Combining Spark Streaming and Data Frames for Near-Real Time Log Analysis & Enrichment

A few months ago I posted an article on the blog around using Apache Spark to analyse activity on our website, using Spark to join the site activity to some reference tables for some one-off analysis. In this article I’ll be taking an initial look at Spark Streaming, a component within the overall Spark platform that allows you to ingest and process data in near real-time whilst keeping the same overall code-based as your batch-style Spark programs.

Like regular batch-based Spark programs, Spark Streaming builds on the concept of RDDs (Resilient Distributed Datasets) and provides an additional high-level abstraction called a “discretized stream” or DStream, representing a continuous stream of RDDs over a defined time period. In the example I’m going to create I’ll use Spark Streaming’s DStream feature to hold in-memory the last 24hrs worth of website activity, and use it to update a “Top Ten Pages” Impala table that’ll get updated once a minute.

To create the example I started with the Log Analyzer example in the set of DataBricks Spark Reference Applications, and adapted the Spark Streaming / Spark SQL example to work with our CombinedLogFormat log format that contains two additional log elements. In addition, I’ll also join the incoming data stream with some reference data sitting in an Oracle database and then output a parquet-format file to the HDFS filesystem containing the top ten pages over that period.
The bits of the Log Analyzer reference application that we reused comprise of two scripts that compile into a single JAR file; a script that creates a Scala object to parse the incoming CombinedLogFormat log files, and other with the main program in. The log parsing object contains a single function that takes a set of log lines, then returns a Scala class that breaks the log entries down into the individual elements (IP address, endpoint (URL), referrer and so on). Compared to the DataBricks reference application I had to add two extra log file elements to the ApacheAccessLog class (referer and agent), and add some code in to deal with “-“ values that could be in the log for the content size; I also added some extra code to ensure the URLs (endpoints) quoted in the log matched the format used in the data extracted from our Wordpress install, which stores all URLs with a trailing forward-slash (“/“).
package com.databricks.apps.logs
case class ApacheAccessLog(ipAddress: String, clientIdentd: String,
userId: String, dateTime: String, method: String,
endpoint: String, protocol: String,
responseCode: Int, contentSize: Long,
referer: String, agent: String) {
}
object ApacheAccessLog {
val PATTERN = """^(S+) (S+) (S+) [([wd:/]+s[+-]d{4})] "(S+) (S+) (S+)" (d{3}) ([d-]+) "([^"]+)" "([^"]+)"""".r
def parseLogLine(log: String): ApacheAccessLog = {
val res = PATTERN.findFirstMatchIn(log)
if (res.isEmpty) {
ApacheAccessLog("", "", "", "","", "", "", 0, 0, "", "")
}
else {
val m = res.get
val contentSizeSafe : Long = if (m.group(9) == "-") 0 else m.group(9).toLong
val formattedEndpoint : String = (if (m.group(6).charAt(m.group(6).length-1).toString == "/") m.group(6) else m.group(6).concat("/"))
ApacheAccessLog(m.group(1), m.group(2), m.group(3), m.group(4),
m.group(5), formattedEndpoint, m.group(7), m.group(8).toInt, contentSizeSafe, m.group(10), m.group(11))
}
}
}
The body of the main application script looks like this - I'll go through it step-by-step afterwards:</>
package com.databricks.apps.logs.chapter1
import com.databricks.apps.logs.ApacheAccessLog
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SaveMode
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.streaming.{StreamingContext, Duration}
object LogAnalyzerStreamingSQL {
val WINDOW_LENGTH = new Duration(86400 * 1000)
val SLIDE_INTERVAL = new Duration(10 * 1000)
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("Log Analyzer Streaming in Scala")
val sc = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val postsDF = sqlContext.load("jdbc", Map(
"url" -> "jdbc:oracle:thin:blog_refdata/password@bigdatalite.rittmandev.com:1521:orcl",
"dbtable" -> "BLOG_REFDATA.POST_DETAILS"))
postsDF.registerTempTable("posts")
val streamingContext = new StreamingContext(sc, SLIDE_INTERVAL)
val logLinesDStream = streamingContext.textFileStream("/user/oracle/rm_logs_incoming")
val accessLogsDStream = logLinesDStream.map(ApacheAccessLog.parseLogLine).cache()
val windowDStream = accessLogsDStream.window(WINDOW_LENGTH, SLIDE_INTERVAL)
windowDStream.foreachRDD(accessLogs => {
if (accessLogs.count() == 0) {
println("No logs received in this time interval")
} else {
accessLogs.toDF()
// Filter out bots
val accessLogsFilteredDF = accessLogs
.filter( r => ! r.agent.matches(".*(spider|robot|bot|slurp|bot|monitis|Baiduspider|AhrefsBot|EasouSpider|HTTrack|Uptime|FeedFetcher|dummy).*"))
.filter( r => ! r.endpoint.matches(".*(wp-content|wp-admin|wp-includes|favicon.ico|xmlrpc.php|wp-comments-post.php).*")).toDF()
.registerTempTable("accessLogsFiltered")
val topTenPostsLast24Hour = sqlContext.sql("SELECT p.POST_TITLE, p.POST_AUTHOR, COUNT(*) as total FROM accessLogsFiltered a JOIN posts p ON a.endpoint = p.POST_SLUG GROUP BY p.POST_TITLE, p.POST_AUTHOR ORDER BY total DESC LIMIT 10 ")
// Persist top ten table for this window to HDFS as parquet file
topTenPostsLast24Hour.save("/user/oracle/rm_logs_batch_output/topTenPostsLast24Hour.parquet", "parquet", SaveMode.Overwrite)
}
})
streamingContext.start()
streamingContext.awaitTermination()
}
}
The application code starts then by importing Scala classes for Spark, Spark SQL and Spark Streaming, and then defines two variable that determine the amount of log data the application will consider; WINDOW_LENGTH (86400 milliseconds, or 24hrs) which determines the window of log activity that the application will consider, and SLIDE_INTERVAL, set to 60 milliseconds or one minute, which determines how often the statistics are recalculated. Using these values means that our Spark Streaming application will recompute every minute the top ten most popular pages over the last 24 hours.
package com.databricks.apps.logs.chapter1
import com.databricks.apps.logs.ApacheAccessLog
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SaveMode
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.streaming.{StreamingContext, Duration}
object LogAnalyzerStreamingSQL {
val WINDOW_LENGTH = new Duration(86400 * 1000)
val SLIDE_INTERVAL = new Duration(60 * 1000)
In our Spark Streaming application, we’re also going to load-up reference data from our Wordpress site, exported and stored in an Oracle database, to add post title and post author values to the raw log entries that come in via Spark Streaming. In the next part of the script then we define a new Spark context and then a Spark SQL context off-of the base Spark context, then create a Spark SQL data frame to hold the Oracle-sourced Wordpress data to later-on join to the incoming DStream data - using Spark’s new Data Frame feature and the Oracle JDBC drivers that I separately download off-of the Oracle website, I can pull in reference data from Oracle or other database sources, or bring it in from a CSV file as I did in the previous Spark example, to supplement my raw incoming log data.
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("Log Analyzer Streaming in Scala")
val sc = new SparkContext(sparkConf)
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
val postsDF = sqlContext.load("jdbc", Map(
"url" -> "jdbc:oracle:thin:blog_refdata/password@bigdatalite.rittmandev.com:1521:orcl",
"dbtable" -> "BLOG_REFDATA.POST_DETAILS"))
postsDF.registerTempTable("posts")
Note also how Spark SQL lets me declare a data frame (or indeed any RDD with an associated schema) as a Spark SQL table, so that I can later run SQL queries against it - I’ll come back to this at the end).
Now comes the first part of the Spark Streaming code. I start by defining a new Spark Streaming content off of the same base Spark context that I created the Spark SQL one off-of, then I use that Spark Streaming context to create a DStream that reads newly-arrived files landed in an HDFS directory - for this example I’ll manually copy the log files into an “incoming” HDFS directory, whereas in real-life I’d connect Spark Streaming to Flume using FlumeUtils for a more direct-connection to activity on the webserver.
val streamingContext = new StreamingContext(sc, SLIDE_INTERVAL)
val logLinesDStream = streamingContext.textFileStream("/user/oracle/rm_logs_incoming")
Then I call the Scala “map” transformation to convert the incoming DStream into an ApacheAccessLog-formatted DStream, and cache this new DStream in-memory. Next and as the final part of this stage, I call the Spark Streaming “window” function which packages the input data into in this case a 24-hour window of data, and creates a new Spark RDD every SLIDE_INTERVAL - in this case 1 minute - of time.
val accessLogsDStream = logLinesDStream.map(ApacheAccessLog.parseLogLine).cache() val windowDStream = accessLogsDStream.window(WINDOW_LENGTH, SLIDE_INTERVAL)
Now that Spark Streaming is creating RDDs for me to represent all the log activity over my 24 hour period, I can use the .foreachRDD control structure to turn that RDD into its own data frame (using the schema I’ve inherited from the ApacheAccessLog Scala class earlier on), and filter out bot activity and references to internal Wordpress pages so that I’m left with actual page accesses to then calculate the top ten list from.
windowDStream.foreachRDD(accessLogs => {
if (accessLogs.count() == 0) {
println("No logs received in this time interval")
} else {
accessLogs.toDF().registerTempTable("accessLogs")
// Filter out bots
val accessLogsFilteredDF = accessLogs
.filter( r => ! r.agent.matches(".*(spider|robot|bot|slurp|bot|monitis|Baiduspider|AhrefsBot|EasouSpider|HTTrack|Uptime|FeedFetcher|dummy).*"))
.filter( r => ! r.endpoint.matches(".*(wp-content|wp-admin|wp-includes|favicon.ico|xmlrpc.php|wp-comments-post.php).*")).toDF()
.registerTempTable("accessLogsFiltered")
Then, I use Spark SQL’s ability to join tables created against the windowed log data and the Oracle reference data I brought in earlier, to create a parquet-formatted file containing the top-ten most popular pages over the past 24 hours. Parquet is the default storage format used by Spark SQL and is suited best to BI-style columnar queries, but I could use Avro, CSV or another file format If I brought the correct library imports in.
val topTenPostsLast24Hour = sqlContext.sql("SELECT p.POST_TITLE, p.POST_AUTHOR, COUNT(*) as total FROM accessLogsFiltered a JOIN posts p ON a.endpoint = p.POST_SLUG GROUP BY p.POST_TITLE, P.POST_AUTHOR ORDER BY total DESC LIMIT 10 ")
// Persist top ten table for this window to HDFS as parquet file
topTenPostsLast24Hour.save("/user/oracle/rm_logs_batch_output/topTenPostsLast24Hour.parquet", "parquet", SaveMode.Overwrite)
}
})
Finally, the last piece of the code starts-off the data ingestion process and then continues until the process is interrupted or stopped.
streamingContext.start()
streamingContext.awaitTermination()
}
}
I can now go over to Hue and move some log files into the HDFS directory that the Spark application is running on, like this:
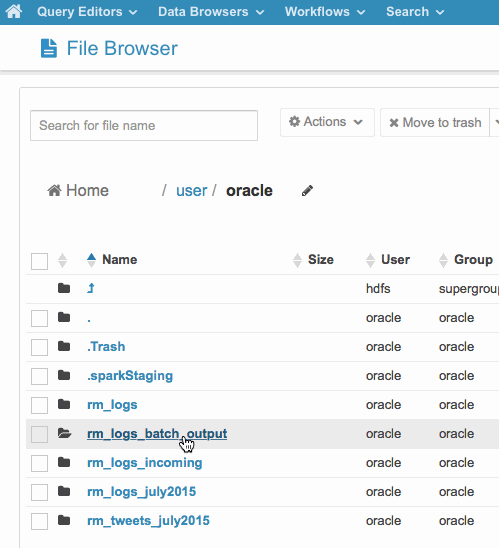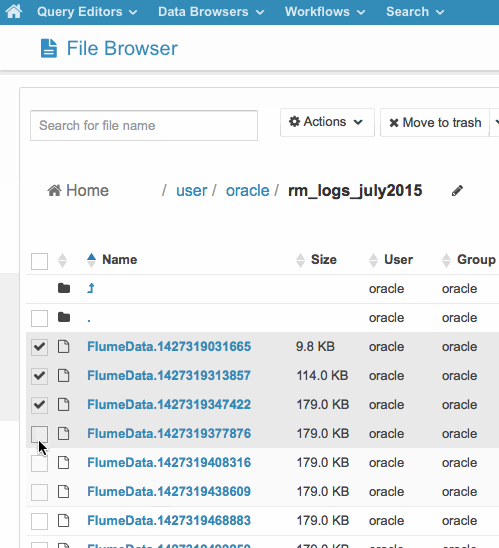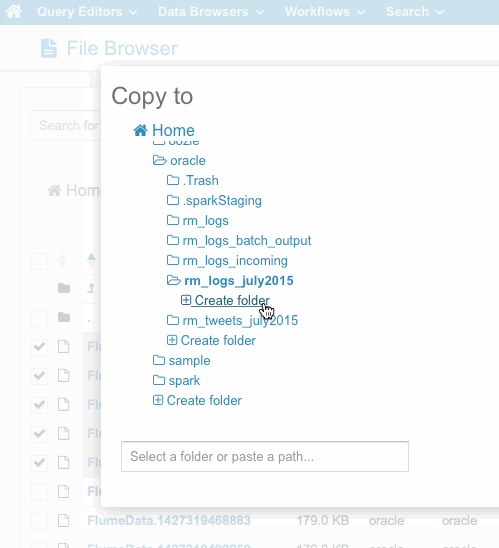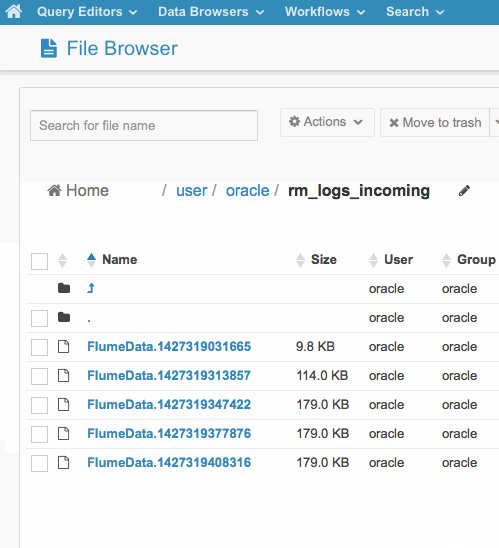
Then, based on the SLIDE_INTERVAL I defined in the main Spark application earlier on (60 seconds, in my case) the Spark Streaming application picks up the new files and processes them, outputting the results as a Parquet file back on the HDFS filesystem (these two screenshots should display as animated GIFs)
So what to do with the top-ten pages parquet file that the Spark Streaming application creates? The most obvious thing to do would be to create an Impala table over it, using the schema metadata embedded into the parquet file, like this:
CREATE EXTERNAL TABLE rm_logs_24hr_top_ten LIKE PARQUET '/user/oracle/rm_logs_batch_output/topTenPostsLast24Hour.parquet/part-r-00001.parquet' STORED AS PARQUET LOCATION '/user/oracle/rm_logs_batch_output/topTenPostsLast24Hour.parquet';
Then I can query the table using Hue again, or I can import the Impala table metadata into OBIEE and analyse it using Answers and Dashboards.

So that’s a very basic example of Spark Streaming, and I’ll be building on this example over the new few weeks to add features such as persistent storing of all processed data, and classification and clustering the data using Spark MLlib. More importantly, copying files into HDFS for ingestion into Spark Streaming adds quite a lot of latency and it’d be better to connect Spark directly to the webserver using Flume or even better, Kafka - I’ll add examples showing these features in the next few posts in this series.