Clustering ODI11g for High-Availability Part 1 : Introduction and Architecture
ODI developers have always been able to build and deploy data integration packages code and run them on traditional standalone agents, but with the 11g release of ODI a new type of agent called a “JEE Agent” became available and gave us another option. JEE agents, rather than running in standalone unmanaged JVMs are instead deployed in WebLogic managed servers typically clustered and as part of a WebLogic domain, and can make use of the connection pooling, scalability and control operations that all come as part of an Java Enterprise Edition application server environment. JEE agents can be deployed alongside, or instead of, standalone agents, but there is one key advantage in using JEE agents and WebLogic - when you deploy JEE agents as part of a WebLogic cluster they can be configured together to form a high availability cluster that can provide the following benefits:
- Spread the load over more than one agent to increase productivity
- Ensure that at least one agent was available at all times to run ETL jobs
- Scheduled ETL jobs are always executed
- Individual job failures do not stop the whole build process
There are few differences between using standalone agents and JEE agents, as at an individual level both execute integration processes and both hold and process the schedule, with the main difference being in how the agent processes are started and stopped, and the resources needed to setup and run the agents. Standalone agents are typically started from the server command-line environment and therefore are either started through batch files or interactively through a terminal utility, whilst the JEE Agent just needs HTTP(S) network access to the WebLogic Administration Console together with the appropriate administrative credentials for start/stop operations. The JEE Agent needs to have WebLogic domain installed and working, whereas a standalone agent runs as a straightforward java JVM process from the command line. More importantly, standalone agents are available with no additional software installs and licensing (beyond installing the agent), whilst JEE agents require an additional WebLogic Server license (typically Enterprise Edition, as this is required for WebLogic clustering), as well as WebLogic installation, configuration and management skills. Therefore if there is only going to be one agent and high availability is not your primary concern, standalone agents are the easiest option, with the the real strength of JEE agents being when you want to manage multiple agents as part of a high-availability cluster.
It’s not all that well known but it’s certainly possible to set up standalone agents are part of a load-balancing and high-availability cluster, with load-balancing being available as a standard feature in ODI Studio and OPMN (Oracle Process Manager and Notification Server) separately configurable to restart failed agents automatically, but this at its best works as a retry and failover configuration, and also requires some reconfiguration at failover time to maintain ”business as usual”. JEE Agent High Availability clusters in contrast keep going even if an agent fails, with no additional configuration required after failover and with the loss of an agent transparent to the user or schedule.
So now that we know the benefits of running ODI agents within a WebLogic cluster, in reality it can be tricky to set up this type of environment particularly if you’re not too familiar with WebLogic Server. At a high-level, the diagram below shows what needs to be installed and configured, and how requests to run ETL jobs are received by Oracle HTTP Server and eventually work their way through to the JEE agents and the ODI repositories.
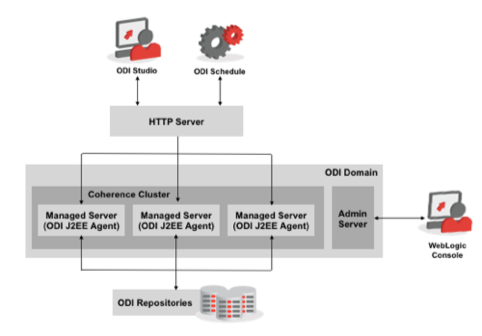
Note the role of Oracle Coherence and Oracle HTTP Server in this architecture:
- Oracle Coherence is used to hold details of the job schedule
- Oracle HTTP Server (part of Oracle Web Tier Utilities) acts as the entry point for requests to run ODI jobs.
Note that Oracle WebLogic Server and Oracle HTTP Server are not part of the standard ODI product license, and will need to be licensed separately if you want to create this type of environment.
The installation process is well documented at http://docs.oracle.com/cd/E14571_01/core.1111/e10106/odi.htm, and in my next blog I'll detail my experience of the installation process. At a high-level though, you start the installation and configuration process by performing the following tasks:
- Install and configure ODI repositories and connectivity on all the physical servers.
- Install Weblogic and the ODI JEE agent on each server in the cluster.
- Create Weblogic Domain and add each managed server to the domain.
- Start the Admin server and all managed servers
At this point we have got a number of individual JEE agents running in WebLogic managed servers, and we could start using them immediately for running ETL jobs, but we would have to manually send individual tasks to each separate JEE agents, as all this setup gives us are a set of individual, unconnected agents.
In fact, a bit more work is needed to configure the agents for high-availability:
- Firstly, we need a mechanism to deal with the ODI schedule, that is, to still make the schedule available even if the agent controlling the schedule fails.
- Second we need to present a single logical agent, that is, a single entity that represents the cluster no matter how many agents are in the cluster and what state those agents are in. This all needs to be in place so that in the unlikely event of an agent or process failure, the cluster and schedule remains available without the need for any manual intervention.
To deal with schedule availability, another product, Oracle Coherence, is used to create an in-memory cache connecting all the JEE agents together, which will hold the current schedule controlled by one of the agents. If that agent fails, another agent takes control of the current schedule and service continues, with all of this happening without any operator intervention.
To present a single logical agent to the outside world hiding the complexity of the underlying JEE agent cluster, Oracle HTTP Server is deployed as a proxy and provides a single logical view of the clustered agents. In addition, it also provides a mechanism for distributing tasks amongst the available JEE agents and as it only send tasks to available agents, the status of the cluster is transparent to the ODI Studio user or schedule regardless of how many agents are currently active.
So the additional steps that make your JEE agents highly-available and presented to users as a single logical agents are as follows:
- Configure Oracle Coherence on each managed server
- Install and setup Oracle HTTP Server
- Reconfigure Agent to point to HTTP server
Realistically, there are a lot of components to install and configure to get an ODI JEE agent High Availability cluster operational, and consider also that the higher the number of JEE agents in the cluster, the higher the cost in time and resources it will take to create that cluster. With the all the different components, its worthwhile considering the function of each of the main bits and how they contribute to high availability :-
- The WebLogic administration server server monitors managed servers, restarting individual servers as necessary through the WebLogic node manager if able to.
- The Oracle Coherence cluster holds and migrates the ODI schedule between agents as necessary.
- The Oracle HTTP Server provides logical view of available agents, so that submitted jobs don't need to know which of the agents are available.
- The Oracle HTTP Server also provides round robin job distribution to all available agents.
Now that I have described the constituent components and what they do within the cluster, its important to acknowledge that in a production environment, the resiliency of two of the non ODI components also needs to be addressed to provide a total high availability solution.
Firstly, the ODI repositories would need to be in a resilient database instance, so that any database unavailability would not affect the agents in the cluster. Some database RAC configuration is available for this during the creation of the domain, and Oracle Active Data Guard can be used to log-ship repository entries to a DR environment to provide failover and redundancy. Secondly, the Oracle HTTP Server needs to be in its own resilient configuration, so that in the event of a HTTP server failure, the proxy agent is still available. This is all so that the HTTP Server and the database do not become single point of failure for the High Availability cluster.
For more information on ODI agent high-availability using WebLogic Server, there’s a couple of useful resources you can take a look at:
- Setup of ODI 11g Agents for High Availability by Sachin Thatte, on the Oracle Data Integration blog
- Installing ODI 11g (including Agents) in High Availability (Active-Active Cluster) : Overview by Atul Kumar
We also cover agents, WebLogic and high-availbility on our ODI 11g course, if you’re interested – just drop us an email for details. For now though, I’ve covered the basics involved in an ODI HA cluster, and in my next posting, I’ll go through some points of interest around the installation and configuration process.