OBIEE Regression Testing - An Introduction

In this article I’m going to look at ways to test changes that you make to OBIEE to ensure that they don’t break existing functionality. In all but the simplest IT systems it’s common for one (planned) action to inadvertently cause another (unplanned).

What IS Regression Testing?
When we make a change to a system we use functional unit tests to ensure that it does do what it is supposed to do. We should also make sure that the same changes don’t do what they’re not supposed to, that is, cause functionality already existing in the system to change behaviour. If this does happen it is known as a regression and is something we want to ensure doesn’t happen without us knowing. Some examples of regressions seen in standard OBIEE development changes include:- Reports stop returning data, showing an error instead
- Reports start to show the wrong data
- Some combinations of dimensions and facts to no longer show data, or show an error
- Dashboards that reference a particular analysis stop working
- An OBIEE version upgrade causes certain types of graph to render in a different way from the previous version
- An OBIEE patch introduces a bug in the front end user interface
What drives Regression Testing?
The requirement for regression testing OBIEE broadly comes from two different types of change:- New binaries - that is, an upgrade (or patch) of OBIEE
- New “application code” - changes to the RPD, the underlying database schema, and so on.
- Frequency : OBIEE may get patched once or twice a year, and upgraded every few years. Compare this to development changes made to the RPD et al, which users would often like to see happening on a frequent basis (sometimes daily at the beginning of an implementation). If these changes are happening with great regularity then (a) we don’t want to be the ones causing the bottleneck because we can’t regression test them and thus (b) we need to find a repeatable way to perform these tests accurately and quickly.
- Delta Visibility : When Oracle change the OBIEE code base, we are blind as to what has gone on under the covers. Sure, we know what’s changed in the documentation, but as a starting point for “what might have broken” we can only assume everything has and test accordingly. Conversely, in a planned development we know exactly what we changed and we can therefore work out the scope of the necessary testing.
Why Regression Test?
If you don’t regression test then you place a wager that you’ll be able to fix any problems that arise. As soon as they arise. In Production. With angry users on the phone. And the project manager screaming blue murder because their change is getting blamed for breaking everything.This is a recipe for compounding errors upon errors, not a stable system. Testing, in all flavours, is about gaining confidence about the impact of a proposed change to a system. Functional testing reassures us that the change will do what it was designed to do. Performance testing helps us understand how a system behaves from a response time and capacity perspective. Regression testing gives us the confidence that a change, whilst doing what it ought to, isn’t going to affect something else.
The confidence in what is (and isn’t) going to happen when we deploy a change enables us to make these changes more frequently as required by the users. Instead of a long development cycle with a huge number of changes bunched in together, and one big bang test and release, we can take a more rapid, flexible, and responsive approach to development and release because we have the confidence that an individual change is going to work.
In addition to confidence in additional releases to new deployments, a good regression testing framework enables us to have confidence in making changes to long-standing big ball of mud systems. So long as we understand the relevant interfaces points in OBIEE, we can build a pass/fail test framework on top of the most complex RPD/schema.
Targeting Regression Testing Effectively
Regression testing is easy. You pay a troop of monkeys to sit at a set of computers and run every single dashboard, build every permutation of adhoc report, and if you’ve just upgraded or patched OBIEE, go through the user interface with a fine toothed comb. After the appropriate period of several weeks, any differences they find from before your change was made is a regression. Congratulations. All you need to do now is fix the problem – and then of course, regression test your new change. So monkeys are one option, but they’re expensive (you should see the wholesale market peanut price these days), they’re not infallible (monkeys get distracted by YouTube too), and they are slow.Better than monkeys is automated regression testing, targeted smartly at the area of OBIEE that has been changed. We will now take a look at which changes can cause regressions in which area, and from that derive a list of testing methods appropriate for each type of change made.
Regression testing points in the OBIEE stack
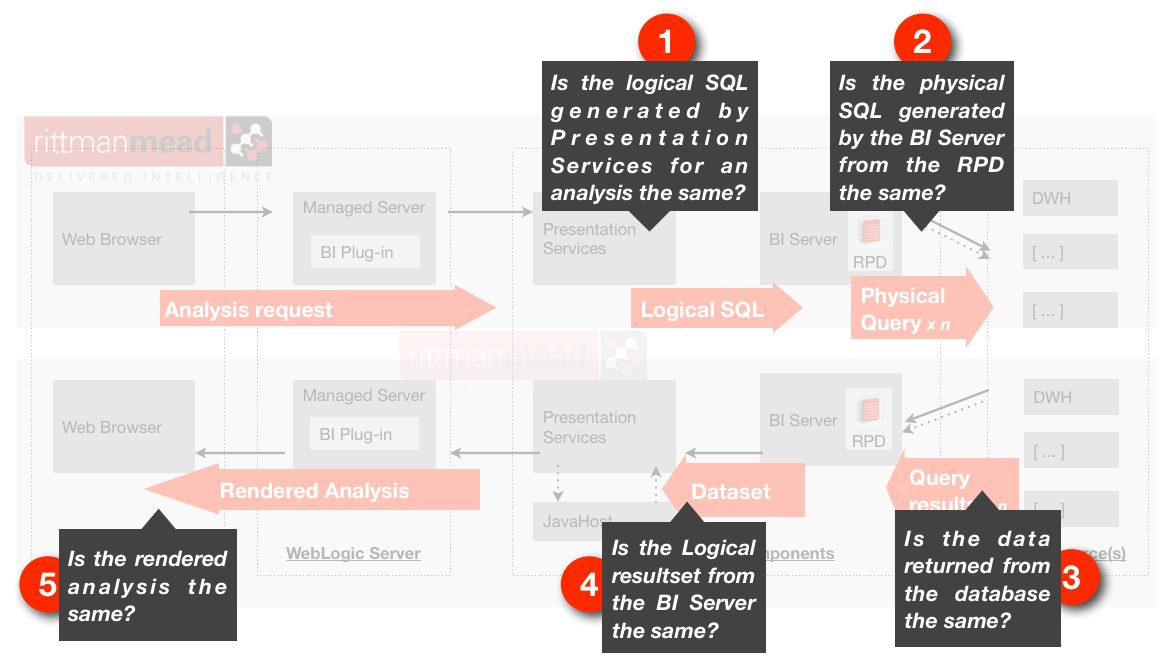
To understand how we can regression test OBIEE, let us look at where a regression can be detected. The following diagram illustrates the request/response flow through the components in the OBIEE stack. We can use it to see where regressions may expose themselves, and thus understand at what points we can consider testing for them.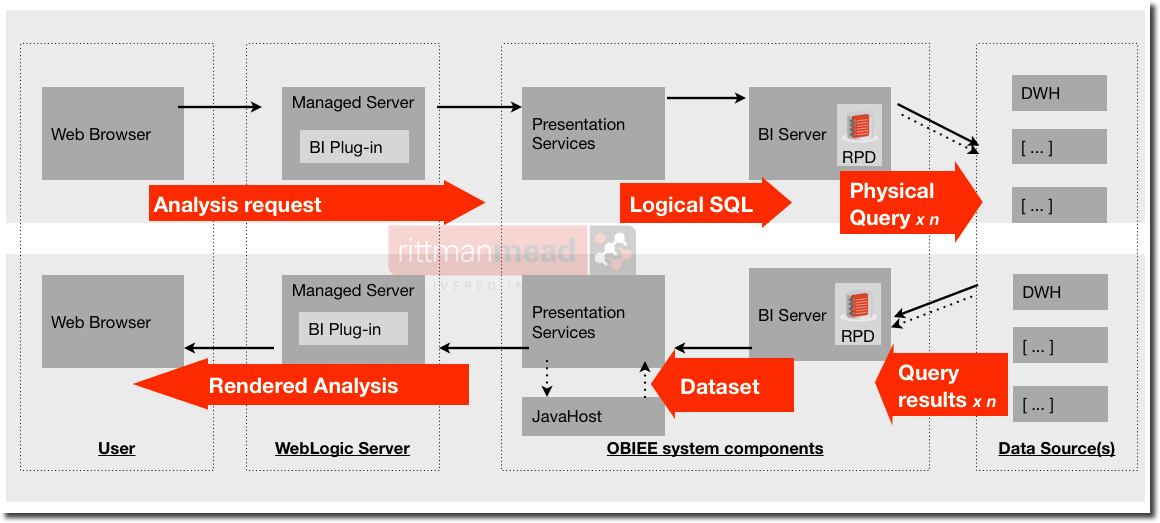
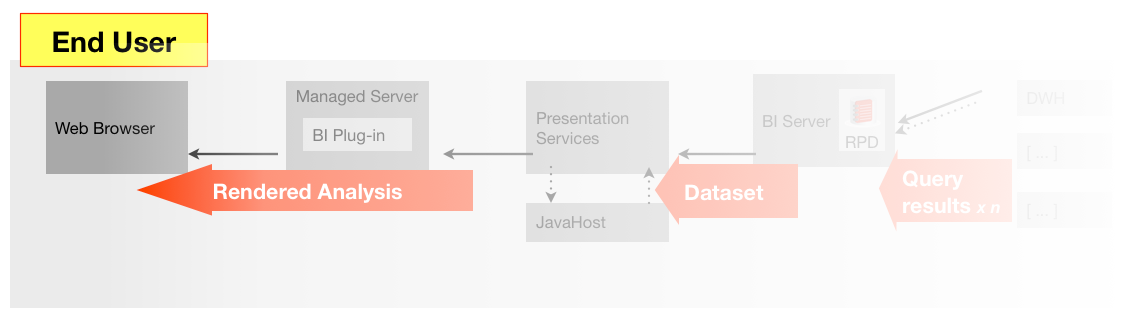
- The user interface may regress. They may be actual bugs that weren’t there before, or ‘regressions’ in the sense that functionality or icons/layout have changed. These changes would typically only come about through software changes (patching/upgrades). Regressions could also occur if you are manipulating the UI through the analysis itself (eg narrative view) and the behaviour changes, but this type of UI modification is less common.
- Regressions caused by changes to the underlying data, RPD or analyses are going to manifest themselves through a dashboard. This could be in the data or the presentation of the data (tables, graphs, etc).
- Considering a dashboard by its constituent parts, an individual analysis could exhibit differences in its data or the presentation of the data

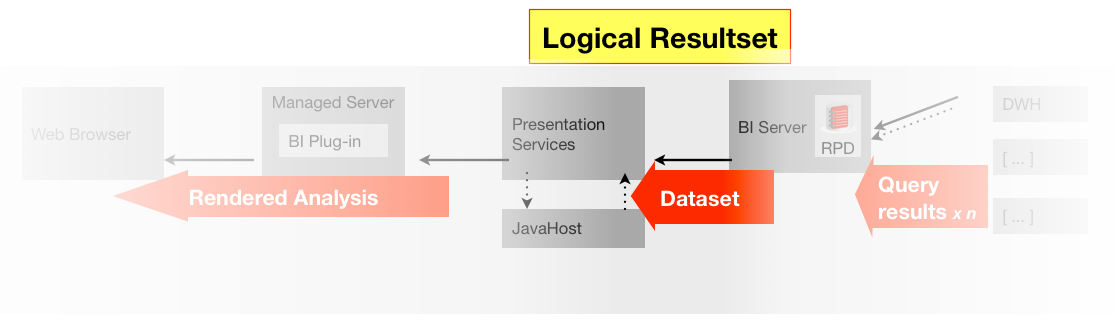
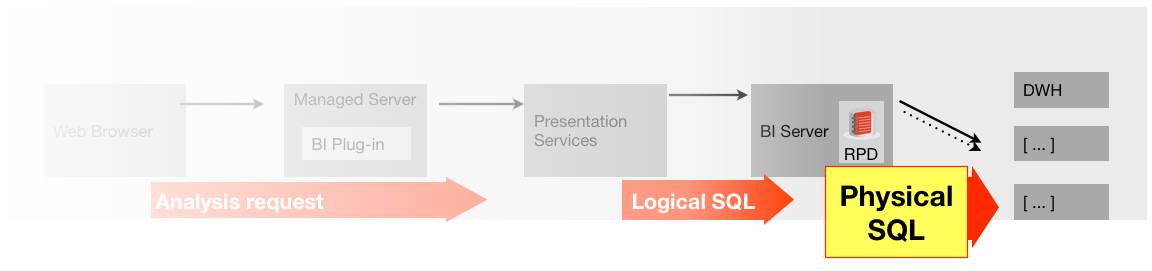
Next to consider is that each analysis sends a “Logical” SQL request to the BI Server. It is not common, but it is possible that a change to the binaries (version upgrade/patch) could introduce a regression that caused the Logical SQL to be generated incorrectly. Specific changes to the RPD can also cause the Logical SQL generation to change, potentially erroneously.
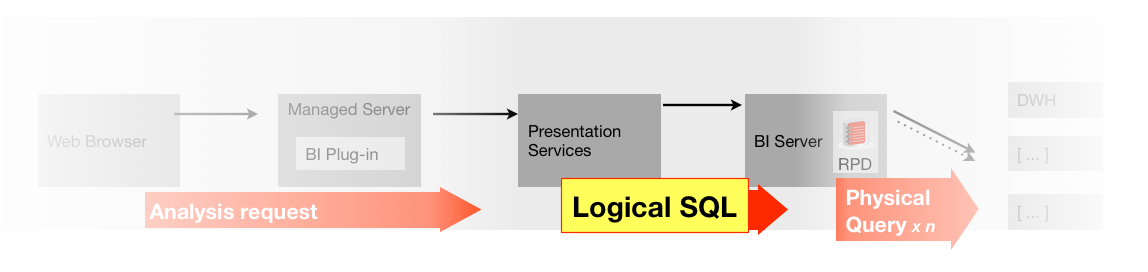
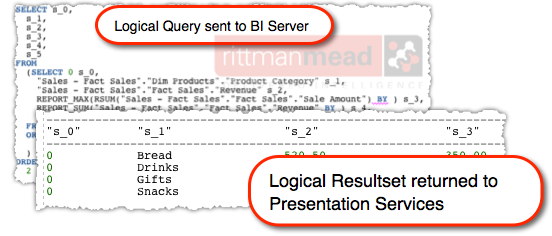
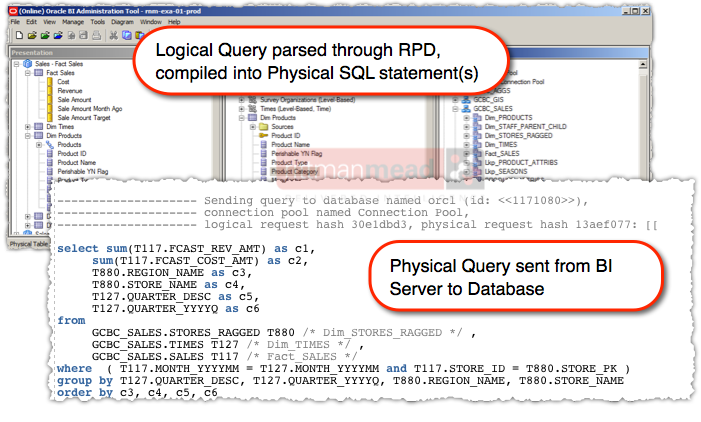
A “Logical” SQL request on the BI Server is parsed through the metadata layer, the RPD, and one or more “Physical” SQL statements are sent to the underlying data source(s). An error in the RPD could result in the Physical SQL being generated incorrectly.
Regression testing opportunities
To summarise the previous section, our testing points for regression are as follows.- The logical query generated by Presentation Services for an analysis
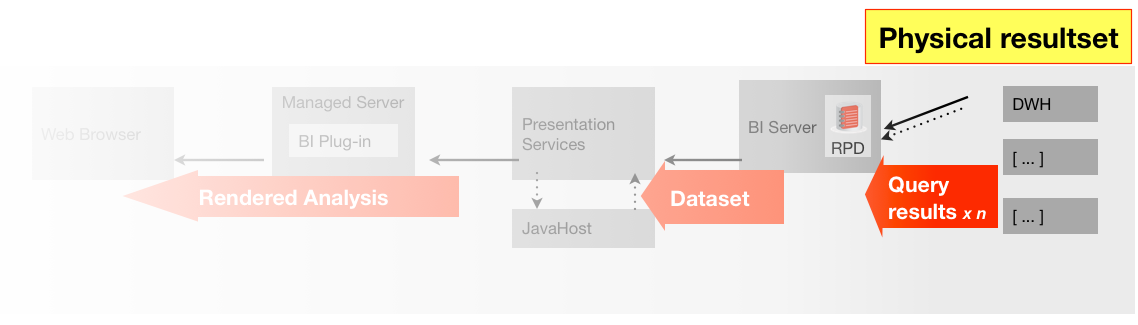
- The physical query/queries generated by the BI Server to retrieve the data from the data source(s)
- The data supplied by the data source to the BI server
- The data supplied by the BI server for an analysis (logical resultset)
- User interface, including the dashboard/analysis, taking into account both rendered data and presentation/UI.
- Does it look the same
- Are the numbers the same
- Telling a computer to fetch some data twice and compare the first result with the second is bread and butter automation.
- Trying to explain to a computer what a page “looks” like, or what a user interface “does” is extremely time consuming, and inevitably specific to the single item in question. Of course, we can programmatically compare the underlying code for a dashboard before and after a change, but the question I pose is whether we should.
Computers are blind
The user interface for an OBIEE end user is a web browser, and OBIEE builds its web pages through a set of languages and protocols that used to be quaintly referred to as “Web 2.0”. It uses HTML, CSS, XML, and JavaScript, taking plentiful advantage of asynchronous page loading and in-flight modifications to the Document Object Model (DOM) too. AJAX is a term which certainly covers some of the magic that goes on. The resulting user interface is pretty slick with drop down menus, expanding hierarchy trees, and partial dashboard rendering as data is returned rather than waiting for all analyses to complete. All of this omits the knockout blow that is Flash, used for rendering all graph objects in OBIEE and the subject of at notable UI bug in OBIEE 11.1.1.6. The “Developer Tools” option in modern web browsers gives us a glimpse into what is going on under the covers. We can see the number of resources that go into rendering a single page...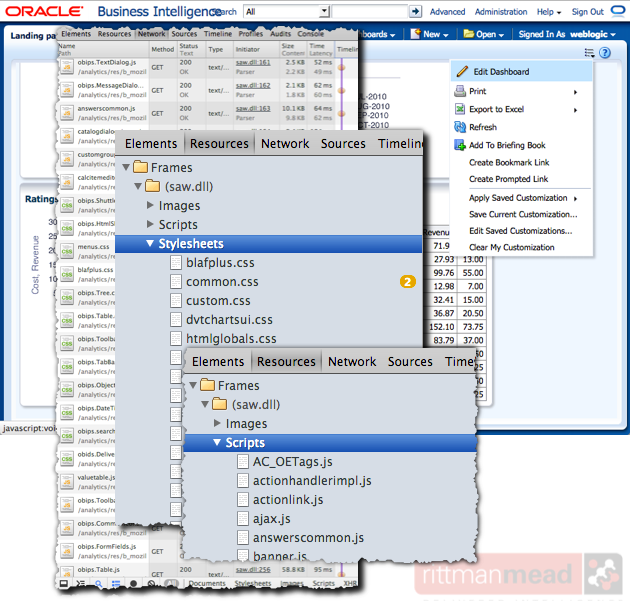 ...and how many layers there are to the object model:
...and how many layers there are to the object model:
 Getting a computer to interface with all of this, simulating a user interaction and parsing the response is possible with functional testing tools such as Selenium, Oracle Application Testing Suite, and HP’s QuickTest Professional. Each of these tools is capable of simulating a user (often by ‘recording’ a session as the starting point) and parsing the responses from OBIEE.
Getting a computer to interface with all of this, simulating a user interaction and parsing the response is possible with functional testing tools such as Selenium, Oracle Application Testing Suite, and HP’s QuickTest Professional. Each of these tools is capable of simulating a user (often by ‘recording’ a session as the starting point) and parsing the responses from OBIEE.
e_saw_14485_10_1_0_0:
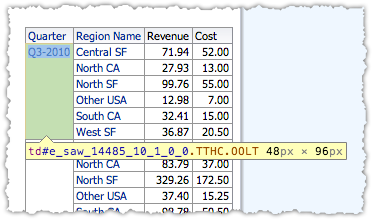
- define a particular part of the page alone to check remains the same (and risk chucking the baby out with the bath water, that is, missing other genuine regressions elsewhere on the page)
- compile a list of elements that we expect may change but that we don’t count as a regression (i.e. exceptions).
Conclusion
So, we come back to not how we test the front end but more should we, in every case? Given a finite amount of time, what are you going to get most benefit from in your regression tests? In the next post I will demonstrate one of the ways you can get the most "bang for your buck" when regression testing OBIEE, by concentrating your automation efforts on the query part of the OBIEE stack, and not the front end. Stay tuned!
Many thanks to Gianni Ceresa for his thoughts and assistance on this subject.