Data Integration Tips: ODI 12c – Who Changed My Table Names?


It’s Sunday night (well, technically Monday morning now), and we have just enough time for another one of my Data Integration Tips. This one, revolving around Oracle Data Integrator 12c, has been on my mind for some time now, so I figured we better just get it out there. Imagine this; you’ve upgraded from Oracle Data Integrator (ODI) 11g to ODI 12c and executed the first test Mapping. But hey…what happened to my C$ table names? And wait a minute, the I$ tables look a bit different as well! Let’s dive in and uncover the truth, shall we?
The Scenario
In the 11g version of Oracle Data Integrator, we could only load one single target table per mapping (or Interface, as they were called way back then). Now, in ODI 12c, we have the new flow-based mapping paradigm, allowing us to choose our sources, apply different components (joins, filters, pivot, aggregates, etc), and load as many targets as we like. Quite an upgrade, if you ask me! But with this redesign comes some minor, albeit important, change under the covers. The temporary tables used to store data that is loaded from a source, across the network, and into a target, known as C$ or Loading tables, are generated by the ODI Substitution API called from within a Knowledge Module step. The underlying code that creates the temp tables has changed to output a different format for the table names. What exactly does that mean for our C$ tables? And why do we care?
In the beginning, the C$ tables were named for the target table. If there were multiple source tables, the C$ name would be indexed - C$_0, C$_1, etc. For example, if your source to target mapping looked like this: F0010 —> ACCOUNT_MASTERS, then the loading table was named C$_0ACCOUNT_MASTERS. If there was a join between two tables executed on staging, then the second loading table would be named C$_1ACCOUNT_MASTERS.
So…what changed in ODI 12c? Let’s take a look at a few mapping examples.
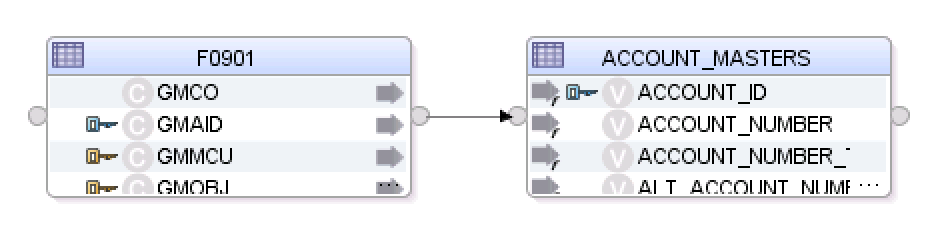
In this mapping, the C$ table is now named after the source datastore. Instead of C$_0ACCOUNT_MASTERS, we have C$_0F0010. That can be an interesting challenge for data warehouse teams who rely on specific naming conventions for debugging, monitoring, etc. Ok, so let’s take a look at another example.
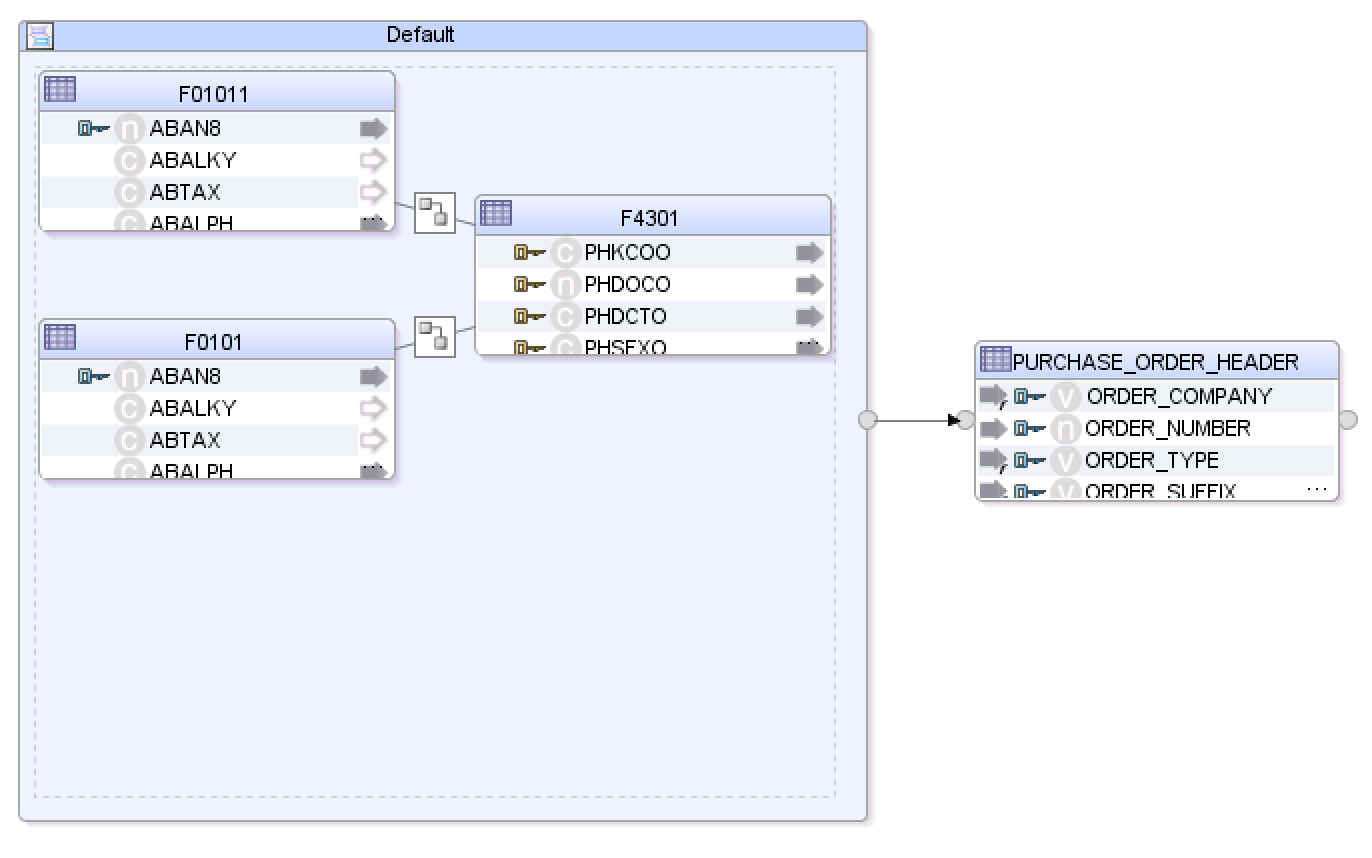
Ok, so normally I wouldn’t work with a Dataset component, but this is a look at the Mapping after an upgrade from ODI 11g. I could use the Convert to Flow feature, but as you’ll find out by reading on, it wouldn’t help with our temp table naming issues. In this example, the loading table is named C$_0DEFAULT. What’s this “default" business all about? Well, that is derived from the Dataset Component name. I must say, that’s much worse than just switching from the target table name to the source name. Yikes! Ok, one final test...

Oh boy. In this case, the resulting table is called C$_0FILTER. The name? It’s based on the Filter Component name. I’m sensing a pattern here. Basically the name of any component that is mapped to the target table, and in the physical design mapped to an access point, will be used to generate the C$ loading table name.
Digging a bit deeper into the Knowledge Modules, we find that the create loading object step of the KMs invokes the following method.
<%=odiRef.getTable("L", "COLL_NAME", "W")%>
The COLL_NAME refers to the loading table name, while the other options “L” & “W” refer to the format and source of the schema name that will be prefixed to the resulting table name. As mentioned previously, this method would return the target table name with the C$ prefix. Now, it returns the source table or component name for the specific source dataset that is being extracted and loaded into the target work schema. Here’s another way to show these differences in naming conventions:
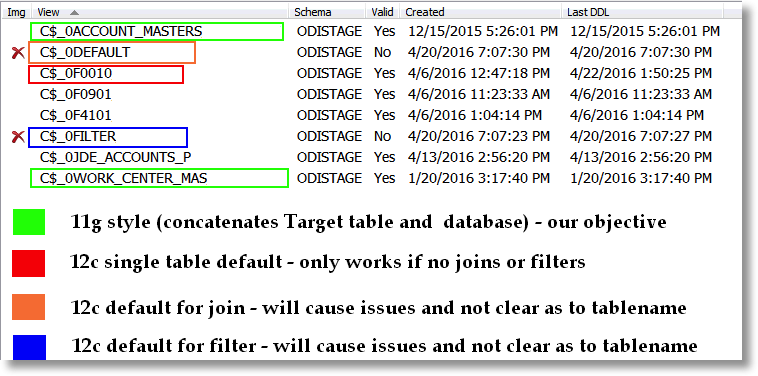
This image is based on a specific use case in which the Oracle Data Integrator customer was using the C$ tables in debugging. As you can see, the naming really doesn’t lend itself to understanding which target the C$ table was created to load.
Here’s the Tip...
Now that we understand what drives the C$ table name, we can workaround the issue. While the use case above is somewhat unique to folks who have upgraded from Oracle Data Integrator 11g, the use of components rather than tables in the naming of temporary objects can be quite confusing. We can easily change the output of <%=odiRef.getTable("L", "COLL_NAME", "W")%> by changing the component alias, or name, within the mapping. That’s an easy enough task for just a few mappings, but when you’ve upgraded hundreds, or even thousands, to ODI 12c - you’re in for some serious manual labor. Unless, of course, you dive into some Groovy script and the ODI SDK.
In the code snippet below, we first find the mapping we’re interested in editing. Then, work our way through the different components that may exist on the mapping and need a name change. This code was written specifically to handle Dataset, Filter, and source Datastore components only. Any additional components would need to be added to the list or, better yet, a different approach written in Groovy to find the last component before the final target Datastore. Hmm, next DI Tip?
Mapping mapToEdit = mapfinder.findByName(folder, mapName)
try {
//fix filter name.
filterComp = mapToEdit.findComponent("Filter") //find the filter named Filter.
if(filterComp != null) {
filterComp.setName(targName)
out.println(mapName + " filter renamed.")
} else {
//fix dataset name.
datasetComp = mapToEdit.findComponent("Default_DS") //find the dataset named Default.
if(datasetComp != null) {
datasetComp.setName(targName)
out.println(mapName + " dataset renamed.")
} else {
//fix source datastore name.
sources = mapToEdit.getSources()
for(sourceComp in sources) {
datastoreComp = sourceComp
}
datastoreComp.setName(targName)
out.println(mapName + " source datastore renamed.")
}
}
} catch(MapComponentException e) {
out.println e.toString()
}
tme.persist(mapToEdit)
The “targName" variable in this snippet is set to the target datastore name concatenated with the target data server name. That’s a specific use case, but the key takeaway is that the component name cannot be set to the target datastore name exactly. There must be a slight difference, since components cannot have the exact same name within a single mapping. Another caveat, if we had multiple target tables, this approach may not work out so well. But, again, coming from ODI 11g that’s a non-issue. This code can be run against a project, project folder, or even individual mappings, making it an easy way to change thousands of objects in seconds. Man I love Groovy and the ODI SDK!
That seems to solve our naming issue by modifying our loading table name into something more meaningful than C$_0FILTER. Groovy has come to the rescue and allowed us to batch change mappings in an instant. It seems we’ve completed this Data Integration Tip successfully.
But Wait, There’s More
I did mention earlier that the I$ table had an issue as well. Oh brother. The I$, or integration table, is the result of the mapping logic stored as a dataset in the I$ table just prior to loading into the final target. There is only a slight change to the ODI Substitution API method used in generating the integration table name, but again, just slight enough to bother processes built around the naming conventions.
In the past, the integration table name was based on the target table alias. But now in the latest version of ODI, the I$ table name is built based on the target datastore resource name. Again, this could potentially be problematic for those customers interested in using a different logical name for a physical target table. Something more readable, perhaps. Or maybe removing redundant characters that exist in all tables. Either way, we have to deal with a slight change in the code.
In researching a way to modify the way the I$ table is created, I came across an interesting issue. The call to odiRef.getTableName("INT_SHORT_NAME”) is supposed to return the integration table name alone, without any schema prefix attached to it. So in the previous example, when our target table was named ACCOUNT_MASTERS, the resulting table should have been I$_ACCOUNT_MASTERS. The original call to odiRef.getTable("L", "INT_NAME”, "W”) actually returns ODISTAGE.I$_JDE_ACCOUNT_MASTERS, based on the resource name of the datastore object and prepending the work schema name. Using the INT_SHORT_NAME, we expected a different result. But instead, the code generated a name like this: %INT_PRFJDE_ACCOUNT_MASTERS. This must be a bug in ODI 12.2.1, but I haven’t found it yet in My Oracle Support.
To work around this whole mess, we just searched for the work schema name and removed it from the table name, while replacing the unnecessary characters as well. All of this was completed using Java within the Knowledge Module steps. In the "Define Java Variable” step, which was custom added to setup Java variables in the KM, the below function was included. It lets you perform a substring while specifying length as a parameter. Found and repurposed from here.
String mySubString(String myString, int start, int length) {
return myString.substring(start, Math.min(start + length, myString.length()));
Then, in the "Set Java Variable” task, again custom, the code below was added to create the integration table name:
ITABLENAME ="<%=odiRef.getTable("L", "INT_NAME", "W")%>".replace("_JDE_","_");
ITABLENAME = mySubString(BMINAME, BMINAME.indexOf(".") + 1, 26);
The end result was a temporary integration table named I$_ACCOUNT_MASTERS, just as we were planning.
So there you have it, another Data Integration Tip shared with the ODI public. Hopefully this, or one of the other many DITips shared by Rittman Mead, can help you solve one of your challenging problems with Oracle Data Integration solutions. Please let me know of any Data Integration Tips you may need solved by commenting below or emailing me at michael.rainey@rittmanmead.com. And if you need a bit more help with your Data Integration setup, feel free to reach out and the experts at Rittman Mead will be glad to help!