Practical Tips for Oracle BI Applications 11g Implementations


As with any product or technology, the more you use it the more you learn about the "right" way to do things. Some of my experiences implementing Oracle Business Intelligence Applications 11g have led me to compile a few tips that will improve the overall process for installation and configuration and make the application more maintainable in the future. You can find me at KScope15 in Hollywood, FL beginning June 21st, presenting this exact topic. In this post I want to give you a quick preview of a couple of the topics in my presentation.
Data Extract Type - Choose Wisely
Choosing how the data is extracted from the source and loaded to the data warehouse target is an important part of the overall ETL performance in Oracle BI Applications 11g. In BI Apps, there are three extract modes to choose from:
- JDBC mode This default mode will use the generic Loading Knowledge Modules (LKM) in Oracle Data Integrator to extract the data from the source and stream it through the ODI Agent, then down to the target. The records are streamed through the agent to translate datatypes between heterogeneous data sources. That makes the JDBC mode useful only when the source database is non-Oracle (since the target for BI Apps will always be an Oracle database).
- Database link mode If your source is Oracle, then the database link mode is the best option. This mode uses the database link functionality built-in to the Oracle database, allowing the source data to be extracted across this link. This eliminates the need for an additional translation of the data as occurs in the JDBC mode.
- SDS mode This should really be called "GoldenGate mode", but I'm sure Oracle wants to keep their options open. In this mode, Oracle GoldenGate is used to replicate source transactions to the target data warehouse in what is called a Source Dependent Data Store (SDS) schema. This SDS schema mimics the source schema(s), allowing the SDE process to extract from the DW local SDS schema rather than across the network to the actual source. If the use of GoldenGate is an option, it's hands-down better than JDBC mode should you be extracting data from a non-Oracle source. (Have a look at my OTN ArchBeat 2-minute Tech Tip as I attempt beat the clock while discussing when to use GoldenGate with BI Apps!)
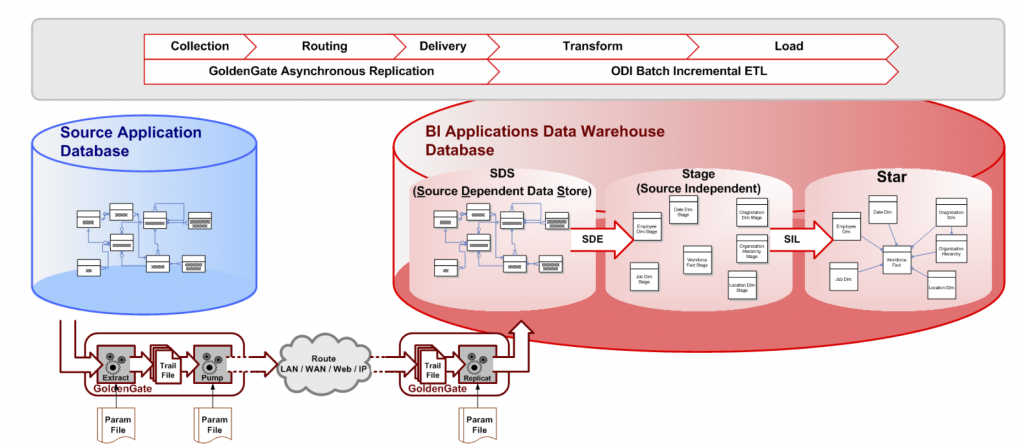
Let's go into a bit more detail about using GoldenGate with BI Applications. Because the SDS is setup to look exactly like the source schema, the Oracle Data Integrator pre-built Interfaces can change which source they are using from within the Loading Knowledge Module (LKM) by evaluating a variable (IS_SDS_DEPLOYED) at various points throughout the LKM. Using this approach, the GoldenGate integration can be easily enabled at any point, even after initial configuration. The Oracle BI Applications team did a great job of utilizing the features of ODI that allow the logical layer to be abstracted from the physical layer and data source connection. For further information about how to implement Oracle GoldenGate with Oracle BI Applications 11g, check out the OTN Technical article I wrote which describes the steps for implementation in detail.
Disaster Recovery
If the data being reported on in BI Applications is critical to your business, you probably want a disaster recovery process. This will involve an entirely different installation on a full server stack located somewhere that is not near the production servers. Now, there are many different approaches to DR with each of the products involved in BI Applications - OBIEE, ODI, databases, etc., but I think this approach is more simple than many others.
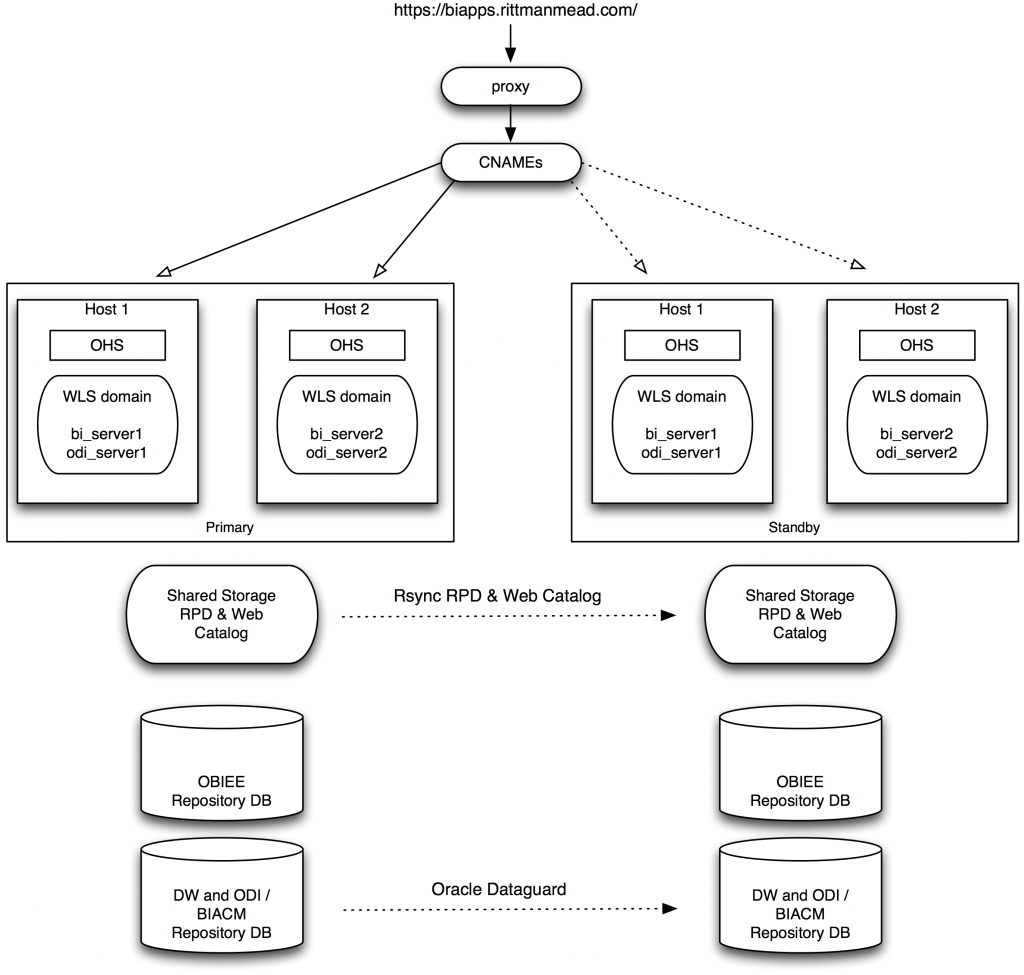
The installation of BI Apps would occur on each site (primary and standby) as standalone installations. It's critical that you have a well defined, hopefully scripted and automated, process for installation and configuration, since everything will need to be exactly the same between the two sites. Looking at the architecture diagram above, you can see the data warehouse, ODI repository, and BIACM repository schemas will be replicated from primary to standby via Oracle Dataguard. The OBIEE metadata repositories are not replicated due to much of the configuration information being stored in files rather than the database schema.
With the installation and configuration identical, any local, internal URLs will be setup to use the local site URL (e.g. http://biapps.rittmanmead-primary.com). The external URLs, such as the top-level site (e.g. http://biapps.rittmanmead.com/biacm) or database JDBC connection URLs, will all use canonical names (CNAMEs) as the URL. A CNAME is really just an alias used in the DNS, allowing an easy switch when redirecting from one site to another. For example, the CNAME biapps.rittmanmead-primary.com will have an alias of biapps.rittmanmead.com. This alias will switch to point to biapps.rittmanmead-standby.com during the failover / switchover process.
We can now run through a few simple steps to perform the failover or switchover to the standby server.
- Update Global CNAMEs
- Switch primary database via DataGuard
- Update the Web Catalog and Application Role assignments
- Start NodeManager, OHS, WebLogic AdminServer
- Update Embedded LDAP User GUID in ODI (if necessary)
- Start BI and ODI Managed Servers
- Update and Deploy the RPD
- Start the BI Services
Looks pretty straightforward, right? With the appropriate attention to detail up front during the installation and configuration, it becomes simple to maintain and perform the DR switchover and failover. I'll go into more detail on these topics and others, such as installation and configuration, LDAP integration, and high availability, during my presentation at KScope15 later this month. I hope to see you there!