Oracle Database 12cR1 - New Features for BI & DW
Oracle Database 12c Release 1 came out last week, initially available for 64-bit Linux and Solaris (SPARC and x86_64), with the Windows and other versions presumably due over the next few months. So what's in this new release for Oracle BI & DW customers, and how does compatibility stand with OWB, ODI and Oracle BI Enterprise Edition? It's early days yet, but let's take an initial look.
Probably the headline new feature for Database 12cR1 is "pluggable databases" - a system where a single "container" database can be created that can then contain one or more "pluggable" databases, similar to how a single physical server can host one or more virtualised, VMWare or Virtualbox servers. The advantage of container and pluggable databases is that whilst each pluggable databases appears to applications to be its own, self-contained database in-fact it shares the underlying database system infrastructure with the other pluggable databases in that container, reducing the total overhead compared to setting up several full Oracle databases.

Clearly this is something Oracle have put together to support their move into the cloud, but it'll benefit ordinary customers by permitting a greater degree of data isolation than you'd get by a multi-schema approach, without all the overhead of creating virtual machines to run your databases in.

Whilst not a feature specifically aimed at BI & DW developers, those of us who are constantly spinning-up R&D and sandbox-type environments now have another option alongside multiple schemas, multiple databases and VMs/containers, though as we'll see in a moment not all database features are available when running in container/pluggable mode. Note thought that use of more than one pluggable database within a container database requires a new Enterprise Edition option called the Multitenant Option, so its most probably aimed at customers serious about cloud, multi-tenancy and TCO reduction.
Another new feature that'll affect all developers is the replacement of Database Control (the cut-down Enterprise Manager equivalent to Fusion Middleware Control) with DB Express, an Adobe Flash-based management console that comes with one or two new features and a couple of features taken away. As you can see from the screenshots below, the look is similar to Enterprise Manager Cloud Control, and for the average database developer or admin, it still looks like a pretty-good web-based admin tool.

One thing to note is that starting up DB Express is different to the old DB Console; before you can even use it, you need to set the HTTP port it listens on (for example, 8080) using the command below whilst logged in as SYS:
exec dbms_xdb_config.sethttpport(8080);
DB Express actually runs using XDB rather than a standalone EM instance, and this article on the AMIS blog by Marco Gralike runs through a bit more of the new product background along with a few other settings you might want to check-out and enable. You'll also need to have Flash installed and enabled on any browser that uses it, which I guess rules out using Safari on my iPad for checking out 12c databases (at least, without using full Enterprise Manager Cloud Control 12c).
So, onto the BI & DW-specific features now. There's not, at least with this initial 12cR1 release, much new in the OLAP Option area and of course there's no new 12c release of Oracle Warehouse Builder, with instead an updated version of OWB 11gR2 now available that's compatible with Database 12cR1. ODI11g is compatible with Oracle Database 12c in that it can connect to it via the usual JDBC drivers (as can OBIEE through the usual OCI ones), and David Allen from the ODI team posted this article the other day on installing the ODI repositories into a 12c pluggable (as opposed to regular, non-pluggable) database. Steve Karam has been updating and maintaining an excellent list of community Oracle Database 12c-related articles over at his blog, but let's take a quick look at a couple of new 12c features that have interested us over at Rittman Mead.
The first one that grabbed Stewart's eye was temporal validity. Whilst this sounds like something out of Doctor Who, it's actually a feature that leverages flashback (or flash-forward, as Tom Kyte suggests) to return version of a table row entry based on validity at a certain time. To take an example from this Oracle Learning Library article on the topic, a query that uses temporal validity might look like:
select first_name, to_char(valid_time_start,'dd-mon-yyyy') "Start", to_char(valid_time_end,'dd-mon-yyyy') "End"
from hr.emp_temp versions
period for valid_time between to_date('01-SEP-1995') and to_date('01-SEP-1996')
order by 2;
which of course looks very-much like the types of queries we use in BI applications that need to make use of type-2 slowly changing dimensions. In effect, the valid-from and valid-to columns we usually create and maintain become hidden columns used by the Oracle database, and which we can make use of through queries like the one above, or the one below that sets a particular valid time period and then just queries the table, without any reference to this time columns:
exec dbms_flashback_archive.enable_at_valid_time('CURRENT');
select first_name, to_char(valid_time_start,'dd-mon-yyyy') "Start", to_char(valid_time_end,'dd-mon-yyyy') "End"
from hr.emp_temp order by 2;
Taking this to its logical conclusion, what this potentially gives us is a way of implementing SCD2-type dimension tables without having to use surrogate keys, as the temporal validity part will take care of row versioning, though there's probably other benefits of surrogate keys that we'd then lose that I've not thought through, Where this does also get more interesting is when you consider another new 12cR1 feature, in-database row archiving, which allow you to "soft-delete" individual rows so they are excluded from normal DML statements, but they're still there for regulatory, compliance or archiving reasons. For example, using the command:
update emp_arch set ora_archive_state=dbms_ilm.archivestatename(1)
where employee_id in (102, 103);
you can set a particular set of rows to be archived (i.e., not normally visible), run queries against that table and have those rows excluded, but then issue commands such as:
alter session set row archival visibility = all;
or
select employee_id, first_name, ora_archive_state
from emp_arch where ora_archive_state = dbms_ilm.archivestatename(1);
to see the archived, soft-deleted rows. This is quite an interesting new option we could consider when having to store in a data warehouse those table rows that have been deleted in the source system but we need to keep in the warehouse for regulatory or compliance purposes, and together with temporal validity gives us a few new ideas for putting together data warehouse physical models. To be honest - I'm expecting there to be a few gotchas - one we've spotted already is that temporal validity isn't available when working with pluggable databases - but they're a couple of interesting new features, nonetheless.
Other new features of interest in 12cR1 include adaptive SQL query plans that can change as the query executes, something that sounds very useful when the initial cardinality estimates turn out to be way-off, the death of advanced replication and streams (in favour of GoldenGate), the ability to disable archive logging when using data pump, enhanced WITH clauses and subquery factoring including the ability to include inline PL/SQL calls in the subqueries, invisible columns to go with 11g's invisible indexes (with presumably invisible databases and servers to come later on), automatically incrementing identity columns (yay!), and bunch of other optimiser enhancements.
The final new feature that's got us pretty excited at Rittman Mead Towers is probably the most significant new BI&DW-related SQL feature in 12c - SQL pattern matching. We'll no-doubt go into SQL pattern matching in a lot more detail in a future blog post, but to take an example in the Using SQL for Pattern Matching Oracle-by-Example tutorial, the pattern-matching query below:
SELECT * FROM Ticker
MATCH_RECOGNIZE
PARTITION BY symbol
ORDER BY tstamp
MEASURES STRT.tstamp AS start_tstamp, LAST(DOWN.tstamp) AS bottom_tstamp, LAST(UP.tstamp) AS end_tstamp
ONE ROW PER MATCH
AFTER MATCH SKIP TO LAST UP PATTERN (STRT DOWN+ UP+)
DEFINE DOWN AS DOWN.price < PREV(DOWN.price), UP AS UP.price > PREV(UP.price) ) MR
ORDER BY MR.symbol, MR.start_tstamp;
would look for patterns of rows that featured a "v-shaped" up-and-then-down movement, such as that shown in the graph below, that might be useful in identifying stock disposals around a key date.
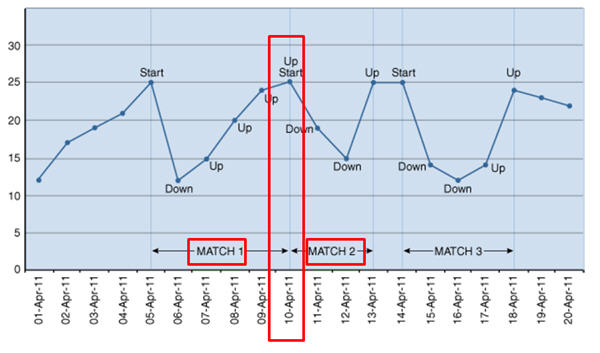
Taking this further, you might use pattern-matching to find CEOs/Executives whose pattern of selling publicly traded stocks two months before financial close is inversely similar to Financial Performance(or Profitability) of all companies over the last two years, or follow the beer and diapers example to find group of products where there is sudden 100% spike in sale (inverted V graph) when compared with the previous day or next day (or previous/next n days/months, for example). Look out for blog posts from our own Stewart on features such as temporal validity and in-database row archiving, and Venkat who came up with the pattern matching examples, over the new few weeks - for now though, back to investigating this exciting new database release.