Data Visualization Desktop 12.2.2.0: Data Flow Component

My previous post contained a brief description of Data Visualization Desktop (DVD) new features in 12.2.2.0, in terms of sources, visualisations and components. In this post we're going to simulate a typical analyst use case and understand how DVD can support the process.
Data Visualisation Desktop is a tool aimed at departmental analysis, with data coming from different sources and results that need to be delivered quickly. Given the ad-hoc nature of it, traditional long term IT-driven Business Intelligence processes often won’t suffice. In this example we'll have a deep look at DVD's Data Flow component and how it can be used to create an ETL flow in order to analyse data coming from a multitude of sources. Data Flow is new functionality introduced in DVD 12.2.2.0.
Preamble: being Italian I can't avoid talking about football, the example provided in this post will analyse some Serie A data together with some Fantasy Football information in order to understand which players I should choose for my team.
Data Sources
In order to analyse Serie A players I based my research on the following data points:
- Players cost: Excel file containing Team, Role and Fantasy Football Cost for each Serie A player. This file can change match by match since Cost of a single players can vary reflecting his performances.
- Players statistics: CSV files containing players statistics like goal scored, yellow and red cards, assists and fantasy football mark for every match of the current and past season.
For the purpose of the example I'm assuming the Players cost file is an XLSX received manually by the analyst (think at Budget data) and the Players statistics data stored in an Hive table.
Creating Data Sources in DVD
Data Visualization Desktop has a native connector to Hive, so just need to click on "Data Sources", then Create -> Connection and select "Apache Hive". The setup is pretty simple, we need to specify the host, port, username and password of the Hive Server.
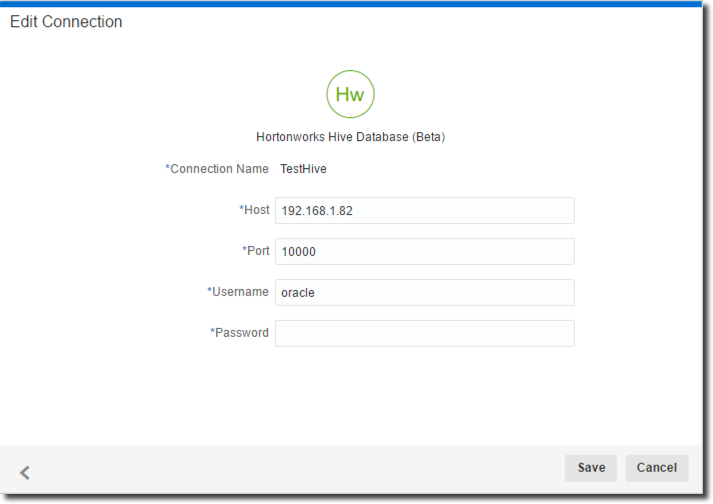
The next step is creating a new Data Source and select the newly created "TestHive" as source. The list of Hive's databases and, selecting FantasyFootball, the list of tables are visible.
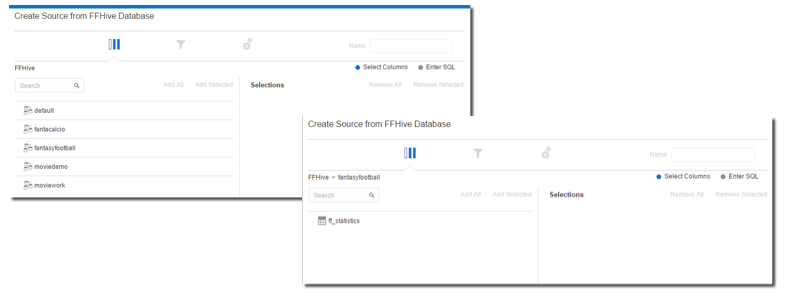
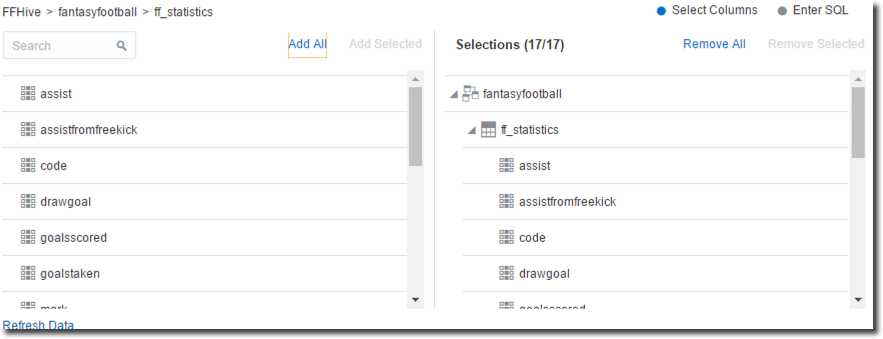
After clicking on the ff_statistics table we can select and import the columns. There is also an option to check or directly enter the SQL if needed. After clicking OK (and checking that no errors arise) we are ready to use the Hive table.
The "Players Cost" Excel file, received manually by the analyst, can be directly updated using the Data Source -> Create -> Data Source -> File option.
DVD automatically detects the column types and provides a preview of the content
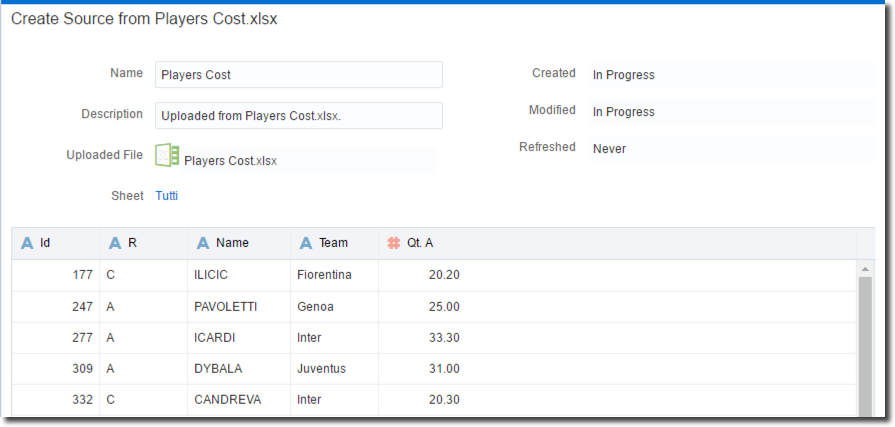
Once the data source is saved we are ready to start manipulating the data.
Data Flow
Our initial goal is to exclude from the statistics table any data quality issues. This could be down to invalid CSVs, as well as players not existing in "Players Cost" file (if they were sold to teams outside Serie A or they stopped their career). To do so we can use the Data Flow option included in DVD and accessible in the Data Source page.
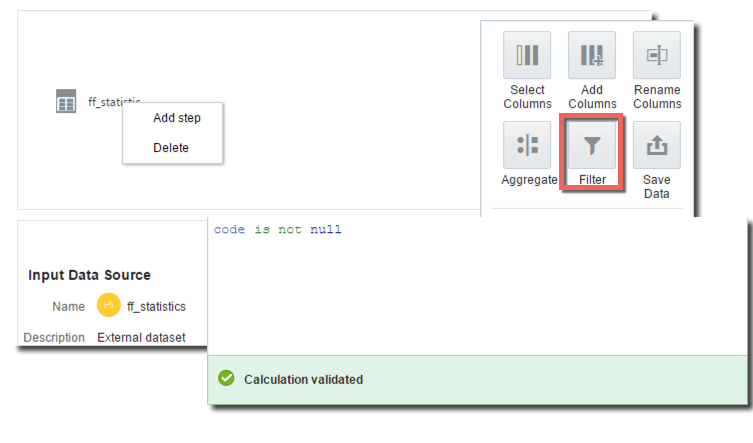
The first step is to select ff_statistics from list of sources, right click and select "Add Step". From the list of options presented we can select Filter and remove all the invalid data by simply only include rows where the "Code" is not empty [null].
The Data Flow chart now includes the Filter component. Following step is to bring in the "Players cost" file in the flow by selecting the Add Data option. Then it's time to join the two sources, we can do that by selecting both them and choosing the Join option.
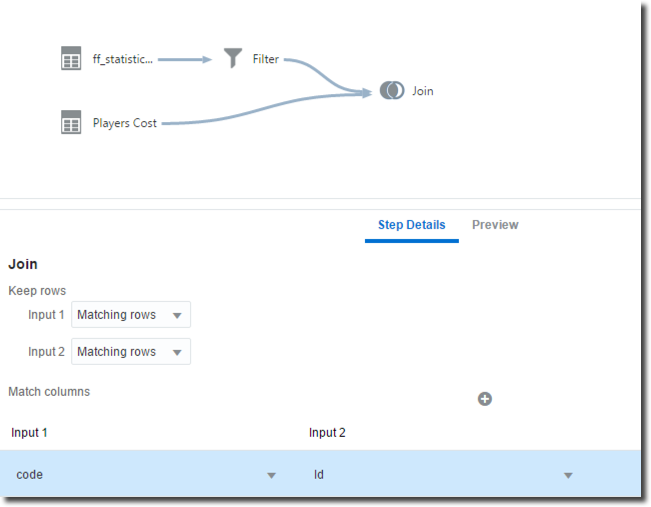
We can specify the columns which will be used in the joining condition and the join type (inner or outer) by selecting the desired option in the Keep Rows section (between Matching rows or All rows). For the purpose of our analysis we'll keep only the matching rows of the two datasets (inner join) since we are interested in all players listed in Players Cost and having a valid set of statistics in Players Statistics.
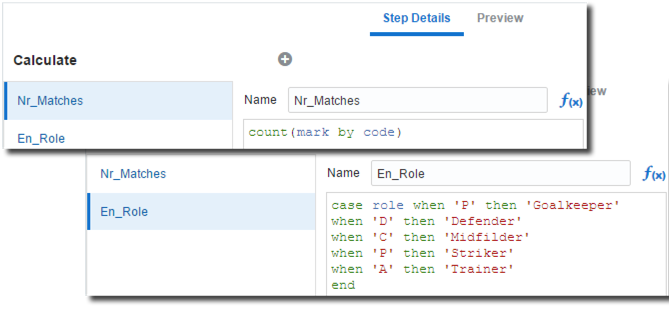
Now we can enrich the data set further, by adding derived metrics and attributes:
- Count of Matches: The number of valid matches (having a not null grade) played by so far by each player. This will be used later to filter out all players having less than 10 valid games since those are less likely to play most of the games.
- Role Translation: Roles are specified in Italian, a simple CASE WHEN can translate them in English.
The enrichment can be achieved by creating an additional Add Columns Step and filling properly the formulas.
After filtering out all players with less than 10 valid marks, an Aggregate step can be added to set the aggregation level and methods. The Aggregate step should be included in every Data Flow since it's the unique place where Attribute/Measure and aggregation definitions can be made. A Data Flow without the Aggregation step will provide a default column definition that may result in an unusable output data source.
Finally we can store the end resultset locally in order to proceed with the analysis.
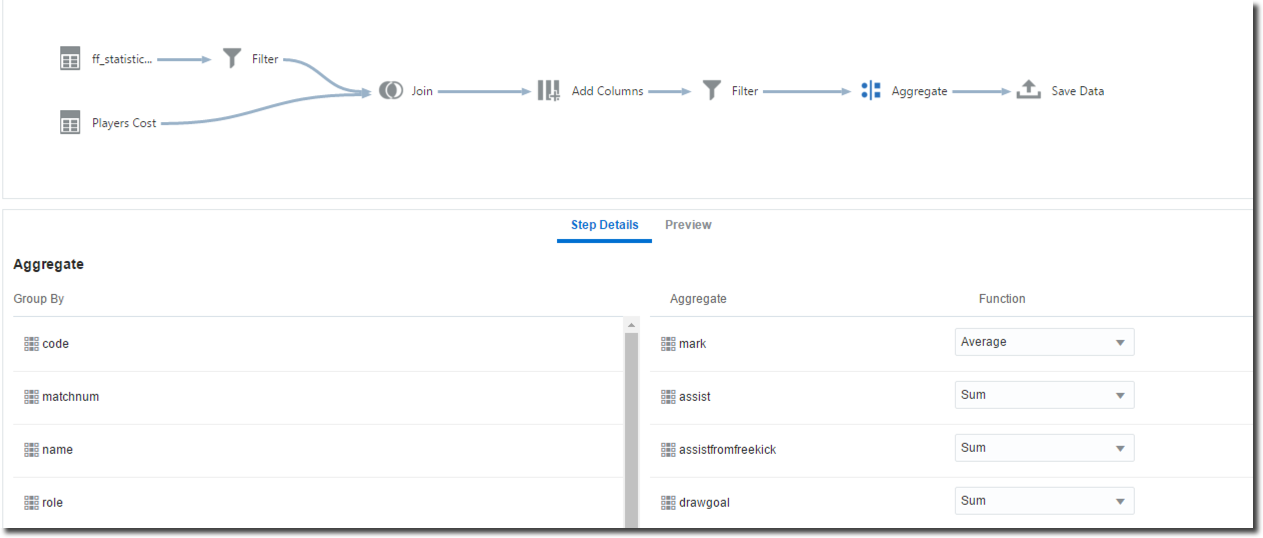
We can now execute the data flow and FantasyFootball is automatically added to the list of DVD's Data Sources. The Data Flow can also be stored in DVD in order to be re-executed when necessary.
Keep in mind that Data Flow works locally on the workstation where DVD is installed, so data extraction and manipulation will generate a load on the system based on the data volume and complexity of the steps.
Project
Before creating a project we can review the resulting FantasyFootball dataset settings and change the Attribute/Measure definition of my Columns as well as the type of aggregation.
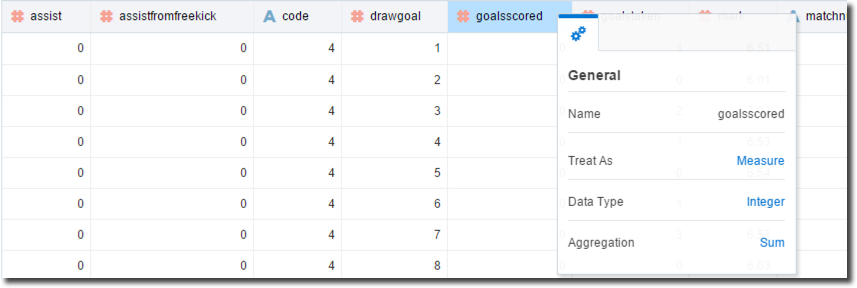
As written before it's better to define Attributes/Measures with an Aggregate step in the Data Flow since any setting changed directly in the dataset will be overwritten when the Data Flow is re-executed.
With the data preparation work completed, now is time to start creating a project using the FantasyFootball dataset. As written in my previous post a number of new visualisations is available with DVD 12.2.2.0, some are used in the example below like Chord, Parallel and Sankey diagrams.
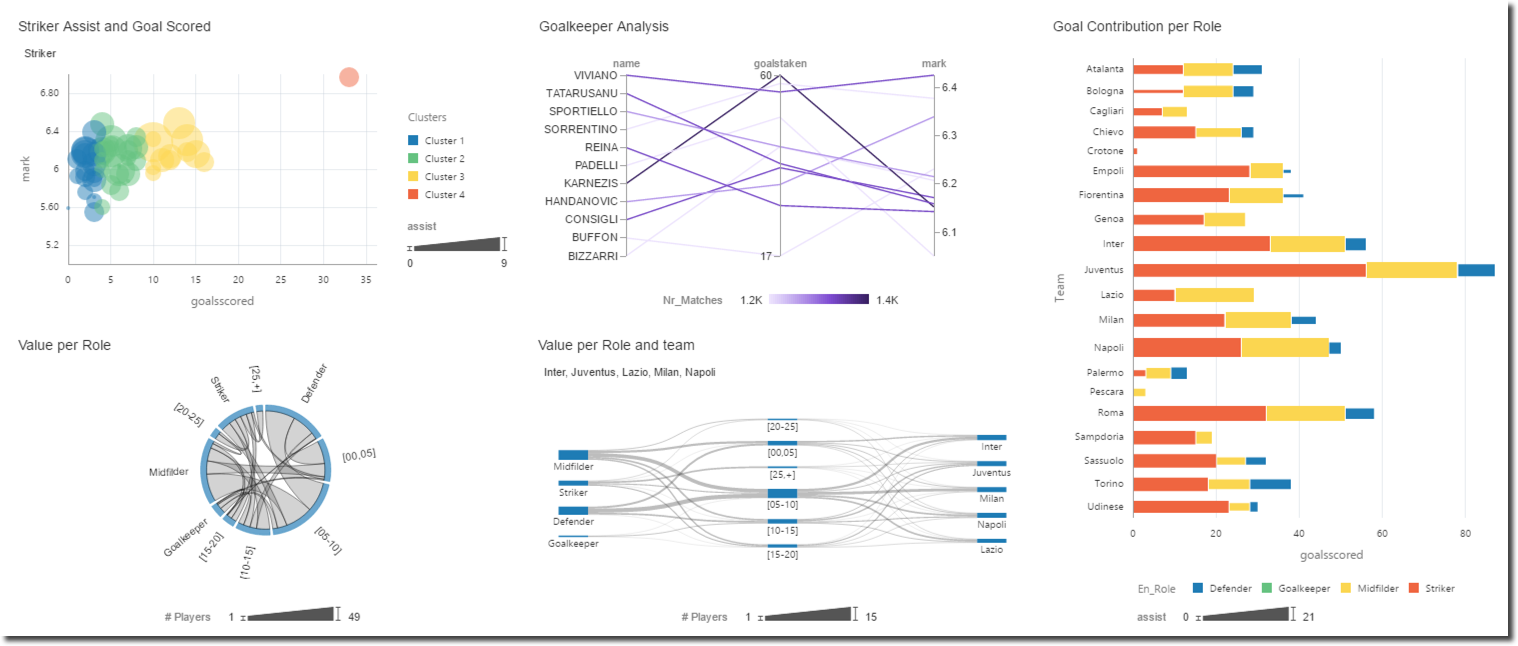
Unfortunately I'll not share the details of my findings since those could be used against me in the competition but Hey....that Higuain looks like a good player!
In this post we saw a typical analyst use case, with data coming from multiple sources needing to be joined together and cleansed. All operations done manually via Excel that can now be automated, saved and re-executed with DVD's Data Flow.