ETL Offload with Spark and Amazon EMR - Part 1 - Introduction

We recently undertook a two-week Proof of Concept exercise for a client, evaluating whether their existing ETL processing could be done faster and more cheaply using Spark. They were also interested in whether something like Redshift would provide a suitable data warehouse platform for them. In this series of blog articles I will look at how we did this, and what we found.
Background
The client has an existing analytics architecture based primarily around Oracle database, Oracle Data Integrator (ODI), Oracle GoldenGate, and Oracle Business Intelligence Enterprise Edition (OBIEE), all running on Amazon EC2. The larger architecture in the organisation is all AWS based too.
Existing ETL processing for the system in question is done using ODI, loading data daily into a partitioned Oracle table, with OBIEE providing the reporting interface.
There were two aspects to the investigation that we did:
-
Primarily, what would an alternative platform for the ETL look like? With lots of coverage recently of the concept of "ETL offloading" and "Apache-based ETL", the client was keen to understand how they might take advantage of this
Within this, key considerations were:
- Cost
- Scalability
- Maintenance
- Fit with existing and future architectures
-
The second aspect was to investigate whether the performance of the existing reporting could be improved. Despite having data for multiple years in Oracle, queries were too slow to provide information other than within a period of a few days.
Oracle licenses were a sensitive point for the client, who were keen to reduce - or at least, avoid increased - costs. ODI for Big Data requires additional licence, and so was not in scope for the initial investigation.
Data and Processing
The client uses their data to report on the level of requests for different products, including questions such as:
- How many requests were there per day?
- How many requests per product type in a given period?
- For a given product, how many requests were there, from which country?
Data volumes were approximately 50MB, arriving in batch files every hour. Reporting requirements were previous day and before only. Being able to see data intra-day would be a bonus but was not a requirement.
High Level Approach
Since the client already uses Amazon Web Services (AWS) for all its infrastructure, it made sense to remain in the AWS realm for the first round of investigation. We broke the overall requirement down into pieces, so as to understand (a) the most appropriate tool at each point and (b) the toolset with best overall fit. A very useful reference for an Amazon-based big data design is the presentation Big Data Architectural Patterns and Best Practices on AWS. Even if you're not running on AWS, the presentation has some useful pointers for things like where to be storing your data based on volumes, frequency of access, etc.
Data Ingest
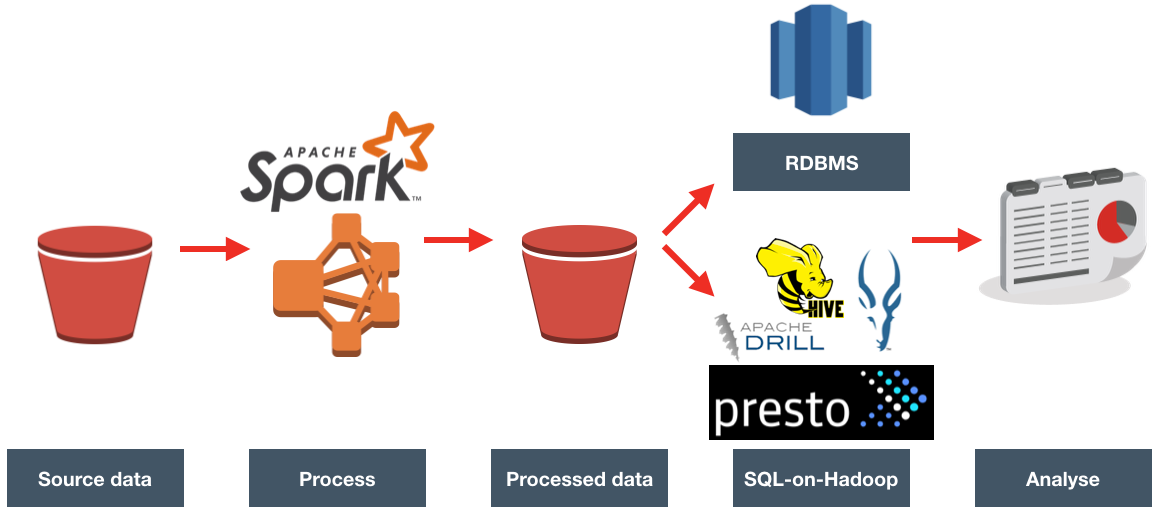
The starting point for the data was Amazon's storage service - S3, in which the data files in CSV format are landed by an external process every hour.
Processing (Compute)
Currently the processing is done by loading the external data into a partitioned Oracle table, and resolving dimension joins and de-duplication at query time.
Taking away any assumptions, other than a focus on 'new' technologies (and a bias towards AWS where appropriate), we considered:
-
Switch out Oracle for Redshift, and resolve the joins and de-duplication there
- Loading the data to Redshift would be easy, but would be switching one RDBMS-based solution for another. Part of the aim of the exercise was to review a broader solution landscape than this.
-
Use Hadoop-based processing, running on Elastic Map Reduce (EMR):
- Hive QL to process the data on S3 (or HDFS on EMR)
- Not investigated, because provides none of the error handling etc that Spark would, and Spark has SparkSQL for any work that needs doing in SQL.
- Pig
- Still used, but 'old' technology, somewhat esoteric language, and superseded by Spark
- Spark
- Support for several languages including commonly-used ones such as Python
- Gaining increasing levels of adoption in the industry
- Opens up rich eco-system of processing possibilities with related projects such as Machine Learning, and Graph.
- Hive QL to process the data on S3 (or HDFS on EMR)
We opted to use Spark to process the files, joining them to the reference data, and carrying out de-duplication. For a great background and discussion on Spark and its current place in data architectures, have a listen to this podcast.
Storage
The output from Spark was written back to S3.
Analytics
With the processed data in S3, we evaluated two options here:
- Load it to Redshift for query
- Query in-place with a SQL-on-Hadoop engine such as Presto or Impala
- With the data at rest on S3, Amazon's Athena is also of interest here, but was released after we carried out this particular investigation.
The presumption was that OBIEE would continue to provide the front-end to the analytics. Oracle's Data Visualization Desktop tool was also of interest.
In the next post we'll see the development environment that we used for prototyping. Stay tuned!