Hyperion Profitability & Cost Management - Overview
Recently i have been doing lot more work on the Oracle EPM stack than on the Oracle BI stack. So, i will be writing more on the various Oracle EPM products like HFM, Planning, FDQM etc in the forthcoming weeks. To sort of kick start the series of postings, i thought i will begin an article on Hyperion Profitability & Cost Management also popularly known as HPCM. It is one of those products that is often overlooked, due to the overlap of features it has with other products like Essbase & Planning. It is sort of a targeted product with a solid technical foundation and uses Hyperion Essbase as its backend. On the outset, HPCM primarily provides Functional Users with the ability to automatically allocate Costs & Revenue to various departments, accounts thereby giving the ability to do proper & complete profitability reporting.
HPCM primarily has 3 main sweet spots
-
Every company will have indirect costs. For example, a Consulting company where Revenue is obtained through driving projects will have a lot of indirect costs like HR Costs, Admin Costs etc. HPCM provides an ability to allocate the costs back to the projects so that proper project profitability is derived. How the costs are allocated will be defined through HPCM itself. For example, if a company is running say 3 consulting projects with 20, 30 & 40 resources each, then the indirect costs are allocated back to the project based on the number of people(or time logged etc) in each project.
-
Every company will be storing the incoming Revenue & Costs in a Ledger. Due to various reasons, even the direct costs & revenue might not actually be tied back to a project (Consulting company example above). So, there might be a need to allocate the project based Direct Costs & Revenue as well to the Projects (allocation possibly by head count etc).
-
Allocation of Costs is pretty dynamic in nature depending on the type of business. It can vary quite frequently. So, the key is to ensure that the allocation logic can be changed frequently and easily. In addition, one more key point is to find the lineage back to the source on how the costs are obtained.
HPCM provides all the 3 above. If you are an Essbase or a Planning person, you could argue that we can do the same thing using these 2 products itself. Though true, in many cases Cost & Revenue allocation rules are defined by Functional Users. So, it is not possible for Functional users to create Business Rules/Calculation Scripts every time there is a change. In addition though Essbase is very good, it is very difficult to do a data lineage from a calculation script, to find out how the costs are allocated. Thats the main reason why, HPCM is a solution positioned primarily at Business/Functional users for providing that cost & Revenue Breakdown.
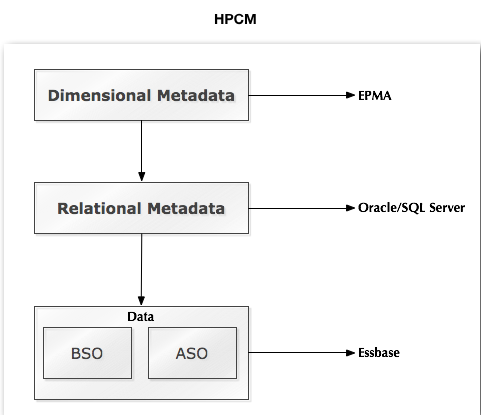
Though i have mentioned that HPCM is a functional tool, its underlying technology is very interesting. It has a relational metadata that stores the metadata related to HPCM. In addition each HPCM application will have 2 Essbase databases. One is Block Storage cube which will be used for the allocation & calculations. The other is a reporting Aggregate Storage cube which will be used for reporting. Data push from BSO and ASO is automatically available out of the box from HPCM. Also, one important point to note, change to dimensions, change to metadata, pushing data from BSO to ASO are all achieved within HPCM without writing any external code/scripts. Everything is done out of the box. This architecture is shown below.
-
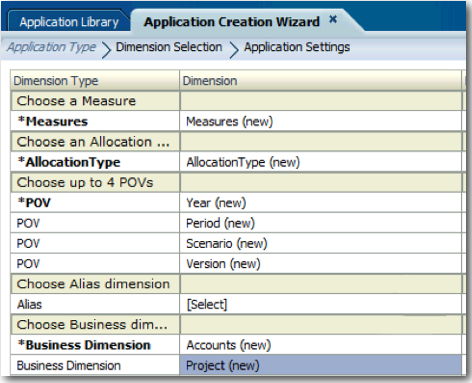
System Dimensions - There are 2 System Dimensions - Measures & AllocationType. Generally while creating a HPCM application through the Wizard we can pre-create these 2 dimensions. AllocationType is used by HPCM internally for doing allocations. It is generally not needed to make any changes to this dimension. But Measures dimension is the most important dimension that HPCM uses for pushing costs & allocating them. We can create custom members in the Measure dimension if needed.
-
POV Dimensions - HPCM supports upto 4 point of view dimensions. These dimensions are generally for storing Year, Period, Scenario & Version. True to their names, they generally are used as POVs and are not used directly in any allocation (the POVs are always fixed in the calculation scripts).
-
Business Dimensions - Business Dimensions are those dimensions where allocations happen. These dimensions drive the allocation logic.
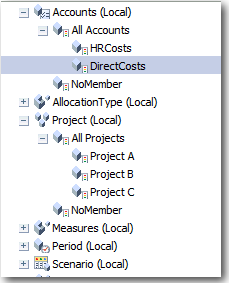
In addition HPCM also supports alias and attribute dimensions. For this article, i will use a simple case of demonstrating how to go about allocating HR Costs in a Consulting Company recognising its revenue through Projects. Lets make an assumption that on a monthly basis we record the HR Costs (including Salary paid to HR, other misc costs) etc. Lets also assume that we have 3 projects running in the company with the following break-up
a. Project A - 300 people full time
b. Project B - 500 people full time
c. Proejct C - 200 people full time
We will start off with creating the application through the Application Wizard (pre-create System Dimensions) and then we shall define the necessary dimensions.
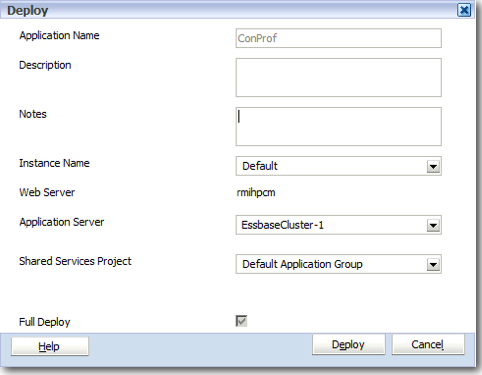
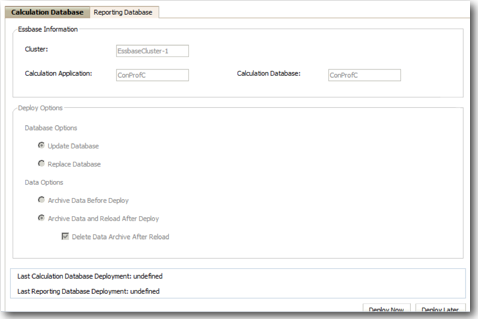
Lets deploy this application and then login to the application through Workspace.
-
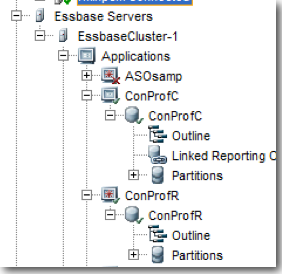
There will be 2 essbase databases one suffixed with letter C and the other suffixed with letter R. C database is the Block Storage database that is used for allocation. R database is the Aggregated Storage database that will be used for reporting.
-
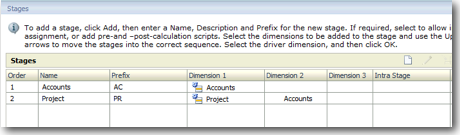
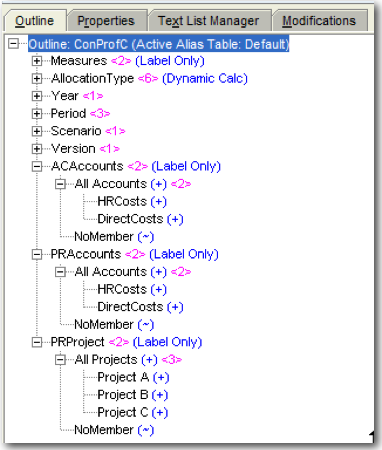
You will notice that for each stage there will be a corresponding set of dimensions prefixed by the Stage prefix given at the time of creation. So effectively, if there are 2 stages with 2 dimensions each, then Essbase will have 4 dimensions (though the 2 dimensions might be the same in EPMA).
-
You will also notice that each dimension will have a dummy member called NoMember. This is one of the most important members that controls the grain of the data. This member is the key in loading multi-grain data for allocation into HPCM.

-
Manual Data Entry - HPCM provides a screen where we can update data manually.
-
Staging Tables - We can load the data temporarily into a set of staging tables, and then from within HPCM we can push the data from Staging tables into Essbase.
-
Directly loading data into Essbase
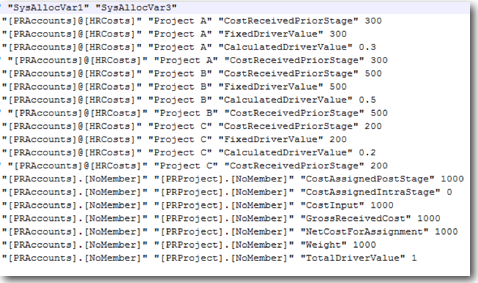
In our case, we will load the data directly into Essbase as that will give more clarity on how HPCM works. For doing data load for Stage 1, remember we have a total of 9 dimensions in Essbase (Measures,AllocationType,Year, Scenario, Period, Version, ACAccount,PRAccount,PRProject). But our input data of HRCosts comes at a grain of only 7 dimensions (Measures,AllocationType,Year, Scenario, Period, Version, ACAccount). So, load this in we will have use the NoMember intersection of the remaining 2 dimensions (PRAccount & PRProject). The input data file to Essbase is shown below
CostInput,DirectAllocation,2011,Jan,Actual,Working,HRCosts,[PRAccounts].[NoMember],[PRProgram].[NoMember],1000
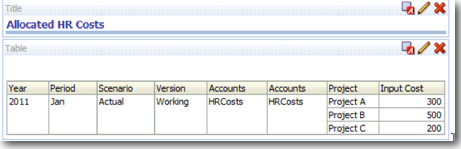
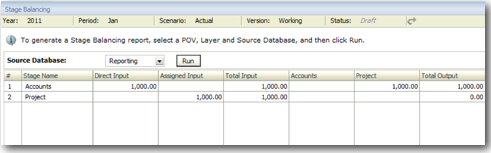
Our idea is to allocate the 1000 USD down to the 3 projects for the January Month. So, our end result should look like this
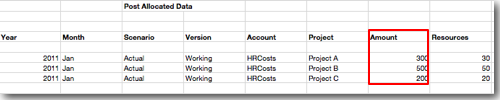
FixedDriverValue,DirectAllocation,2011,Jan,Working,Actual,HRCosts,HRCosts,Project A,300
FixedDriverValue,DirectAllocation,2011,Jan,Working,Actual,HRCosts,HRCosts,Project B,500
FixedDriverValue,DirectAllocation,2011,Jan,Working,Actual,HRCosts,HRCosts,Project C,200
Weight,DirectAllocation,2011,Jan,Working,Actual,HRCosts,[PRAccounts].[NoMember],[PRProgram].[NoMember],1000
In the above data file there are 2 things we can notice
-
We have used a measure called FixedDriverValue and Weight. We will see their significance a little bit later. For now think of them as intersections that will hold the Resource Count Data.
-
The first 3 records above have HRCosts repeated twice to load into both the Accounts dimension we have in the Essbase Cube. Again we will see the significance of why we are doing this below.
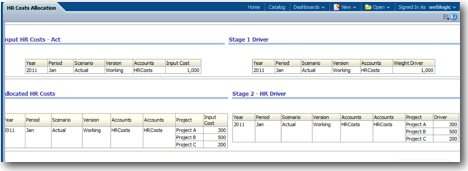
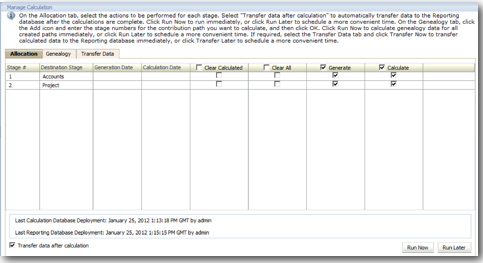
So far we have loaded all the necessary data into the Essbase Cubes and have also setup the stages. The next step is in defining the Allocation Logic. This is done through a concept called Drivers. From the Perspective of HPCM, drivers define how the allocation values get pushed from source to target. HPCM supports different allocations like Activity Based Costing etc through the concept of Drivers. In our case, the Driver for allocation is the Resource Count. Just to recap, within Essbase now we have dimensions catering to two stages - Stage 1 and Stage 2. This is illustrated below. So basically we have 3 separate sub-cubes each having its own intersection.
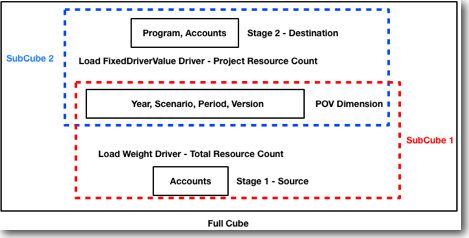
-
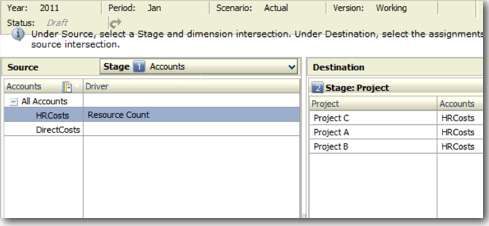
Allocation Based on Source - Here all the driver values are obtained from the source stage and data from source stage is then assigned to the Destination Stage based on the Source driver values.
-
Allocation Based on Destination - Here all the driver values are obtained from Destination stage and data from source stage is then assigned to the Destination Stage based on the Destination driver values.
-
Allocation Based on Source & Destination - Also known as Assignments - Here all the driver values are obtained from the intersection of Source & Destination and data from source stage is then assigned to the Destination Stage based on the Assignment driver values.
If you look at our Driver data above (3 records containing FixedDriverValue & 1 containing Weight), you can see that our driver (Resource Count) is loaded in 2 ways. First the FixedDriverValue is loaded at the intersection of Source & Destination stages. The second driver Weight is loaded at the Source Stage intersection. We have chosen these 2 measures (FixedDriverValue & Weight). We could have chosen any other measure like Rate, Volume etc. But each measure has a logical meaning and it is better to stick to the ones we think is logically close to what we are trying to do. If we are not able to use the existing measures and if they don't relate to our driver names then we can create custom measures. So, this allocation handling through drivers is defined through the Driver Definition screen in HPCM.
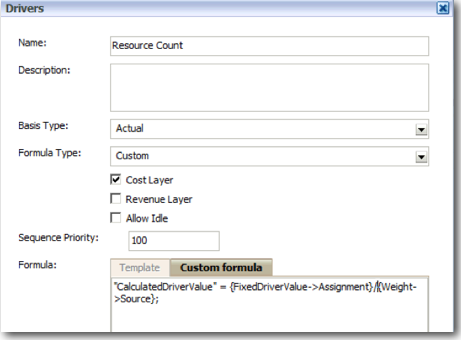
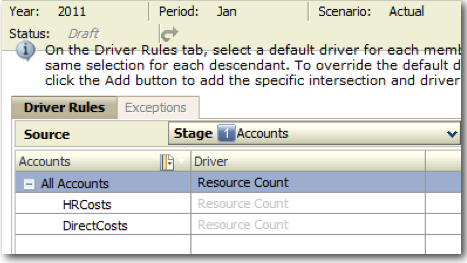
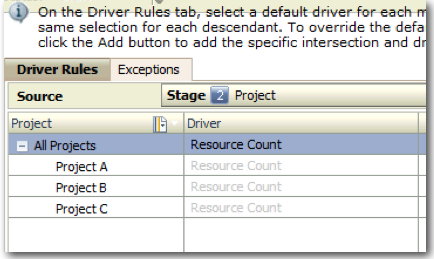
Once we have defined the driver the next step is to assign the driver to both the stages. HPCM allows us to have multiple drivers for each stage. And even within a single dimension in a stage we can define exceptions so that multiple drivers can be assigned within the same dimension. This way we can have allocation logic based not only on Resource Count but also on say Clocked Time of a resource in certain cases. Driver assignment is done through the Driver Selection screen in HPCM.
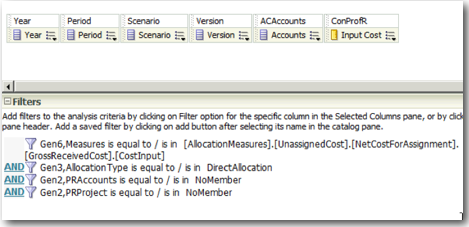
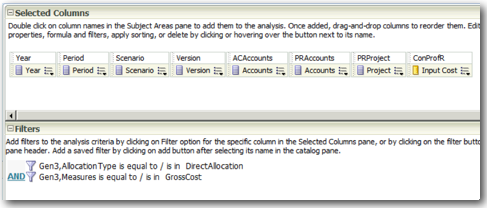
We start off with importing the ASO cube into BI EE which is pretty straight-forward as shown below.