ASO Slice Clears - How Many Members?

Essbase developers have had the ability to (comparatively) easily clear portions of our ASO cubes since version 11.1.1, getting away from fiddly methods involving manually contra-ing existing data via reports and rules files, making incremental loads substantially easier.
Along with the official documentation in the TechRef and DBAG, there are a number of excellent posts already out there that explain this process and how to effect "slice clears" in detail (here and here are just two I’ve come across that I think are clear and helpful). However, I had a requirement recently where the incremental load was a bit more complex than this. I am sure people must have fulfilled in the same or a very similar way, but I could not find any documentation or articles relating to it, so I thought it might be worth recording.
For the most part, the requirements I’ve had in this area have been relatively straightforward—(mostly) financial systems where the volatile/incremental slice is typically a months-worth (or quarters-worth) of data. The load script will follow this sort of sequence:
- [prepare source data, if required]
- Perform a logical clear
- Load data to buffer(s)
- Load buffer(s) to new database slice(s)
- [Merge slices]
With the last stage being run here if processing time allows (this operation precludes access to the cube) or in a separate routine "out of hours" if not.
The "logical clear" element of the script will comprise a line like (note: the lack of a "clear mode" argument means a logical clear; only a physical clear needs to be specified explicitly):
alter database 'Appname'.'DBName' clear data in region '{[Jan16]}'
or more probably
alter database 'Appname'.'DBName' clear data in region '{[&CurrMonth]}'
i.e., using a variable to get away from actually hard coding the member values to clear. For separate year/period dimensions, the slice would need to be referenced with a CrossJoin:
alter database 'Appname'.'DBName' clear data in region 'Crossjoin({[Jan]},{[FY16]})'
alter database '${Appname}'.'${DBName}' clear data in region 'Crossjoin({[&{CurrMonth]},{[&CurrYear]})'
which would, of course, fully nullify all data in that slice prior to the load. Most load scripts will already be formatted so that variables would be used to represent the current period that will potentially be used to scope the source data (or in a BSO context, provide a FIX for post-load calculations), so using the same to control the clear is an easy addition.
Taking this forward a step, I’ve had other systems whereby the load could comprise any number of (monthly) periods from the current year. A little bit more fiddly, but achievable: as part of the prepare source data stage above, it is relatively straightforward to run a select distinct period query on the source data, spool the results to a file, and then use this file to construct that portion of the clear command (or, for a relatively small number, prepare a sequence of clear commands).
The requirement I had recently falls into the latter category in that the volatile dimension (where "Period" would be the volatile dimension in the examples above) was a "product" dimension of sorts, and contained a lot of changed values each load. Several thousand, in fact. Far too many to loop around and build a single command, and far too many to run as individual commands—whilst on test, the "clears" themselves ran satisfyingly quickly, it obviously generated an undesirably large number of slices.
So the problem was this: how to identify and clear data associated with several thousand members of a volatile dimension, the values of which could change totally from load to load.
In short, the answer I arrived at is with a UDA.
The TechRef does not explicitly say or give examples, but because the Uda function can be used within a CrossJoin reference, it can be used to effect a clear: assume the Product dimension had an UDA of CLEAR against certain members…
alter database 'Appname'.'DBName' clear data in region 'CrossJoin({Uda([Product], "CLEAR")})'
…would then clear all data for all of those members. If data for, say, just the ACTUAL scenario is to be cleared, this can be added to the CrossJoin:
alter database 'Appname'.'DBName' clear data in region 'CrossJoin({Uda([Product], "CLEAR")}, {[ACTUAL]})'
But we first need to set this UDA in order to take advantage of it. In the load script steps above, the first step is prepare source data, if required. At this point, a SQLplus call was inserted to a new procedure that
- examines the source load table for distinct occurrences of the "volatile" dimension
- populates a table (after initially truncating it) with a list of these members (and parents), and a third column containing the text "CLEAR":
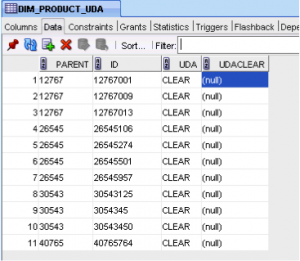
A "rules" file then needs to be built to load the attribute. Because the outline has already been maintained, this is simply a case of loading the UDA itself:
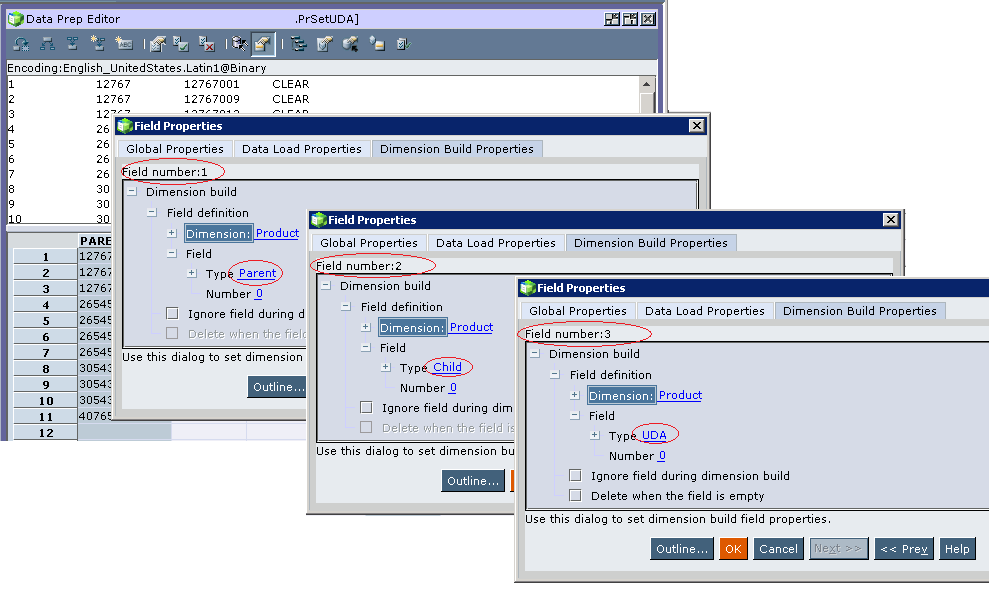
In the "Essbase Client" portion of the load script, prior to running the "clear" command, the temporary UDA table needs to be loaded using the rules file to populate the UDA for those members of the volatile dimension to be cleared:
import database 'AppName'.'DBName' dimensions connect as 'SQLUsername' identified by 'SQLPassword' using server rules_file 'PrSetUDA' on error write to 'LogPath/ASOCurrDataLoad_SetAttr.err';
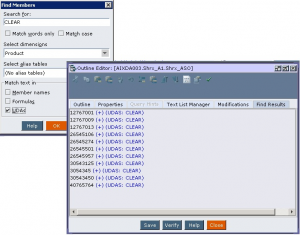
With the relevant slices cleared, the load can proceed as normal.
After the actual data load has run, the UDA settings need to be cleared. Note that the prepared table above also contains an empty column, UDACLEAR. A second rules file, PrClrUDA, was prepared that loads this (4th) column as the UDA value—loading a blank value to a UDA has the same effect as clearing it.
The broad steps of the load script therefore become these:
- [prepare source data, if required]
- ascertain members of volatile dimension to clear from load source
- update table containing current load members / CLEAR attribute
- Load CLEAR attribute table
- Perform a logical clear
- Load data to buffers
- Load buffer(s) to new database slice(s)
- [Merge slices]
- Remove CLEAR attributes
So not without limitations—if the data was volatile over two dimensions (e.g., Product A for Period 1, Product B for Period 2, etc.) the approach would not work (at least, not exactly as described, although in this instance you could possible iterate around the smaller Period dimension)—but overall, I think it’s a reasonable and flexible solution.
Clear / Load Order
While not strictly part of this solution, another little wrinkle to bear in mind here is the resource taken up by the logical clear. When initializing the buffer prior to loading data into it, you have the ability to determine how much of the total available resource is used for that particular buffer—from a total of 1.0, you can allocate (e.g.) 0.25 to each of 4 buffers that can then be used for a parallel load operation, each loaded buffer subsequently writing to a new database slice. Importing a loaded buffer to the database then clears the "share" of the utilization afforded to that buffer.
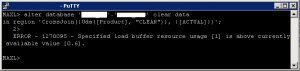
Although not a "buffer initialization" activity per se, a (slice-generating) logical clear seems to occupy all of this resource—if you have any uncommitted buffers created, even with the lowest possible resource utilization of 0.01 assigned, the logical clear will fail:
The Essbase Technical Reference states at "Loading Data Using Buffers":
While the data load buffer exists in memory, you cannot build aggregations or merge slices, as these operations are resource-intensive.
It could perhaps be argued that as we are creating a "clear slice," not merging slices (nor building an aggregation), that the logical clear falls outside of this definition, but a similar restriction certainly appears to apply here too.
This is significant as, arguably, the ideally optimum incremental load would be along the lines of
- Initialize buffer(s)
- Load buffer(s) with data
- Effect partial logical clear (to new database slice)
- Load buffers to new database slices
- Merge slices into database
As this would both minimize the time that the cube was inaccessible (during the merge), and also not present the cube with zeroes in the current load area. However, as noted above, this does not seem to be possible—there does not seem to be a way to change the resource usage (RNUM) of the "clear," meaning that this sequence has to be followed:
- Effect partial logical clear (to new database slice)
- Initialize buffer(s)
- Load buffer(s) with data
- Load buffers to new database slices
- Merge slices into database
I.e., the ‘clear’ has to be fully effected before the initialization of the buffers. This works as you would expect, but there is a brief period—after the completion of the "clear" but before the load buffer(s) have been committed to new slices—where the cube is accessible and the load slice will show as "0" in the cube.