Lifting the Lid on OBIEE Internals with Linux Diagnostics Tools

There comes the point in any sufficiently complex or difficult problem diagnosis that the log files in OBIEE alone are not sufficient for building up a complete picture of what’s going on. Even with the debug/trace data that Presentation Services and other components can be configured precisely to write you’re sometimes just left having to guess what is going on inside the black box of each of the OBIEE system components.
Here we’re going to look at a couple of examples of lifting the lid just a little bit further on what OBIEE is up to, using standard Linux diagnostic tools. These are not something to be reaching for in the first instance, but more getting on to a last resort. Almost always the problem is simpler than you’ll think, and leaping for an network trace or stack trace is going to be missing the wood for the trees.
Diagnostics in action
At a client recently they had a problem with a custom skin deployment on a clustered (scaled-out) OBIEE deployment. Amongst other things the skin was setting the default palette for charts (viewui/chart/dvt-graph-skin.xml), and they were seeing only 50% of chart executions pick up the custom palette - the other 50% used the default. If either entire node was shut down, things were fine, but otherwise it was a 50:50 chance what the colours would be. Most odd….
When you configure a custom skin in OBIEE you should be setting CustomerResourcePhysicalPath in instanceconfig.xml, along with CustomerResourceVirtualPath. Both these are necessary so that Presentation Services knows:
- Logical - How to generate URLs for content requested by the user’s browser (eg logos, CSS files, etc).
- Physical - How to physically reference files on the file system that are read by OBIEE itself (eg XML files, language files)
The way the client had configured their custom skin was that it was on storage local to each node, and in a node-specific path, something like this:
- /data/instance1/s_custom/
- /data/instance2/s_custom/
Writing out the details in hindsight always makes a problem’s root cause a lot more obvious, but at the time this was a tricky problem. Let’s start with the basics. Java Host is responsible for rendering charts, and for some reason, it was not reading the custom colour scheme file from the custom skin correctly. Presentation Services uses all the available Java Hosts in a cluster to request charts, presumably on some kind of round-robin basis. An analysis request on NODE01 has a 50:50 chance of getting its chart rendered on Java Host on NODE01 or Java Host on NODE02:
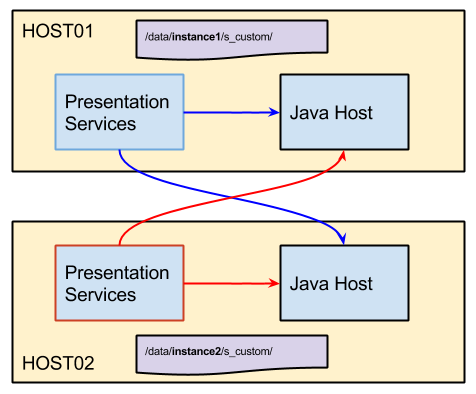
Turned all the log files up to 11 didn’t yield anything useful. For some reason half the time Java Host would just “ignore” the custom skin. Shutting down each node proved that in isolation the custom skin configuration on each node was definitely correct, because then the colours started working just fine. It was only when multiple Java Hosts across the nodes were active that there was a problem.
How Java Host picks up the custom skin is entirely undocumented, and I ended up figuring out that it must get the path to the skin as part of the chart request from Presentation Services. Since Presentation Services on NODE01 has been configured with a CustomerResourcePhysicalPath of /data/instance1/s_custom/, Java Host on NODE02 would fail to find this path (since on NODE02 the skin is located at /data/instance2/s_custom/) and so fall back on the default. This was my hypothesis that I then proved by making the path available for each skin available on each node (symlink, or using a standard path would also have worked, eg /data/shared/s_custom, or even better, a shared mount point), and from there everything worked just fine.
But a hypothesis and successful resolution alone wasn’t entirely enough. Sure the client was happy, but there was that little itch, that unknown “black box” system that appeared to behave how I had deduced, but could we know for sure?
tcpdump - network analysis
All of the OBIEE components communicate with each other and the outside world over TCP. When Presentation Services wants a chart rendered it does so by sending a request to Java Host – over TCP. Using the tcpdump tool we can see that in action, and inspect what gets sent:
$ sudo tcpdump -i venet0 -i lo -nnA 'port 9810'
The -A flag capture the ASCII representation of the packet; use -X if you want ASCII and hex. Port 9810 is the Java Host listen port.
The output looks like this:
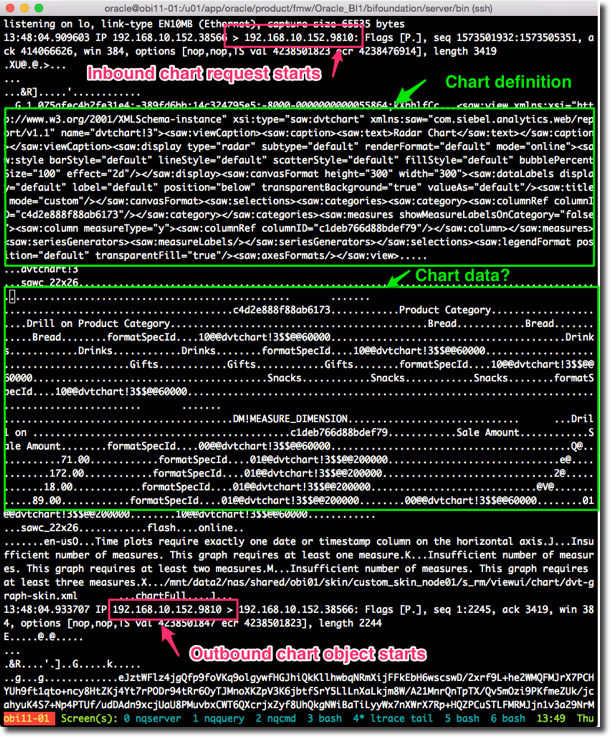
You’ll note that in this case it’s intra-node communication, i.e. src and dest IP addresses are the same. The port for Java Host (9810) is clear, and we can verify that the src port (38566) is Presentation Services with the -p (process) flag of netstat:
$ sudo netstat -pn |grep 38566 tcp 0 0 192.168.10.152:38566 192.168.10.152:9810 ESTABLISHED 5893/sawserver
So now if you look in a bit more detail at the footer of the request from Presentation Services that tcpdump captured you’ll see loud and clear (relatively) the custom skin path with the graph customisation file:
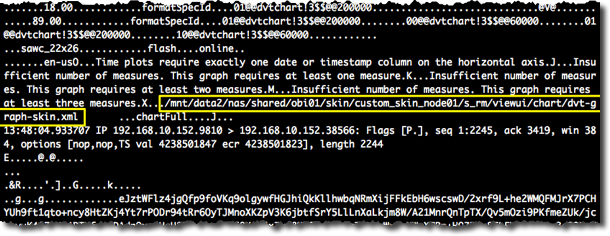
Proof that the Presentation Services is indeed telling Java Host where to go and look for the custom attributes (including colours)! NB this is on a test environment, so that paths vary from the /data/instance... example above)
strace - system call analysis
So tcpdump gives us the smoking gun, but can we find the corpse as well? Sure we can! strace is a tool for tracing system calls, and a fantastically powerful one, but here’s a very simple example:
$strace -o /tmp/obijh1_strace.log -f -p $(pgrep -f obijh1)
-o means to write it to file, -f follows child processes as well, and -p passes the process id that strace should attach to. Have set the trace running I run my chart, and then go and pick through my trace file.
We know it’s the dvt-graph-skin.xml file that Java Host should be reading to pick up the custom colours, so let’s search for that:
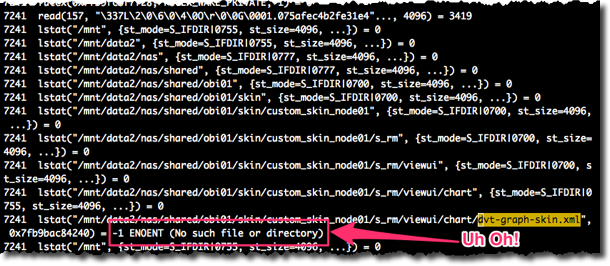
Well there we go – Java Host went to go and look for the skin in the path that it was given by Presentation Services, and couldn’t find it. From there it'll fall back on the product defaults.
Right Tool, Right Job
As as I said at the top of this article, these diagnostic tools are not the kind of things you’d be using day to day. Understanding their output is not always easy and it’s probably easy to do more harm than good with false assumption about what a trace is telling you. But, in the right situations, they are great for really finding out what is going on under the covers of OBIEE.
If you want to find out more about this kind of thing, this page is a great starting point.