Oracle Data Integrator Topologies for OWB Developers
Back in October of 2011 I posted the first part of a series of blogs that aimed to describe some of the key features of Oracle Data Integrator (ODI) from the point of view of an ETL developer who already knows Oracle Warehouse Builder (OWB). The blog series was themed to tie in with a presentation I was delighted to give at the RMOUG Training Days last month.
Before I begin this piece on Topology I want to briefly mention that ODI 11.1.1.6.0 was released a couple of weeks ago. Some of my colleagues are taking a deeper look at the new features of this release and no doubt they will feature on the Rittman Mead blog soon. However, if pressed for my top three new features (and I like far more than just 3!) I'd say:
- Tracking Variables in the Operator Logs. Optionally (by setting a log level for the execution), the value of any variables used by a process are shown on the operator log for the execution. In older versions of ODI the only way to see a variable's value was to historize it and then inspect it from the Designer navigator which could well expose far too much detail to staff that do not need to see the design, and, of course, in 'Execution Only' repositories the Designer Tab is absent so variables are impossible to see!. Some variables need to be kept secret (passwords for example) so a new setting (Secure Value) on the variable will prevent it being recorded.
- Global Knowledge Modules. Often in an ODI development there is a need to adapt an existing KM to make it better suited for a task - this might be: adding extra steps to audit something, a work around for a limitation in the technology or to put in some platform specific performance enhancement. Until now Knowledge modules were held at the PROJECT level of an ODI implementation and if you needed the same KMs in more than one project you would need to import and store copies of it in each project which, of course,makes more work when changes to the KM need to be implemented.
- My final pick is the Groovy Editor. I just love the ability to script… what more can I say?
Topologies
When you start out on a ODI development the first Navigator you need to work with is the TOPOLOGY Navigator. This is where ODI defines where to find the sources and targets of the data that you are integrating; as you can appreciate this is the crux of what you are implementing. In the OWB world the project comes first and under this is a technology (read database vendor) where we store tables, mappings and the like. In ODI we take a much more compartmentalised approach with the use of physical and logical architectures - the physical describes the technology and the connection, the logical describes it in terms that we will use in the Designer Navigator. This, together with ODI contexts makes our model very flexible we can change a context and connect a logical source to another physical source - in fact we could even use another technology, for example we have worked on projects where the source database was either Oracle or Microsoft SQL server and by changing a context we swap source technologies.
The Topology navigator has tabs (or in current ODI speak, accordions) to allow us to define Repositories, Contexts, Physical and Logical Architectures, Languages and Generic Actions. For this blog I will stick to the things we need to get started on a ODI development: Contexts, Physical Architectures and Logical Architectures.
The Physical Architecture describes the technology; where to find the data and how to to it. Open up the Physical Architecture accordion, right click on the appropriate technology and choose NEW DATA SERVER - we can now create a named connection to a physical data source, be it a file location, web url, JMS queue or database; it all depends on the technology we have chosen. We name our data server and provide connection details: JDBC connection details for databases, other technologies may need physical paths, JNDI descriptors or URLs. If we are connecting to a database we also provide the user name and password for the connection. When the Data Server is created we then create physical schema beneath it (again a right click in the GUI) for databases this will be the actual schema to connect to and a work schema (if different) for any intermediate objects generated by ODI. If the physical schema owner is not the same as that for the Data Server connection we give the connect user appropriate grants in the database to access the schema. If you are going to move data between schemas within the same physical database then you should create multiple physical schema under the same data server, otherwise you will not be able to take advantage of set based IKMs to load the data.
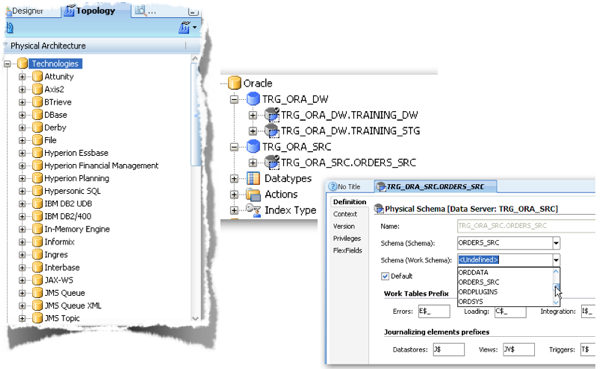
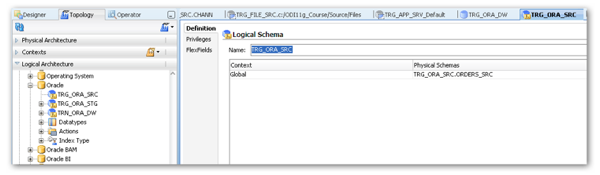
Under the Logical Architecture accordion we in effect provide an alias to the physical data schema - this allows us to build our ETL in the designer part of ODI and be able to point at different physical schemas without having to change our ETL design. This ability to change sources and targets is implemented through Contexts (the third accordion in this piece). Think of contexts as "patch panels" that link a single logical schema to a physical one. We can specify the context of an interface at execution and this context defines the actual connection that is used for the logical tables. This allows us to use different sources and targets for development and for test and simply change a context name to access the correct data without the need to refactor code.
Next time I will start to look at the Designer Navigator.