Oracle Endeca (OEID) - Exploring Unstructured Data - Twitter & Blog Analytics - Part 1
Recently the entire BI landscape of how we do reporting and how the data is consumed seems to be on the change constantly. Until a year back, the whole world of BI (at least from a perspective of Oracle) revolved around building Data Warehouses (& OLAP/Essbase cubes) and then the old school (if i may call that) way of modeling those in the RPD. Majority of BI is still done this way. But i have always wondered whether the traditional BI tools are capable of handling the massive amounts of data generated around the internet/social media these days. Not only will it take insane amount of time in modeling all the data, it will still be "model" dependent.
In addition, BI tools have always needed the underlying sources to be structured. Last year, as part of an engagement i took a look at both SAP Business Objects and IBM Cognos. In particular i was impressed by one specific tool called BOBJ Explorer. This tool unlike traditional BI where we pick & choose columns, was based on attribute key-value pair reporting i.e. you could do a search across all the data across all columns and then it will bring out key metrics related to the search. BI EE just did not have a tool that matched what BOBJ Explorer did. And i wondered how Oracle was going to plug that gap in the product set since unstructured data search and reporting is a key requirement these days. And then the Endeca acquisition happened and the rest as they say is history. Mark did a series of postings on how Endeca works here. Endeca acquisition opens up a lot of possibilities which were considered out of reach from a perspective of BI EE. Lets take for example Twitter feeds or blog posts. These data are all unstructured but there is so much information that we can glean out of them. For example, by just monitoring Twitter feeds one can find out the common issues of a recently launched product (say apple iPhone 4 reception issue). Or when you go to movies, you basically look at the related twitter feeds to find out whether it is a good movie in the first place to go and watch. Basically Sentiment Analysis is a lot more important in the context of social networks. BOBJ Explorer though did the search well, it just could not handle unstructured data well (at least when i took a look sometime back). So Endeca acquisition to me personally was interesting as that opened up an opportunity for Oracle to do unstructured data reporting. Also, to me personally Endeca+Data Mining makes a lot more sense than BIEE + Data Mining. Oracle Data Mining is so good when it comes to text analytics/mining - i am intrigued at the opportunities this has now opened up.
In today's post, we will be looking at how Endeca handles unstructured data. I will showcase 2 examples over 2 blog posts - Loading & reporting out of the data from Twitter and loading & reporting out of the data from Rittman Mead Blog posts (basically the last 10 blog posts). Before we start there are 2 things that we need to understand
-
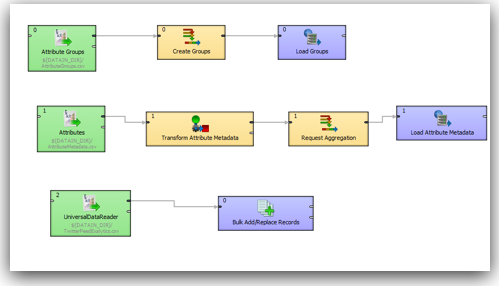
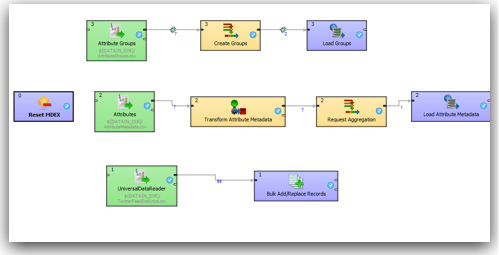
The anatomy of Endeca ETL - Done using Latitude Data Integrator (basically an extension of Clover ETL)
-
The anatomy of reporting using Latitude Studio
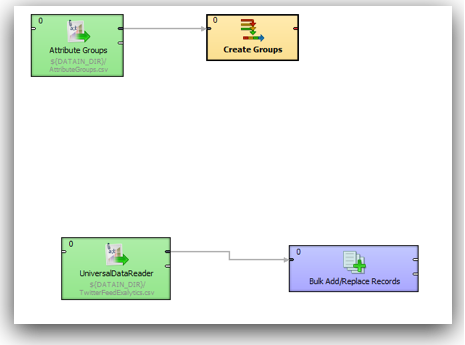
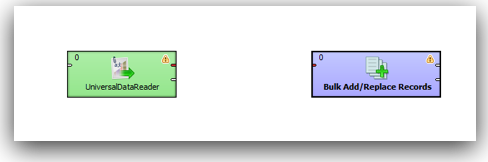
Endeca comes with its own in-memory data engine called MDEX. This engine stores the data in the form of attributes and name-value pairs. It is not a traditional relational store and hence the process of doing a data load into the engine requires an understanding of the MDEX engine. Also, MDEX does not have a standard C or Java API. Instead all data loads and extracts happen through Web Service calls. MDEX is exposed through a set of standard web services that have to be explicitly called as part of the loads. Since it is based on web services, theoretically any ETL tool like ODI, OWB can all connect & load into it. But in practice, without proper adapters it becomes very difficult to formulate the requests for the web service calls - hence we have to use LDI (Latitude Data Integrator) or a pre-built adapter for other tools like Informatica. I would imagine it should not take long for Oracle to come out with an adapter to MDEX soon for ODI (i will try covering a post later on how ODI in its current form can be used to load data into Endeca).
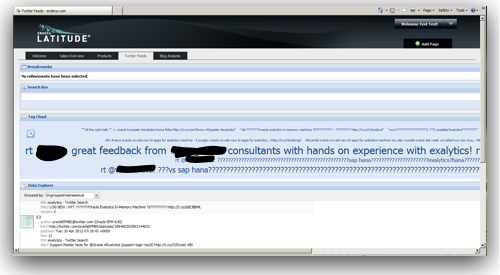
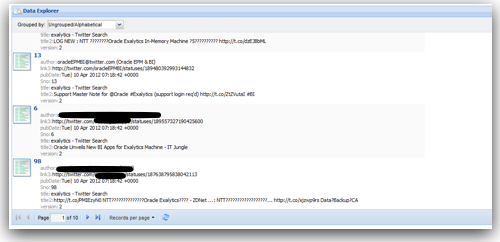
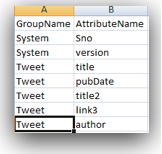
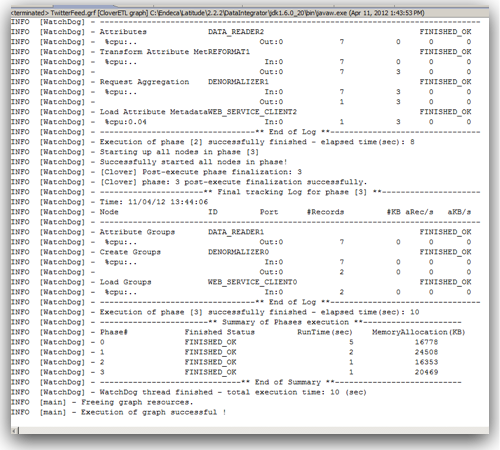
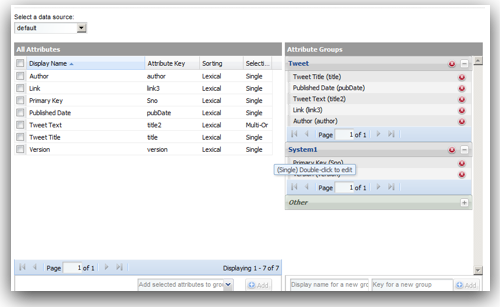
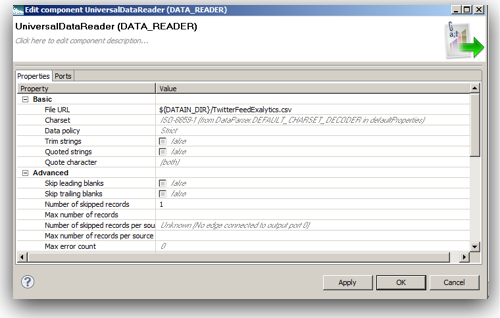
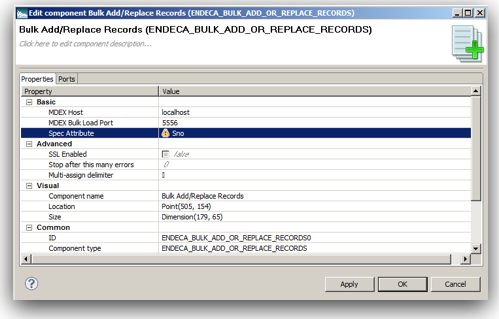
Since MDEX is loaded/extracted using Web Service calls, bulk loads have to be done in batches. In addition, the core feature of MDEX engine is, it is very immune to structural changes of the underlying data sources. For example, in a traditional ETL tool, we will start off with reverse engineering the metadata of the sources & targets. Then we map how the source data flow into the target through a series of transformations. If we have to add a new attribute to a dimension, we will have to reverse engineer the new columns, change the mappings and then do a reload. In the case of MDEX, it is a bit different. We have to define the structure of the sources like in any other ETL tool but target does not need to have a structure at all. Automatically every source column that gets loaded into the MDEX engine is treated as an attribute. To illustrate what we will do is, we will take the example of the twitter feed extracts (latest 100 only) for the search term exalytics as shown below.
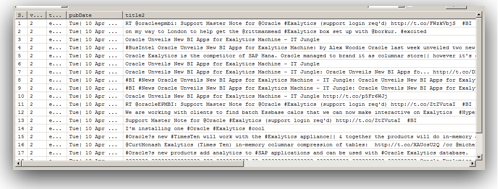
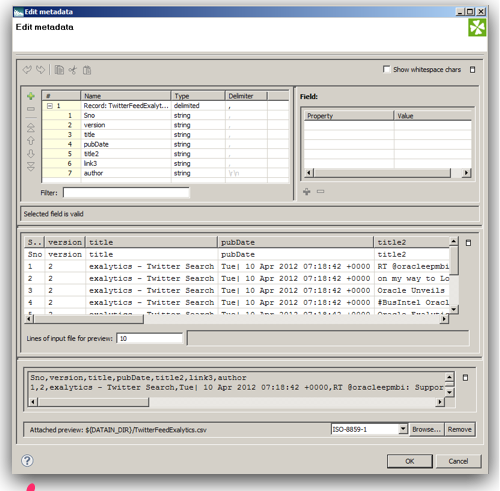
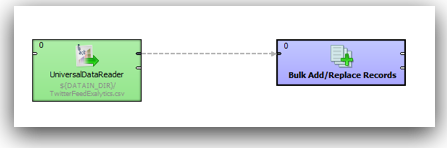
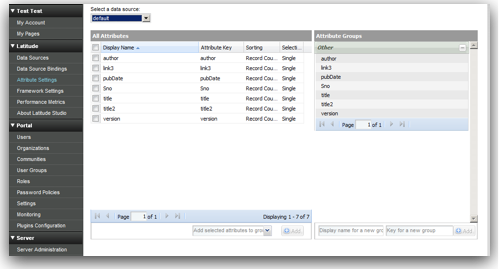
-
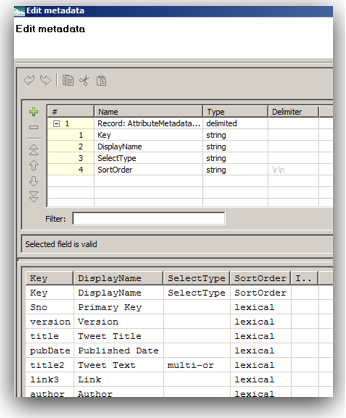
All attributes are grouped under Other group.
-
All attributes have a sorting value of Record Count.
-
All attributes have Single search capability
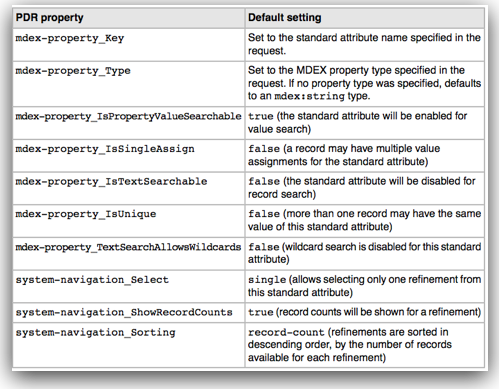
In addition all attributes we loaded have a default data type of string. So, in general when are doing a load into MDEX engine the attributes get created automatically. Also, all properties take default values. These default values are system default settings for MDEX. These default settings can be changed before the data load. That is all handled through custom MDEX properties which have to be pre-loaded as an input to the MDEX web services. These MDEX properties are generally defined as part of PDR definitions. Sample PDR definition along with the default settings are given below