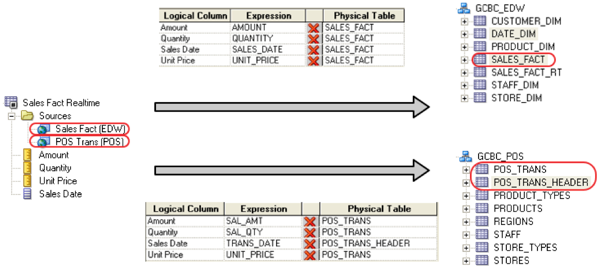
Using horizontal fragmentation in OBIEE, we can map a single logical fact table to multiple LTS’s. For example, suppose we had a physical fact table in our EDW called SALES_FACT. To represent that fact table in the semantic model, we would create a logical fact table in the BMM — called “Sales Fact Realtime” in this example — and create an LTS that maps to the SALES_FACT table. We would also map another LTS which presents this data in the source system as well. As the source system is transactional and likely exists in third-normal form (3NF), the LTS that maps to the transactional schema would likely not be a simple one-to-one relationship. In 3NF, we would likely have to join multiple tables in our source system to represent the logical fact table Sales Fact Realtime:
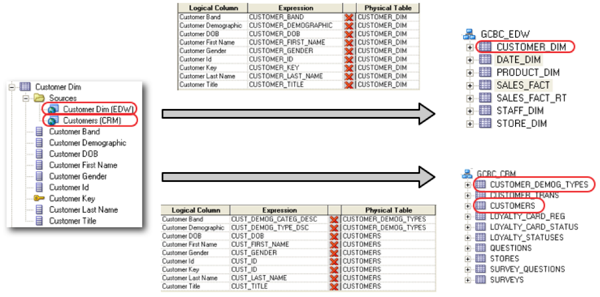
We would have to do something comparable with the Customer Dimension:
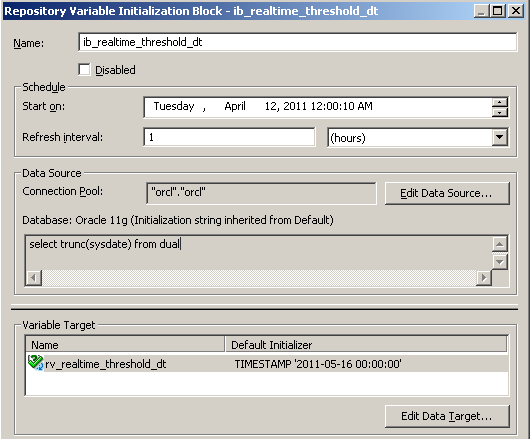
With the two LTS's, we still need to configure the horizontal fragmentation. For this implementation, I have configured a repository variable called RV_REALTIME_THRESHOLD_DT, with an initialization block that keeps the value consistently at TRUNC(SYSTDATE). I use this variable as the threshold between reporting against the EDW schema and the source system schema.
Once I have the variable available, I can configure the fragmentation on the fact table to use the threshold to determine the appropriate source for a particular record. This is less complicated with the EDW LTS... simple fragmentation configured for all rows with a transaction date less than the threshold date:
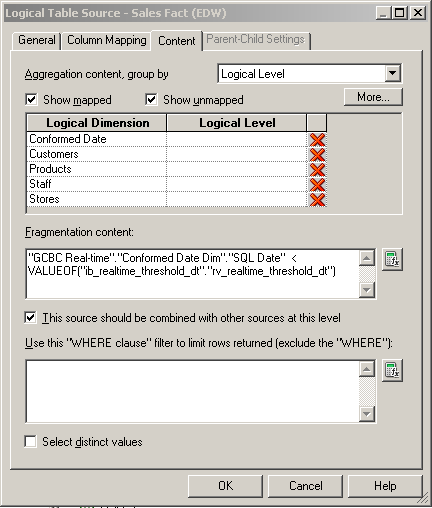
Whereas only the source system contains the newer rows needed for layering in real-time data... both the EDW and the source system contain historic data, albeit the EDW data is likely transformed to a certain degree. So we have to configure fragmentation using the RV_REALTIME_THRESHOLD_DT variable, but we also have to use that variable as a filter on the source system LTS to make sure we don't over allocate the data.
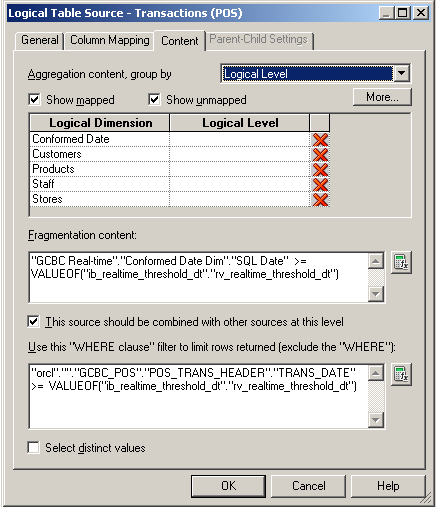
What’s the result of all this complex mapping among different LTS’s in the BMM? OBIEE understands that each source schema is completely segmented, and the tables in each LTS never join to tables in the other LTS… but they do union. OBIEE will construct a complete query against the transactional schema, in this example, joining between the CUSTOMER_DEMOG_TYPES, CUSTOMERS, POS_TRANS and POS_TRANS_HEADER tables. Additionally, OBIEE will construct another complete query against the EDW schema, in this case, only the tables SALES_FACT and CUSTOMER_DIM. The BI Server then logically unions the results between the two source schemas into a single result set that is returned whenever a user builds a report against the logical tables Customer Dim and Sales Fact Realtime. So I run the following report against my fragmented Sales Fact Realtime:
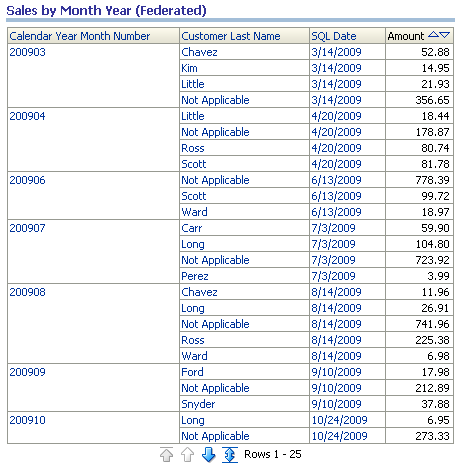
The interesting part is how OBIEE does the logical union. When the EDW and the transactional schema exist in separate databases, the BI Server issues two different database queries and combines them into a single result set in its own memory space. However, if the schemas exist within the same database, as the Oracle Next-Generation Reference Architecture recommends, then the BI Server is able to issue a single query, transforming the logical union into an actual physical union in the SQL statement, as demonstrated in the statement below. Notice that the SQL threshold has been applied, and the UNION was constructed with a single SQL statement pushed down from the BI Server to the Oracle Database holding the Foundation and Presentation and Access layers in our Oracle architecture:
WITH
SAWITH0 AS (select T44105.AMOUNT as c1,
T44042.CUSTOMER_LAST_NAME as c2,
T48199.CALENDAR_MONTH_NUMBER as c3,
T48199.CALENDAR_YEAR as c4,
T48199.SQL_DATE as c5
from
GCBC_EDW.DATE_DIM T48199 /* CONFORMED_DATE_DIM */ ,
GCBC_EDW.CUSTOMER_DIM T44042,
GCBC_EDW.SALES_FACT T44105
where ( T44042.CUSTOMER_KEY = T44105.CUSTOMER_KEY and T44105.SALES_DATE_KEY = T48199.DATE_KEY ) ),
SAWITH1 AS (select T43971.SAL_AMT as c1,
T43901.CUST_LAST_NAME as c2,
T48199.CALENDAR_MONTH_NUMBER as c3,
T48199.CALENDAR_YEAR as c4,
T48199.SQL_DATE as c5
from
GCBC_EDW.DATE_DIM T48199 /* CONFORMED_DATE_DIM */ ,
GCBC_CRM.CUSTOMERS T43901,
GCBC_POS.POS_TRANS T43971,
GCBC_POS.POS_TRANS_HEADER T43978
where ( T43901.CUST_ID = T43978.CUST_ID
and T43971.TRANS_ID = T43978.TRANS_ID
and T48199.DATE_KEY = TRUNC(T43978.TRANS_DATE)
and T43978.TRANS_DATE >= TO_DATE('2011-05-16 00:00:00' , 'YYYY-MM-DD HH24:MI:SS')
)),
SAWITH2 AS ((select concat(D0.c4, D0.c3) as c2,
D0.c5 as c3,
D0.c2 as c4,
D0.c1 as c5
from
SAWITH0 D0
union all
select concat(D0.c4, D0.c3) as c2,
D0.c5 as c3,
D0.c2 as c4,
D0.c1 as c5
from
SAWITH1 D0)),
SAWITH3 AS (select sum(D3.c5) as c1,
D3.c2 as c2,
D3.c3 as c3,
D3.c4 as c4
from
SAWITH2 D3
group by D3.c2, D3.c3, D3.c4)
select distinct 0 as c1,
D2.c2 as c2,
D2.c3 as c3,
D2.c4 as c4,
D2.c1 as c5
from
SAWITH3 D2
order by c2, c4, c3
But OBIEE is also capable of doing the fragmentation equivalent of "partition pruning." When the BI Server has enough information to know that the entire result set will come from a single source, then the SQL will be issued against only one of the LTS's. For instance, if I click on one of the "SQL Date" attributes in the above report which will apply a filter on the fragmentation column, the BI Server will know that the result set only comes from the EDW:
WITH
SAWITH0 AS (select sum(T44105.AMOUNT) as c1,
concat(T48199.CALENDAR_YEAR, T48199.CALENDAR_MONTH_NUMBER) as c2,
T48199.DATE_KEY as c3,
T48199.SQL_DATE as c4,
T44042.CUSTOMER_LAST_NAME as c5
from
GCBC_EDW.DATE_DIM T48199 /* CONFORMED_DATE_DIM */ ,
GCBC_EDW.CUSTOMER_DIM T44042,
GCBC_EDW.SALES_FACT T44105
where ( T44042.CUSTOMER_KEY = T44105.CUSTOMER_KEY
and T44042.CUSTOMER_LAST_NAME = 'Carr'
and T44105.SALES_DATE_KEY = T48199.DATE_KEY
and T48199.SQL_DATE = TO_DATE('2009-07-03' , 'YYYY-MM-DD')
and concat(T48199.CALENDAR_YEAR, T48199.CALENDAR_MONTH_NUMBER) = '200907' )
group by T44042.CUSTOMER_LAST_NAME,
T48199.DATE_KEY,
T48199.SQL_DATE,
concat(T48199.CALENDAR_YEAR, T48199.CALENDAR_MONTH_NUMBER))
select distinct 0 as c1,
D1.c2 as c2,
D1.c3 as c3,
D1.c4 as c4,
D1.c5 as c5,
D1.c1 as c6
from
SAWITH0 D1
order by c2, c5, c4, c3
Before closing this section of the real-time discussion, I want to take a minute to identify the strengths and weaknesses of this approach. As far as strengths go, we have several items that register with this solution. First off... this is a low-latency solution. When using the Oracle Next-Generation Reference Architecture, we have the latency of streaming, or "GoldenGating," the content from the source system to the DW database. With clients we've had in the past, this can run anywhere from a few seconds to several minutes, depending on the solution implemented. Additionally, there is no complex logical or physical data modeling and supporting ETL to deliver this solution, as there is with the EDW with a Real-Time Component, which we will explore in the next posting.
As far as weaknesses go, there will be a fair amount of complex RPD semantic-layer modeling. Obviously, the degree of difficulty depends on a number of factors: number of source systems integrated, number of subject areas, complexity of reports delivered, etc. Also, increased complexity of RPD modeling may introduce performance degradation as OLTP schemas have to be transformed "on the fly" to star schemas by the BI Server. But keep in mind... we are typically only doing this for at most a day's worth of data, so with proper database tuning, this content can usually perform quite well.
Next up: EDW with a Real-Time Component