Oracle Endeca Information Discovery, Text Enrichment and Customer-Defined Lists
One of the data visualisations that you can use with Oracle Endeca Information Discovery is the “tag cloud”. You’ve probably seen tag clouds used in newspaper articles and other publications to show the most commonly found words or phrases in a document, the screenshot below shows a tag cloud in Endeca built on data sourced from comments in a social media feed.
{kind=link}
The component within Endeca Information Discovery that extracted the bank names from the data feed is called the “text enrichment engine”, which actually uses technology that Oracle license from a company called Lexalytics. When you use the text enrichment engine, one of the things it does is to extract “entities” such as people, companies, products, places, email addresses and dates, along with themes and any quotations mentioned in the text.
However, as you might have noticed from the tag cloud, several of the banks and other institutions that this process extracts have a few different variations in their name – for example, Amex is also shown as AmEx, AMEX and so on – but obviously these all actually refer to the same company, American Express. So how can we display tag clouds in Endeca but deal with this data issue in the background?
Another issue that can occur is that some words may be ignored or mistakenly allocated to the wrong group of entities. For example, I had “OMG” picked up as a company name, which is correct, but by checking the data itself it proved to be a shortening of “Oh My God” in the text!!
One solution to these kinds of problems is to use the Text-Tagger component within Endeca Information Discovery, the data-loading tool that is used to load Endeca Server data domains. Using this Text-Tagger component, you can prepare a list of in this example, companies of interest in advance, and the component will find and tag any record with the pre-defined tag, including ignoring case if required.
In some circumstances you will want to create a new list based on the application that you are working on. An example related to the displayed image is a list of all bank or financial institutes and their acronyms. It could be the case that we want to exclude company names that are not related to banking, rather than as shown in the image above where Amazon appears for example.
To solve any of above cases, the text enrichment engine supports customer-defined lists (CDL). In the example below, I’ll create one of these lists and use it to clean up the organisation naming so that my tag cloud shows the correct names for each organisation.
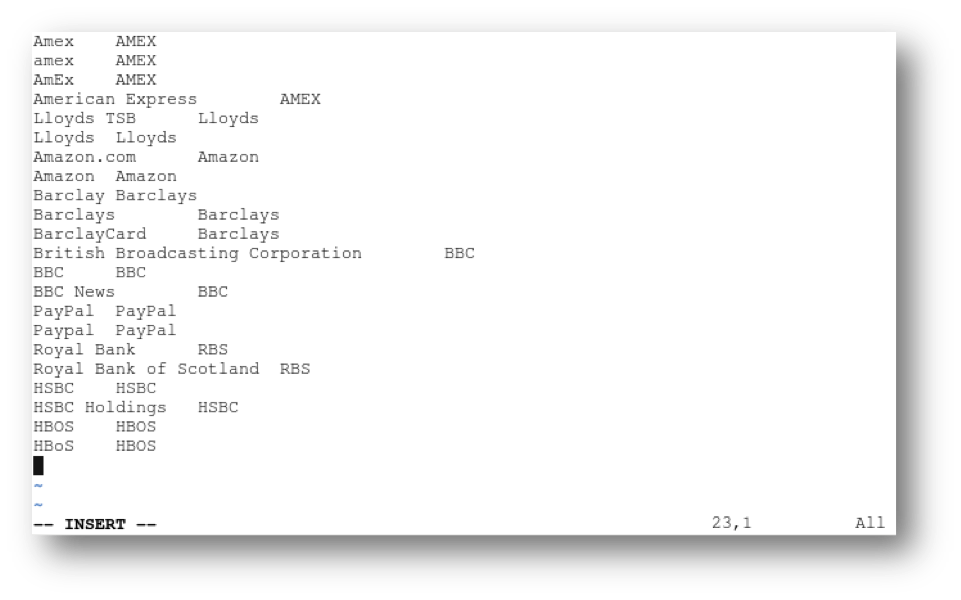
- First Create a Customer-Defined list and save it as custom.cdl postfix in ..\Lexalytics\data\user\salience\entities\lists. As a rule, the file format must be similar to this:
Amex<tab>AMEX
amex<tab>AMEX
AmEx<tab>AMEX
American Express<tab>AMEX
Lloyds TSB<tab> Lloyds
Lloyds<tab>Lloyds
Amazon.com<tab>Amazon
Amazon<tab>Amazon
Barclay<tab>Barclays
Barclays<tab>Barclays
BarclayCard<tab>Barclays
British Broadcasting Corporation<tab>BBC
BBC<tab>BBC
BBC News<tab>BBC
…
{kind=link}
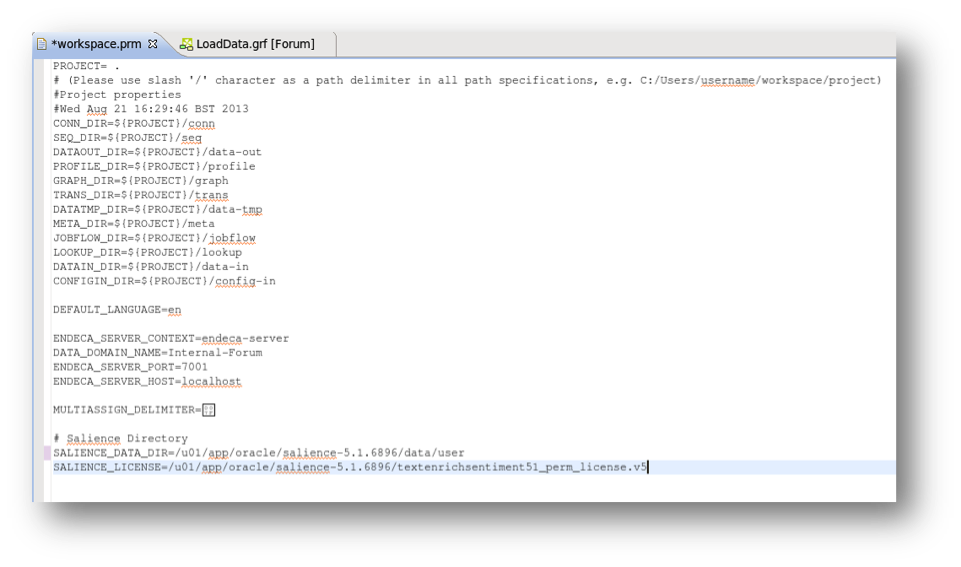
2. Update the Text Enrichment data directory. The default directory is normally Lexalytics\data but after applying the cdl file it should point to Lexalytics\data\user instead.
{kind=link}
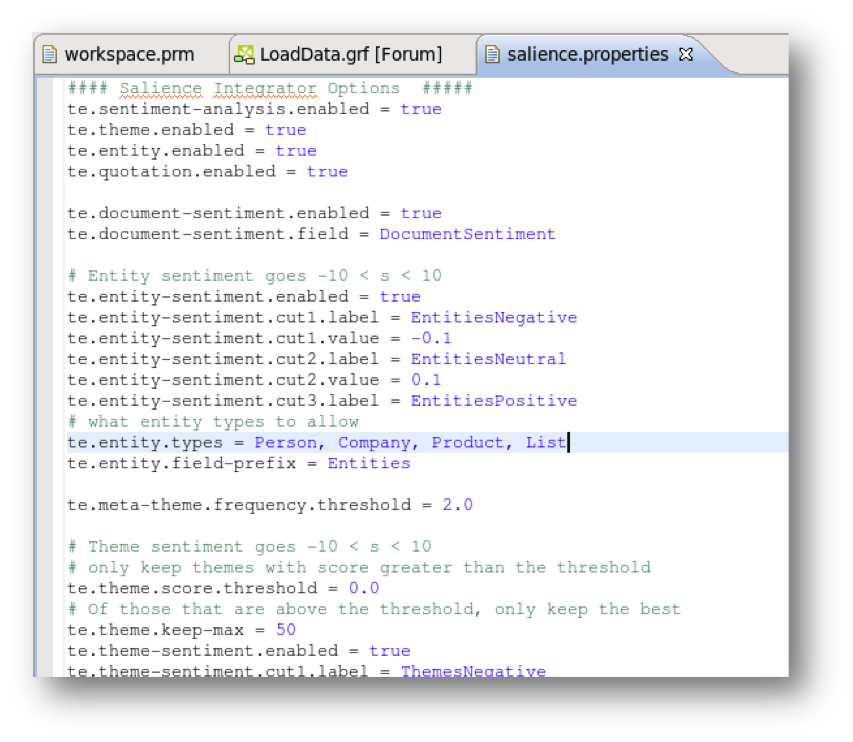
3. Update the Salience.properties file within Oracle Endeca Information Discovery ETL tool, Integrator designer. By default the property “te.entity.types” contains Company, Person, Place, Product, Sports and Title. Add “List” to include user-defined entities.
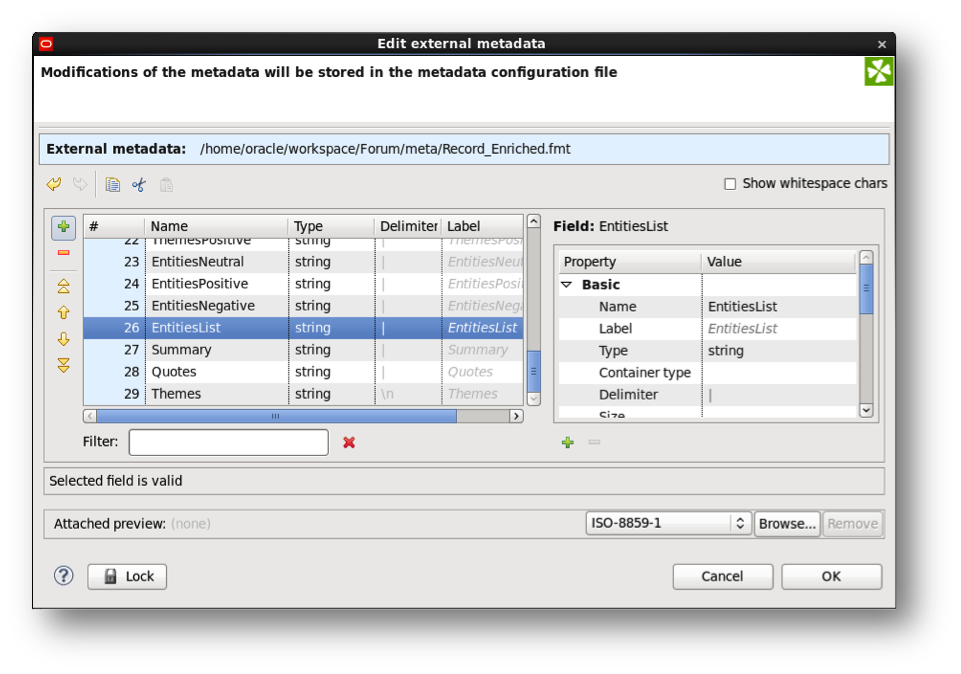
4. Update the ETL Graph in which the text-enrichment has been done and change the text-enrichment out-edge metadata in order to include “EntitiesList” of type string and multi-or assign.
{kind=link}
{kind=link}
- Running the new graph and configurations, here is the new tag cloud using the new entity I created:
{kind=link}