Oracle Data Integrator 12c: Getting Started - Components and Architecture

I’ve decided that it’s time for a refresher on Oracle Data Integrator 12c. I’m writing a Getting Started series to help folks get interested in the product and maybe even teach a few old dogs (including myself) some new tricks. In my [last post](GHOST_URL/2016/10/odi12c-gettingstarted-what-is-odi/" target="_blank), I shared the history of ODI and a bit about what sets it apart from other ETL tools on the market. In this article, I’ll walk through different components of Oracle Data Integrator and some of the architecture choices you’ll need to make in order to get started with ODI 12c.
Components
Before diving into the architecture, we need to understand the different components that are part of the Oracle Data Integrator installation.
Repositories
ODI is driven by metadata. This metadata is stored away in two different repositories: the Master repository and the Work repository. The Master repository contains information about security (users, profiles, etc), topology (data connections, contexts, physical/logical schemas), and ODI versioning. Each Master repository can be linked to one or more Work repositories. Work repositories can be of 2 different types: development or execution. In a Development Work repository you’ll find all of the design objects (mappings, packages, procedures, etc) and datastore metadata. The Execution Work repository only stores the execution objects, Scenarios and Load Plans, and there is no development capability. More on all of these objects in a later post.
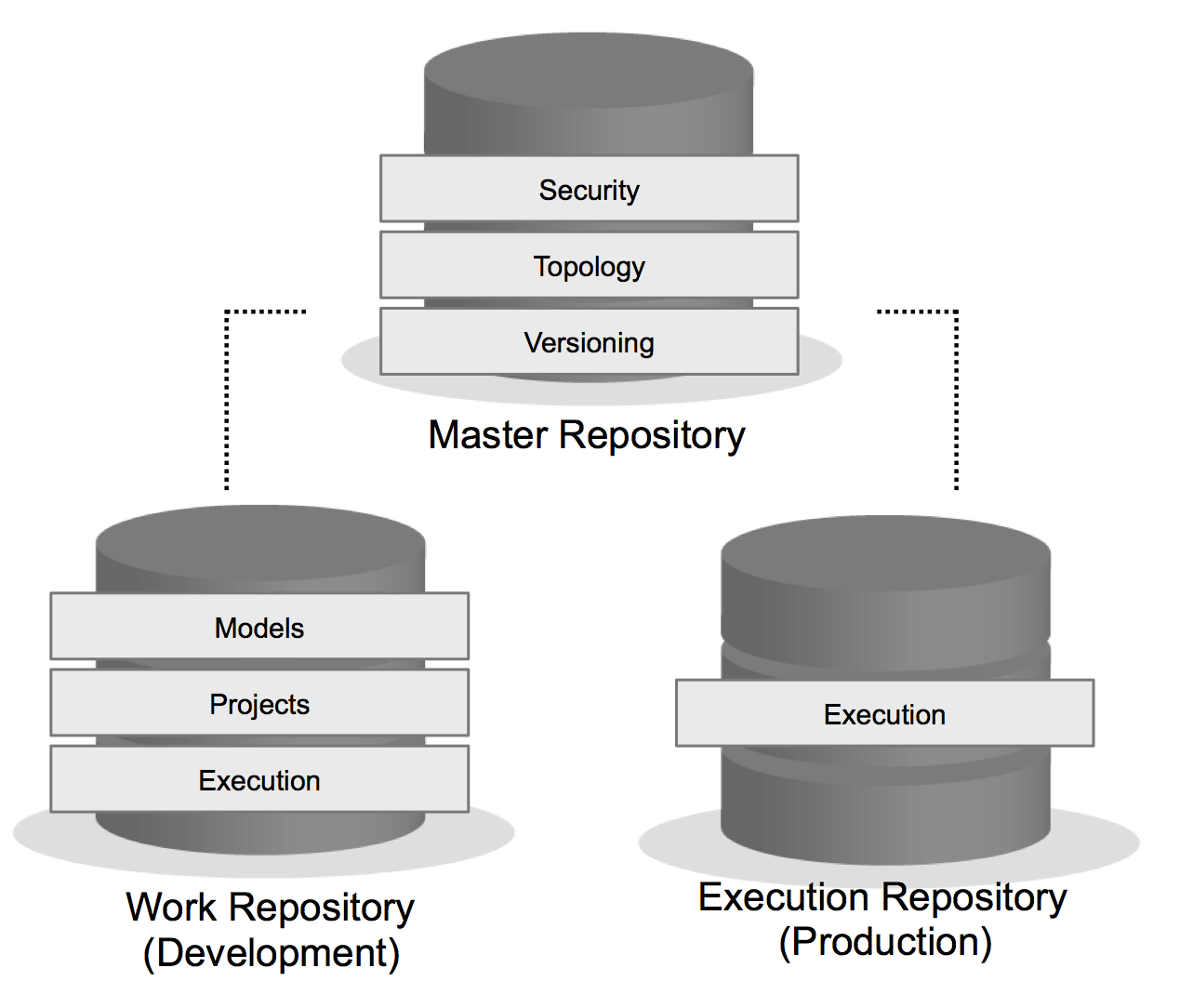
The Master and Work repositories can reside in the same database schema or as their own schemas in the same database instance. The latter practice was more common in the past, before the Repository Creation Utility (RCU) was really the main mechanism for creating the repositories. The RCU doesn’t provide an option for separating the repositories into two different schemas, therefore the standard is to use one single schema. But that’s not the only reason, it also stems from the best practice of separating your environments in entirety; development, test, production, so each can be maintained, upgraded, and patch separately. We’ll jump into the environment setup further down.
Agents
The Oracle Data Integrator [Agent](https://docs.oracle.com/middleware/1221/core/ODING/GUID-C68567CE-238C-4C41-B16B-88F0A0F6A7F1.htm#ODING934" target="_blank) is what orchestrates the execution of processes created in ODI. At runtime, agents will be used to run Load Plans and Scenarios via an ODI schedule, command line call, web service call, or a third-party scheduler. Agents are accessed via http/https requests, regardless of how they are called into action.
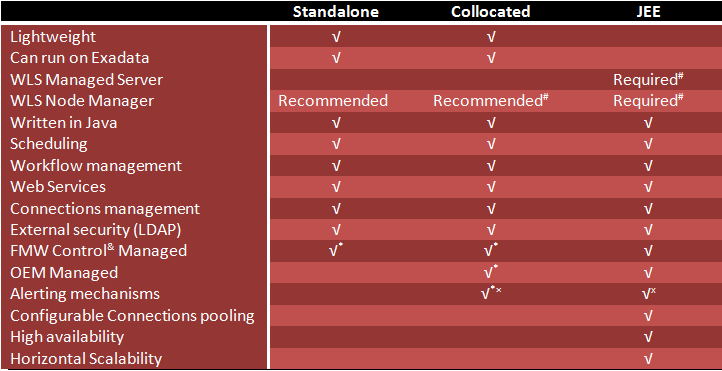
There are 3 types ODI 12c of agents:
- JEE Agent
Implemented as a deployment in Weblogic Server 12c, the JEE Agent allows you to use the features of WLS, such as clustering for high availability and JDBC connection pooling. - Standalone Agent
The Standalone Agent is a lightweight Java application that is typically installed to run closest to where most of the transformations will occur. In most data warehouse setups, this is on the data warehouse server. - Colocated Agent
This type of agent is essentially a Standalone Agent that is managed via Weblogic Server. If you want to manage all of your agents via WLS, this is the way to go.
A great article from the ODI A-Team, [ODI Agents: Standalone, JEE and Colocated](http://www.ateam-oracle.com/odi-agents-standalone-jee-and-colocated/" target="_blank), describes the agent types in further detail, including the comparison of agent features chart, found below.
Studio
ODI Studio is a Java based development environment based on the JDeveloper framework. Studio is installed on client machines and used to connect to the master and work repositories to access the ODI metadata and perform object development. Essentially, this is where the magic happens!
Architecture - It Depends.
With any good question comes the answer, “it depends”. Before we can choose an architecture for ODI, the system requirements must be determined, allowing us to work through the “it depends” answer more clearly. Let’s dive right in with some potential requirements that may be necessary for a proper data integration setup.
High Availability
A key decision that drives which components of Oracle Data Integrator will be installed and configured stems from the need for a highly available ETL process. If there is a critical process or reporting that relies on ODI, then HA will be a requirement. Not only that, but you’ll want to look at using something like Oracle RAC for the repository database in order to keep it up and running. Finally, high availability won’t save you from an entire data center going offline, so ensure you have a disaster recovery process in place as well.
Environments Required
How many environments do you need? Let’s start with the minimum, Development, Test/QA, and Production. Ok, well if you’re a small shop you might be able to get away without Test/QA, but not recommended. I would also add a 4th environment, Hotfix, which will store the production development objects, allowing your team to fix a production issue quickly without having to restore code from source control. The purpose of understanding the number of environments upfront is to determine how many application servers and database servers will be required for the entire Oracle Data Integrator setup. There’s yet another [great article from the Oracle A-Team](http://www.ateam-oracle.com/how-many-odi-master-repositories-should-we-have/" target="_blank) that describes the use of the ODI Master Repository across these many environments.
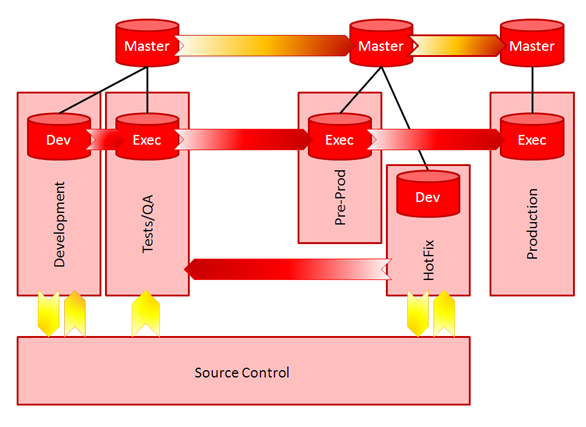
Lifecycle Management and Deployment Process
As you can see in the environments image above, there are also different arrows showing the deployment process and use of source control. The deployment process is usually the easy part to determine: Migrate ODI execution objects from Dev—>Test—>Prod. But the mechanism for doing so might be a bit different, especially if (or more likely, when) source control is introduced.
Oracle Data Integrator 12c can integrate with Subversion, and soon Git, for full lifecycle management capabilities. ODI also has its own object versioning, but it really is only to be used as a last resort. Often, teams have developed their own process around exporting objects to XML, loading into a source control system, and migrating to the next environment. Whichever process you determine is best for your organization, or if you plan to piggy-back on what’s currently in play for developers at your company, you’ll want to ensure the correct components are introduced into the architecture.
Sources and Targets
This is about the types and location of the data sources that ODI will need to connect to. If you have a set of flat files on a server that is unreachable from the machine where the ODI agent is installed, you’ll need a new Standalone agent placed somewhere that can pull from the file server. Drawing up the entire “planned” data flow will help to sort out these decisions early on, especially if you introduce big data into the mix.
Security
Finally, everyone’s favorite topic: [security](https://docs.oracle.com/middleware/1221/odi/administer-develop/security.htm#ODIAD678" target="_blank). There are many aspects to security within ODI, including how developers access ODI Studio and how to secure your ETL processes and the application itself. As mentioned earlier, the ODI Agents are called via a web request. The addition of SSL can further secure transmission of these requests, but may also introduce additional setup. If you have a large team of ETL developers, or maybe just a company policy on how applications are to be accessed, ODI can be integrated with your organization’s LDAP via the external authentication setup. With these and other considerations for ODI security, be sure to sort this out during the requirements and architecture phase.
There are many other questions that will need to be answered in order to properly choose your architecture, but hopefully this will get you started. As always, you can join one of the [Rittman Mead ODI bootcamps](https://www.rittmanmead.com/odi-12c-bootcamp/" target="_blank) to learn more from one of our experts on the product. Up next in the Getting Started series, we’ll look at Oracle Data Integrator installation and configuration.
Oracle Data Integrator 12c: Getting Started series: