Automated Regression Testing for OBIEE

In the first article of this series I explored what regression testing is, why it matters, and by breaking down the OBIEE stack into its constituent parts where it is possible to do it for OBIEE. In this posting, I explore some approaches that lend themselves well to automation for testing that existing analyses and dashboards are not affected by RPD changes.
Easy Automated RPD regression testing - it’s all about the numbers
“Bring me solutions not problems” goes the mantra, and in the first article all I did was rain on the parade of the de facto regression testing approach, looking at the front end using functional testing tools such as Selenium. So if not at the front end, then where should we focus our automated regression testing of OBIEE? Answer: the data.
The data should arguably be what is most important to our users. If it’s wrong, that’s bad, and if it’s right, hopefully they’re going to be happy. Obviously, there are other factors in making users happy not least performance and the visual appearance of the data. But a system that gives users wrong data, or no data, is fundamentally a failed one.
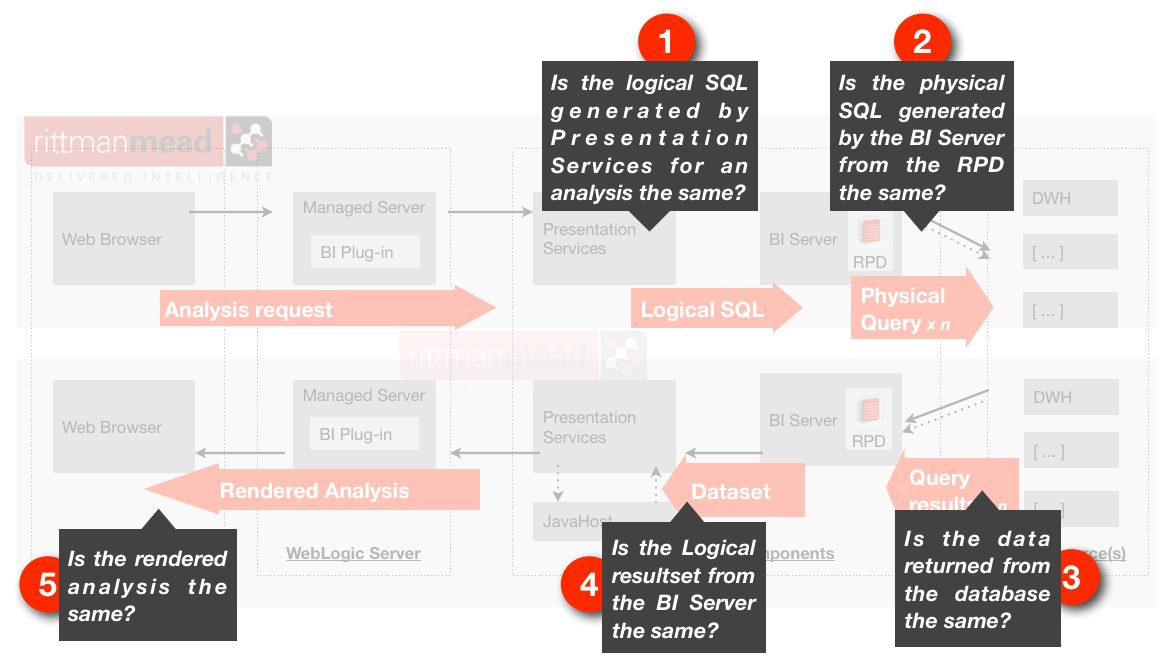
Looking at the following diagram of a request/response through the OBIEE stack we can see that so far as data is concerned, it is the BI Server doing all the work, handling both logical and physical SQL and data sets:
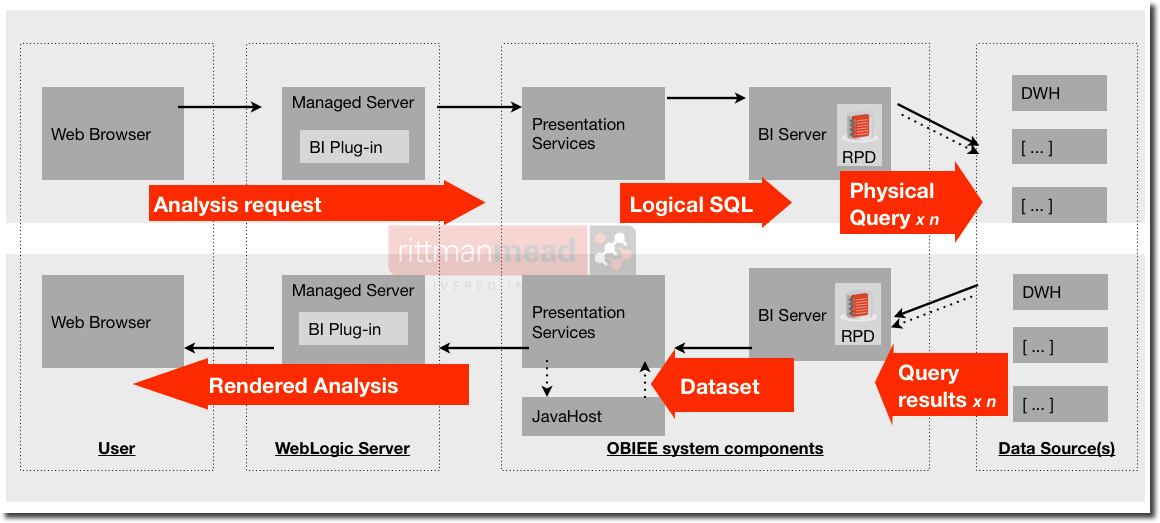
The data that it passes back up to Presentation Services for rendering in the user’s web browser is the raw data that feeds into what the user will see. Obviously the data gets processed further in graphs, pivot tables, narrative views, and so on - but the actual filtering, aggregation and calculation applied to data is all complete by the time that it leaves the BI Server.
How the BI Server responds to data requests (in the form of Logical SQL queries) is governed by the RPD, the metadata model that abstracts the physical source(s) into a logical Business model. Because of this abstraction it means that all Logical queries (i.e. analysis/dashboard data requests) are compiled into Physical SQL for sending to the data source(s) at runtime only. Whenever the RPD changes, the way in which any logical query is handled may change.
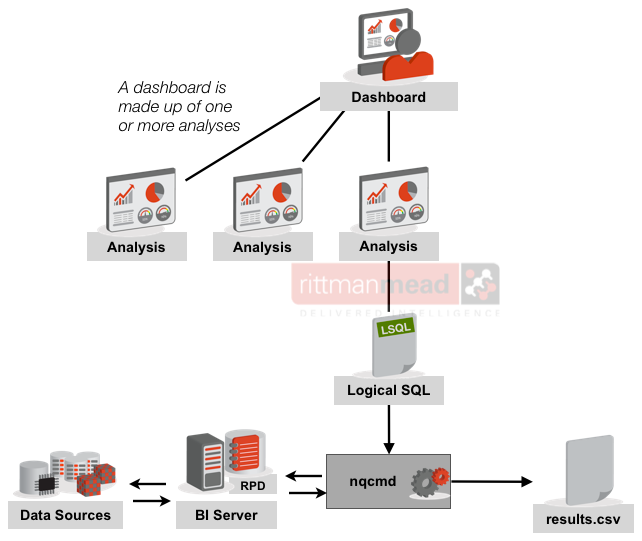
So if we focus on regression testing the impact that changes to the RPD have on the data alone then the available methods become clearer and easier. We can take the Logical SQL alone that Presentation Services generates for an analysis and sends to the BI Server, and we can run it directly against the BI Server ourselves to get the resulting [logical] dataset. This can be done using any ODBC or JDBC client, such as nqcmd (which is supplied with OBIEE at installation).
Faith in reason
If:
- the Logical SQL remains the same (i.e. the analysis has not changed nor Presentation Services binaries changed - but see caveat below)
- the data returned by the BI Server as a result of the Logical SQL before and after the RPD change is made is the same
Then we can reason (through the above illustration of the OBIEE stack) that
- the resulting report shown to the user will remain the same.
Using this logic we can strip away the top layer of testing (trying to detect if a web page matches another) and test directly against the data without having to actually run the report itself.
In practice
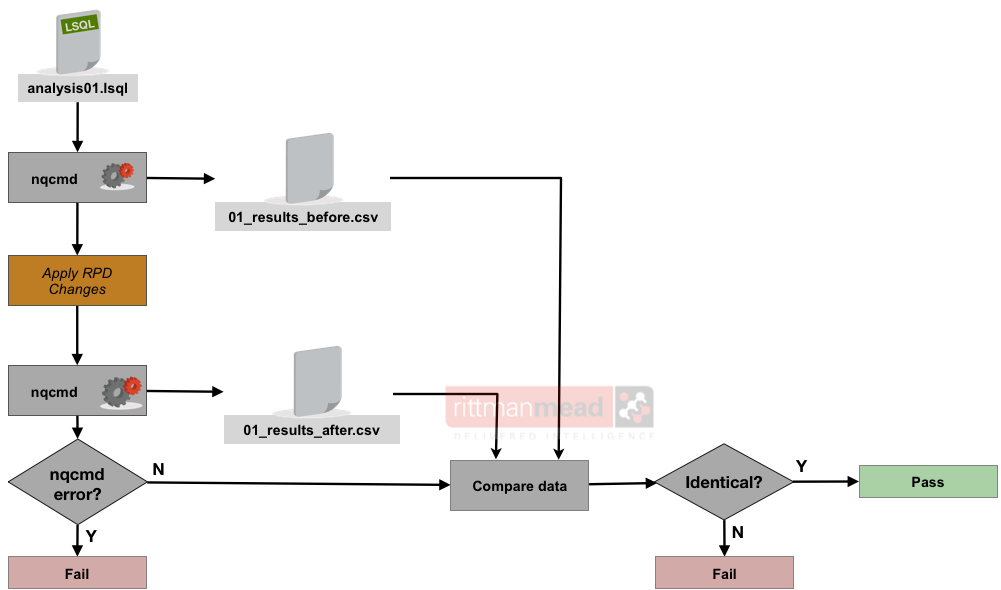
To use this method in practice, the process is as follows:
- Obtain the Logical SQL for each analysis in your chosen dashboards
- Run the Logical SQL through BI Server, save the data
- Make the RPD changes
- Rerun the Logical SQL through BI Server, save the data
- Compare data before & after to detect if any changes occurred
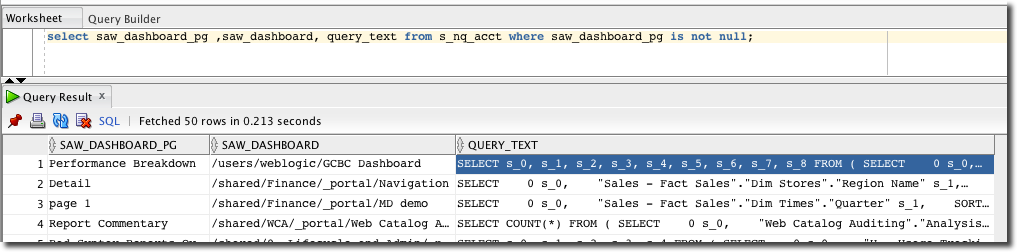
The Logical SQL can be obtained from Usage Tracking, for example:
SELECT QUERY_TEXT FROM S_NQ_ACCT WHERE START_TS > SYSDATE - 7
or you can take it directly from the nqquery.log. For more than a few analyses, Usage Tracking is definitely the more practical option.
 You can also generate Logical SQL directly from an analysis in the catalog using runcat.sh - see later in this post for details.
You can also generate Logical SQL directly from an analysis in the catalog using runcat.sh - see later in this post for details.
If you don’t know which dashboards to take the Logical SQL from, ask yourself which are going to cause the most upset if they stop working, as well as making sure that you have a representative sample across all usage of your RPD’s Subject Areas.
Give the Logical SQL of each analysis an ID and have a log book of which dashboard it is associated with, when it was taken, etc. Then run it through nqcmd (or alternative) to return the first version of the data.
nqcmd -d AnalyticsWeb -u weblogic -p Password01 -s analysis01.lsql -o analysis01.before.csv
where:
-dis the BI Server DSN. For remote testing this is defined as part of the configuration/installation of the client. For testing local to the server it will probably be AnalyticsWeb on Linux and coreapplication_OHxxxxxx on Windows-uand-pare the credentials of the user under whose ID the test should be executed-sspecifies the Logical SQL script to run-othe output file to write the returned data to.
For more information about nqcmd see the manual.
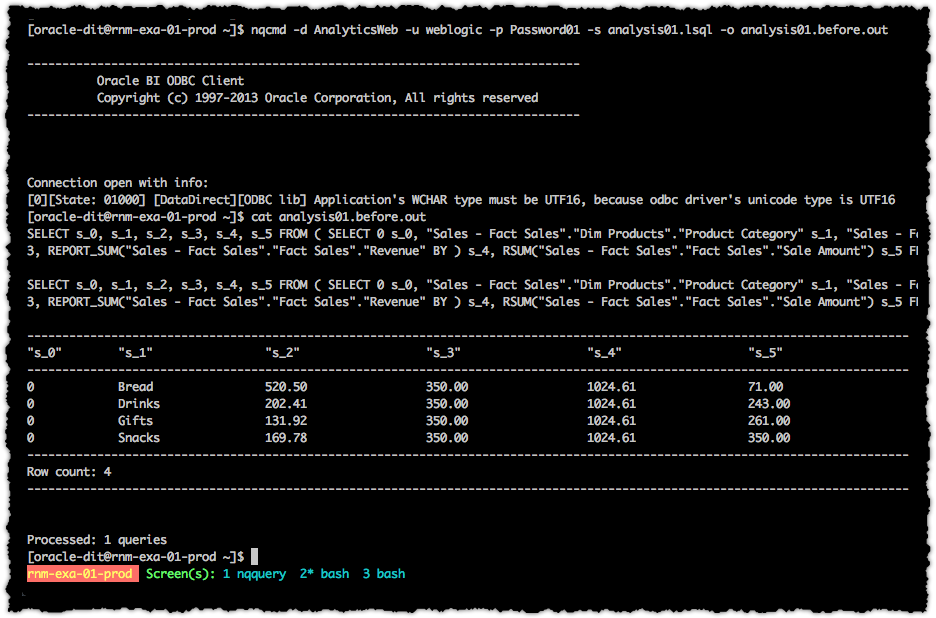
Once you’ve run the initial data sample, make your RPD changes, and then rerun the data collection with the same command as before (except to a different output file). If the nqcmd command fails then it’s an indication that your RPD has failed regression testing already (because it means that the actual analysis will presumably also fail).
An important point here is that if your underlying source data changes or any time-based filter results change then the test results will be invalid. If you are running an analysis looking at “Sales for Yesterday”, and the regression test takes several days then “Yesterday” may change (depending on your init-block approach) and so will the results.
A second important point to note is that you must take into account the BI Server cache. If enabled, either disable it during your testing, or use the DISABLE_CACHE_HIT request variable with your Logical SQL statements.
Having taken the before and after data collections for each analysis, it’s a simple matter of comparing the before/after for each and reporting any differences. Any differences are typically going to mean a regression has occurred, and you can use the before/after data files to identify exactly where. On Linux the diff command works perfectly well for this
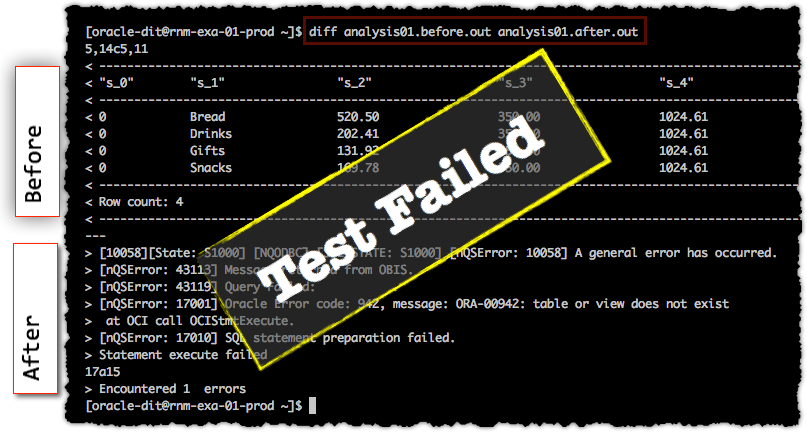
In this case we can see that the ‘after’ test failed with a missing table error. If both files are identical (meaning there is no difference in the data before and after the RPD change), there is no output from diff:

Tools like diff are not pretty but in practice you wouldn’t be running all this manually, it would be scripted, reporting on exceptions only.
So a typical regression test suite for an existing RPD would be a set of these nqcmd calls to an indexed list of Logical SQL statements, collecting the results for comparison with the same executions once the RPD changes have been made.
Tips
- Instead of collecting actual data, you could run the results of nqcmd directly through
md5and store just the hash of each resultset, making for faster comparisons. The drawback of this approach would be that to examine any discrepancies you’d need to rerun both the before & after tests. There is also the theoretical risk of a hash collision (where the same hash is generated for two non-matching datasets) to be aware of. diffsets a shell return code depending on whether there is a difference in the data (RC=1) or not (RC=0), which makes it handy for scripting into if/then/else shell script statementsnqcmdusesstdoutandstderr, so instead of specifying-ofor an output file, you can redirect the output of the Logical SQL for each analysis to a results file (file descriptor 1) and an error file (file descriptor 2), making spotting errors easier:nqcmd -d AnalyticsWeb -u weblogic -p Password01 -s analysis01.lsql 1>analysis01.out 2>analysis01.err
Taking it one step further
We can strip away the layers even further, in two additional stages:
- Instead of examining the data returned by a generated physical SQL query, simply compare the generated SQL query itself, before and after a RPD change. If the query is the same, then therefore the data returned will be the same, and therefore the report will be the same.
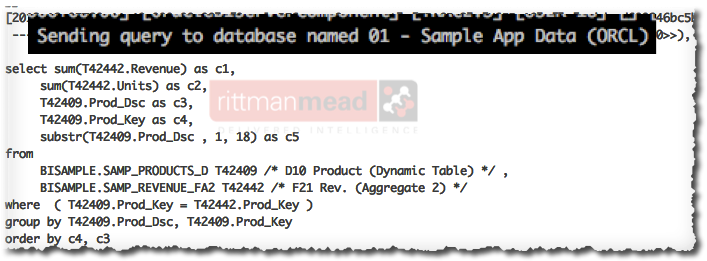 One thing to watch for is that the Physical query logged in Usage Tracking (although not in
One thing to watch for is that the Physical query logged in Usage Tracking (although not in nqquery.log) has a Session ID embedded at the front of it which will make direct comparison more difficult.
- The Physical SQL is dependant on the RPD; if the RPD changes then the Physical SQL may change. However, if neither the RPD nor inbound Logical SQL has changed and only the underlying data source has changed (for example, a schema modification or database migration) then we can ignore the OBIEE stack itself and simply test the results of the Physical SQL statement(s) associated with the analysis/dashboard in question and make sure that the same data is being returned before and after the change
The fly in the ointment - Logical SQL generation
This may all sound a bit too good to be true; and there is indeed a catch of which you should be aware.
Presentation Services does not save the Logical SQL of an analysis, but rather regenerates it at execution time. The implication of this is that the above nqcmd method could be invalid in certain circumstances where the generated Logical SQL changes even when the analysis and patch level remain unchanged. If an analysis' Logical SQL changes then we cannot use the same before/after dataset comparison as described above -- because the 'after' dataset would not actually match what would be returned. In reality, if the Logical SQL changes then the corresponding Logical resultset is also going to be different.
Two factors that will cause Presentation Services to generate different Logical SQL for an analysis without changing the analysis at all are modifications to an RPD Logical Column’s Sort order column or Descriptor ID column configuration.
As an example, consider a standard “Month” column. By default, the column will be sorted alphabetically, so starting with April (not January)
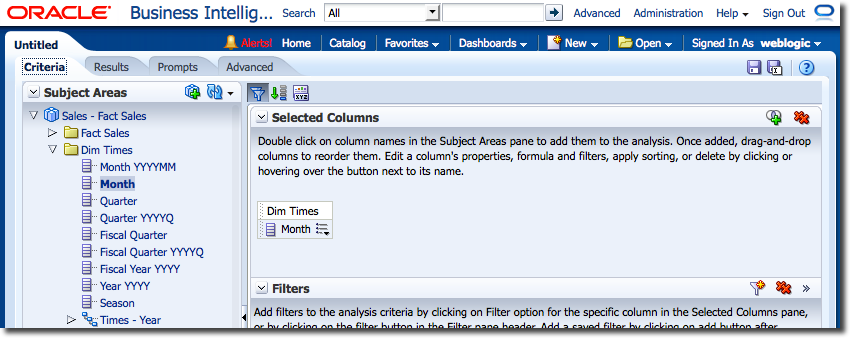
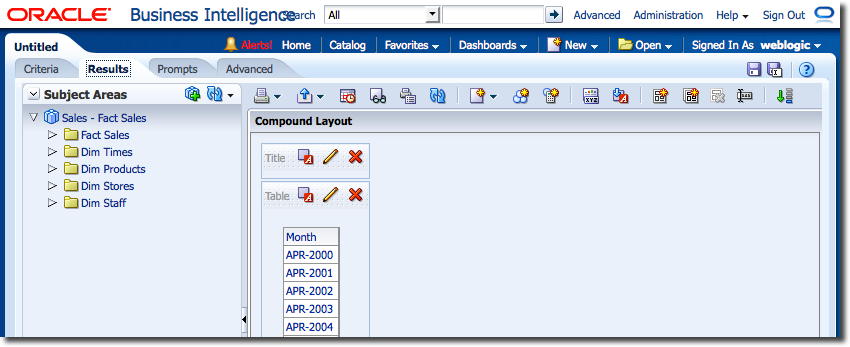
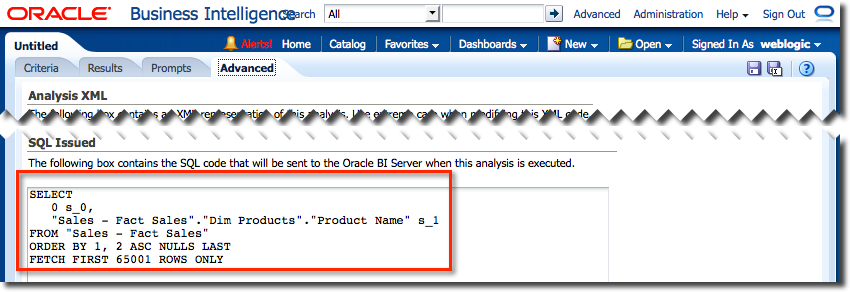
The Logical SQL for this can be seen in the Advanced tab
Now without modifying the analysis at all, we change the RPD to add in a Sort order column:
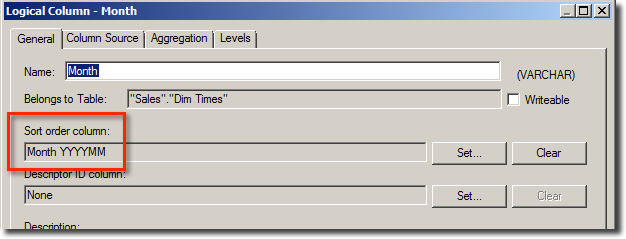
Reload the RPD in Presentation Services (Reload Files and Metadata) and reload the analysis and examine the Logical SQL. Even though we have not changed the analysis at all, the Logical SQL has changed:
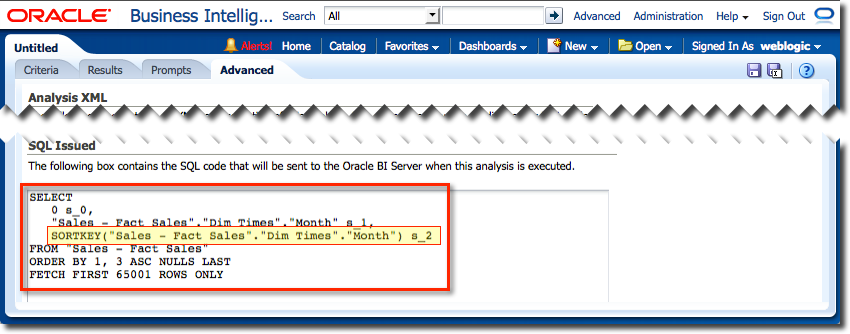
When executed, the analysis results are now sorted according to the Month_YYYYMM column, i.e. chronologically:
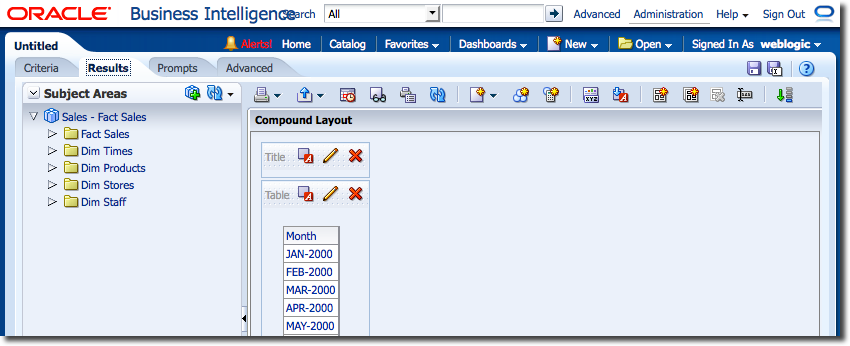
The same happens with the Descriptor ID Column setting for a Logical Column – the generated Logical SQL will change if this is modified. Changes to Logical Dimensions can also affect the Logical SQL that is generated if an analysis is using hierarchical columns. For example, if the report has a hierarchical column expanded down one level, and that level is then deleted from the logical dimension in the RPD, the analysis will instead show the next level down when next run.
Regression Testing Logical SQL generation
It is important that Logical SQL is considered as part of regression testing if we are using this targeted approach - it is the price to pay for selectively testing elements of the stack using reasoning to exclude others. In this case, if the Logical SQL changes then we cannot compare datasets (because the source query will have changed when the actual analysis is run). In addition, if the Logical SQL changes then this is a regression in itself. Consider the above Sort order column example - if that were removed from an RPD where it had been present, users would see the effect and quite rightly raise it as a regression.
There are at least two ways to get the Logical SQL for an analysis programatically : the generateReportSQL web service, and the Presentation Services Catalog Manager tool. We will look at the latter option here. The Catalog Manager can be run interactively through a GUI, or from the command line. As a command line utility it offers a rich set of tools for working with objects in the Presentation Catalog, including generating the Logical SQL for a given analysis. The logical outline for using it would be as shown below. If the Logical SQL is not identical, or runcat.sh fails to generate Logical SQL for the analysis after the RPD is changed, then a regression has occurred. If the Logical SQL has remained the same then the testing can proceed to the nqcmd method to compare resulting datasets.
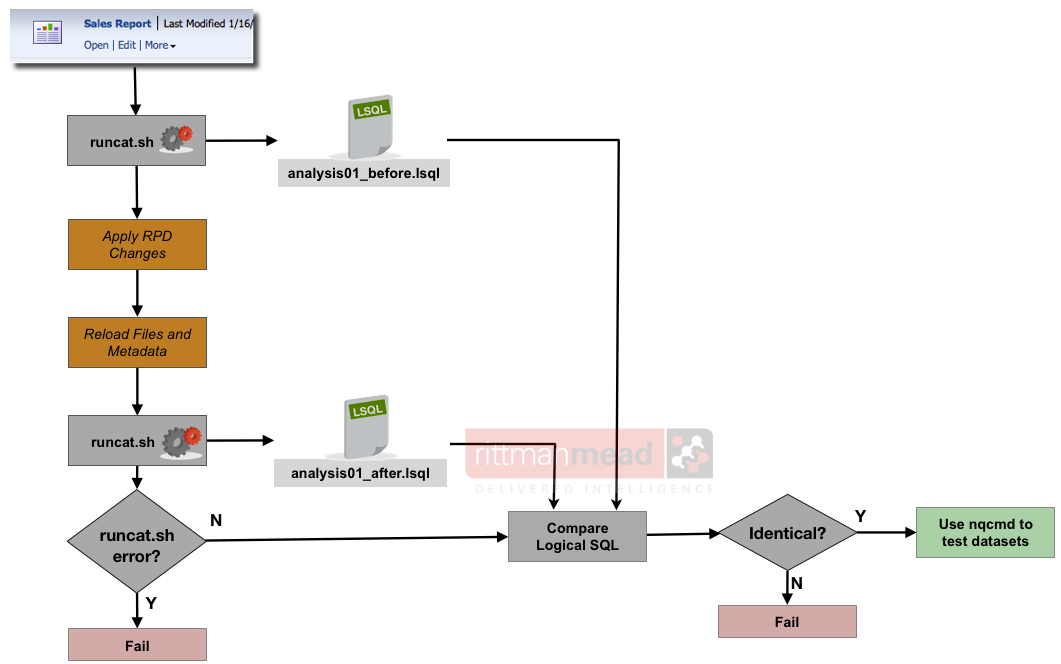
runcat.sh is a powerful utility but a bit of a sensitive soul for syntax. First off, it's easiest to call it from its home folder:
cd $FMW_HOME/instance1/bifoundation/OracleBIPresentationServicesComponent/coreapplication_obips1/catalogmanager
To see all the things that it can do, run
./runcat.sh -help
Or further information for a particular command (in our case, we're using the report command):
./runcat.sh -cmd report -help
So to generate the Logical SQL for a given analysis, call it as follows:
./runcat.sh -cmd report -online http://server:port/analytics/saw.dll -credentials creds.txt -forceOutputFile output.lsql -folder "/path/to/analysis" -type "Analysis" "SQL"
Where you need to replace:
- server:port with your BI Server and Managed Server port number (for example, biserver:9704)
- creds.txt is a file with your credentials in, see below for further details
- output.lsql is the name of the file to which the Logical SQL will be written. Remove the 'force' prefix if you want runcat.sh to abort if the file exists already rather than overwrite it
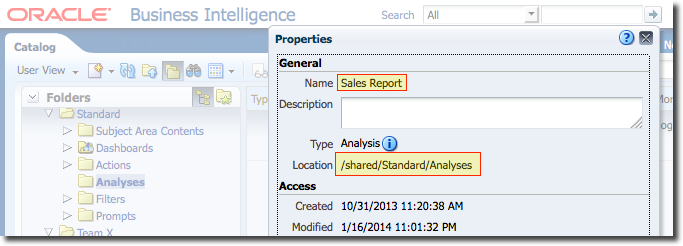
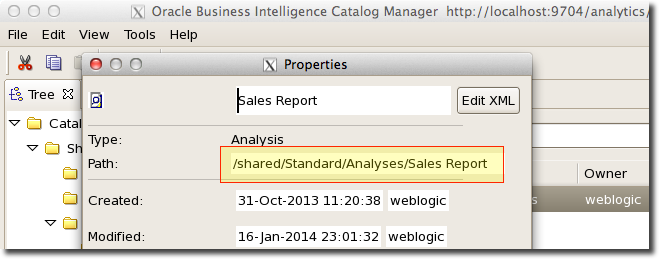
- /path/to/analysis is the full path to the analysis (!), which you can get from both OBIEE (Catalog -> Object -> Properties) and from the Catalog Manager in GUI mode (Object -> Properties). In the screenshots here the full path is /shared/Standard/Analyses/Sales Report
Having called runcat.sh once, you then make the RPD change, reload the RPD in Presentation Services, and then call runcat.sh again and compare the generated Logical SQL (e.g. using diff) - if it's the same then you can be sure that when the analysis runs it is going to do so with the same Logical SQL and thus use the nqcmd method above for comparing before/after datasets.
To call runcat.sh you need the credentials in a flatfile that looks like this:
login=weblogic pwd=Password01
If the plaintext password makes you uneasy then consider the partial workaround that is proposed in a blog post that I wrote last year : Make Use of OBIEE’s Command Line Tools with Reduced Exposure of Plain Text Passwords
Bringing it together
Combining both nqcmd and runcat.sh gives us a logic flow as follows.
- Run Logical SQL through nqcmd to generate initial dataset
- Run analysis to which the Logical SQL corresponds through runcat.sh to generate initial Logical SQL
- Make RPD changes
- Run analysis through runcat.sh again. If it fails, or the Logical SQL doesn't match the previous, then regression occurred.
- Rerun nqcmd, and compare the before/after datasets. If they don't match, or nqcmd, fails, then regression occurred.
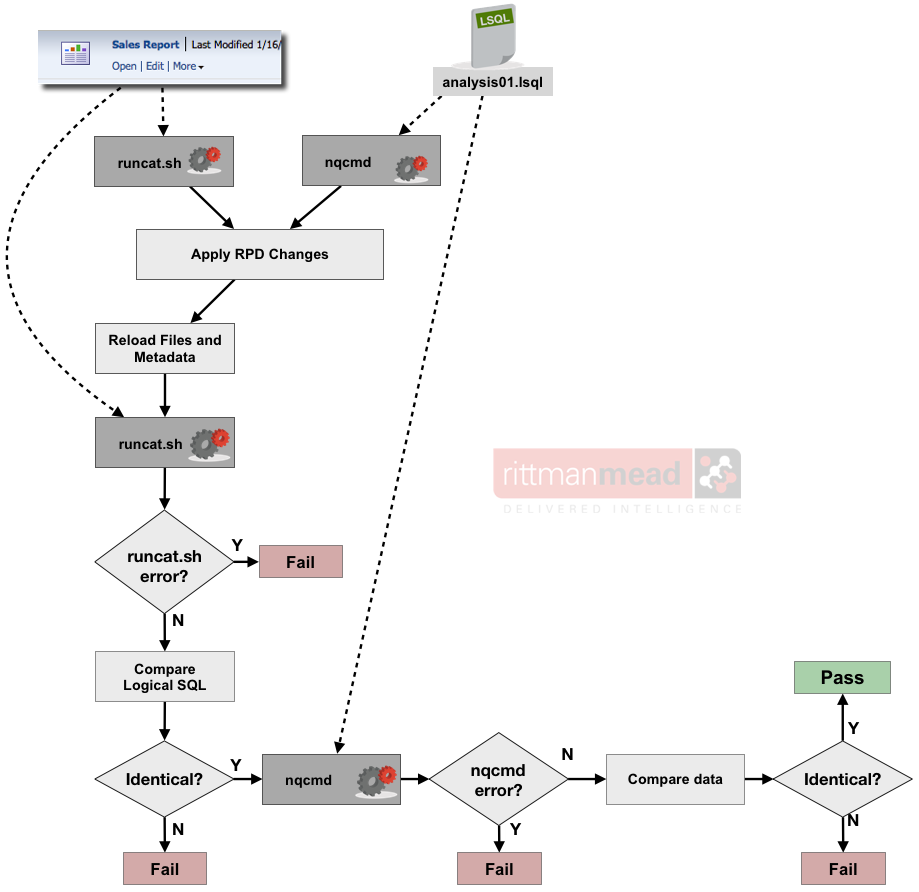
You may wonder why we have two Logical SQL statements present - that for use with nqcmd, and that from runcat.sh. The Logical SQL for use with nqcmd will typically come from actual analysis execution (nqquery.log / Usage Tracking) with filter values present. To compare generated Logical SQL, the source analysis needs to be used.
Summary
So to summarise, automated regression testing of OBIEE can done using just the tools that are shipped with OBIEE (and a wee bit of scripting to automate them). In this article I’ve demonstrated how automated regression testing of OBIEE can be done, and suggested how it should be done if the changes are just in the RPD. Working directly with the BI Server, Logical SQL and resultset is much more practical and easier to automate at scale. Understanding the caveat to this approach - that it relies on the Logical SQL remaining the same - and understanding in what situations this may apply is important. I demonstrated another automated method that could be used to automatically flag any tests for which the dataset comparison results would be invalid.
Testing the data that analyses request and receive from the BI Server can be done using nqcmd by passing in the raw Logical SQL, and this Logical SQL we can also programatically validate using the Catalog Manager tool in command line mode, runcat.sh.
Looking back at the diagram from the first post in this series, you can see the opportunities for regression testing in the OBIEE stack, with the point being that a clear comprehension of this would allow one to accurately target testing, rather than assuming that it must take place at the front end:
If we now add to this diagram the tools that I have discussed in the article, it looks like this:
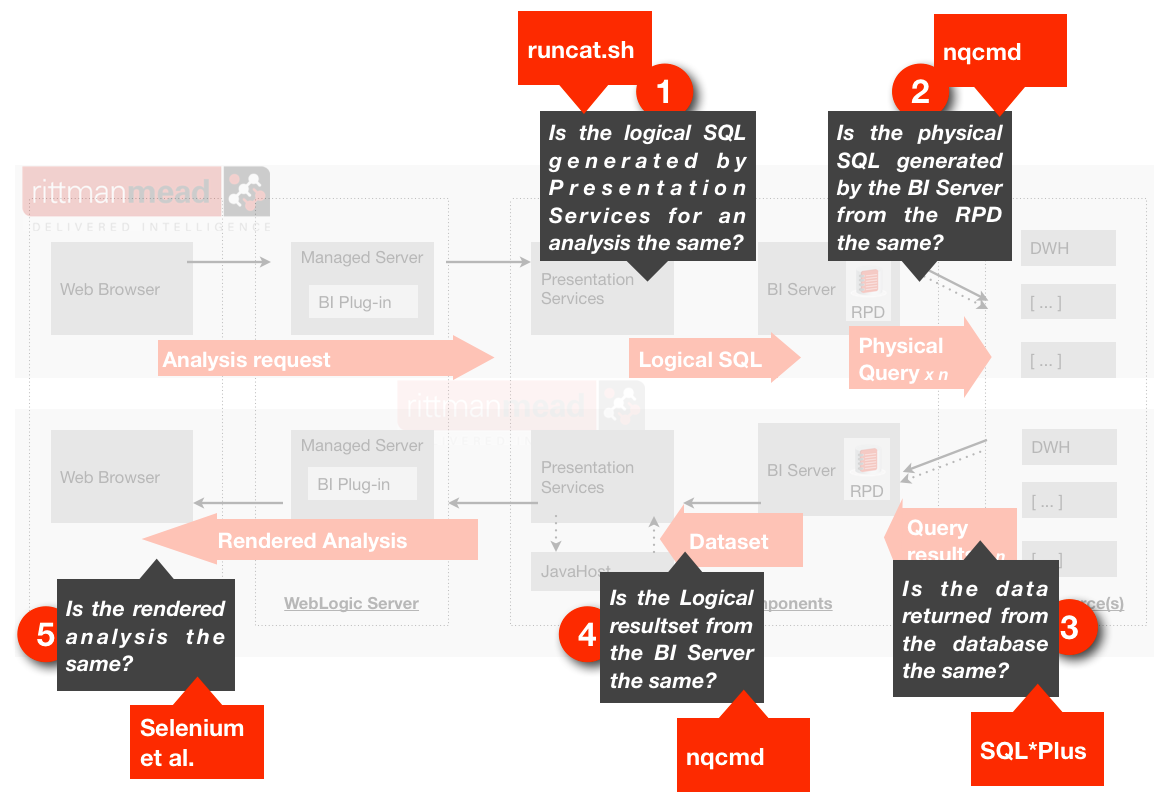
I know I've not covered Selenium, but I've included it in the diagram for completeness. The other tool that I plan to cover in a future posting is the OBIEE Web Services as they also could have a role to play in testing for specific regressions.
Conclusion
Take a step back from the detail, I have shown here a viable and pragmatic approach to regression testing OBIEE in a manner that can actually be implemented and automated at scale. It is important to be aware that this is not 100% test coverage. For example, it omits important considerations such as testing for security regressions (can people now see what they shouldn't). However, I would argue that some regression testing is better than none, and regression testing "with one's eyes open" to its limitations that can be addressed manually is a sensible approach.
Regression testing doesn't have to be automated. A sensible mix of automation and manual checking is a good idea to try and maximise the test coverage, perhaps following an 80/20 rule. The challenges around regression testing the front end mean that it is sensible to explore more focussed testing further down the stack where possible. Just because the front end regression testing can't be automated, it doesn't mean that the front end shouldn't be regression tested - but perhaps it is more viable to spend time visually checking and confirming something than investing orders of magnitude more hours in building an automated solution that will only ever be less accurate and less flexible.
Regression Testing OBIEE is not something that can be solved by throwing software at it. By definition, software must be told what to do and OBIEE is too flexible, too complex, to be able to be constrained in such a manner that a single software solution will be able to accurately detect all regressions.
Successfully planning and executing regression testing for OBIEE is something that needs to be not only part of a project from the outset but is something that the developers must take active responsibility for. They have the user interviews, the functional specs, they know what the system should be doing, and they know what changes they have made to it -- and so they should know what needs testing and in what way. A siloed approach to development where regression testing is "someone else's problem" is never going to be as effectively (in terms of accuracy and time/money) as one in which developers actively participant in the design of regression tests for the specific project and development tasks at hand.
Many thanks to Gianni Ceresa for his thoughts and assistance on this subject.