ETL Offload with Spark and Amazon EMR - Part 5 - Summary

This is the final article in a series documenting an exercise that we undertook for a client recently. Currently running an Oracle-based datawarehouse platform, the client asked for our help in understanding what a future ETL and reporting platform could look like, given the current landscape of tools available. You can read the background to the project, how we developed prototype code, deployed it to Amazon, and evaluated tools for analysing the data.
Whilst the client were generally aware of new technologies, they wanted a clear understanding of what these looked like in practice. Is it viable, as is being touted, to offload ETL entirely to open-source tools? Could they do this, without increasing their licensing costs?
The client are already well adopted to newer technologies, running their entire infrastructure on the Amazon Web Services (AWS) cloud. Given this usage of AWS, our investigation was based around deployment of the Elastic Map Reduce (EMR) Hadoop platform. Many of the findings made during the investigation are as applicable to other Hadoop platforms though, including CDH running on Oracle's Big Data Appliance.
We isolated a single process within the broader part of the client's processing estate for exploration. The point of our study was not less to implement this specific piece of functionality in the most optimal way, but to understand how in general processing would look on another platform in an end-to-end flow. Before any kind of deployment into Production of this design there would be further iterations, particularly around performance. These are discussed further below.
Overview of the Solution
The source data landed in Amazon S3 (similar in concept to HDFS), in CSV format, once per hour. We loaded each file, processed it to enrich it with reference data, and wrote it back to S3.
The enriched data was queried directly, with Presto, and also loaded into Redshift for querying there.
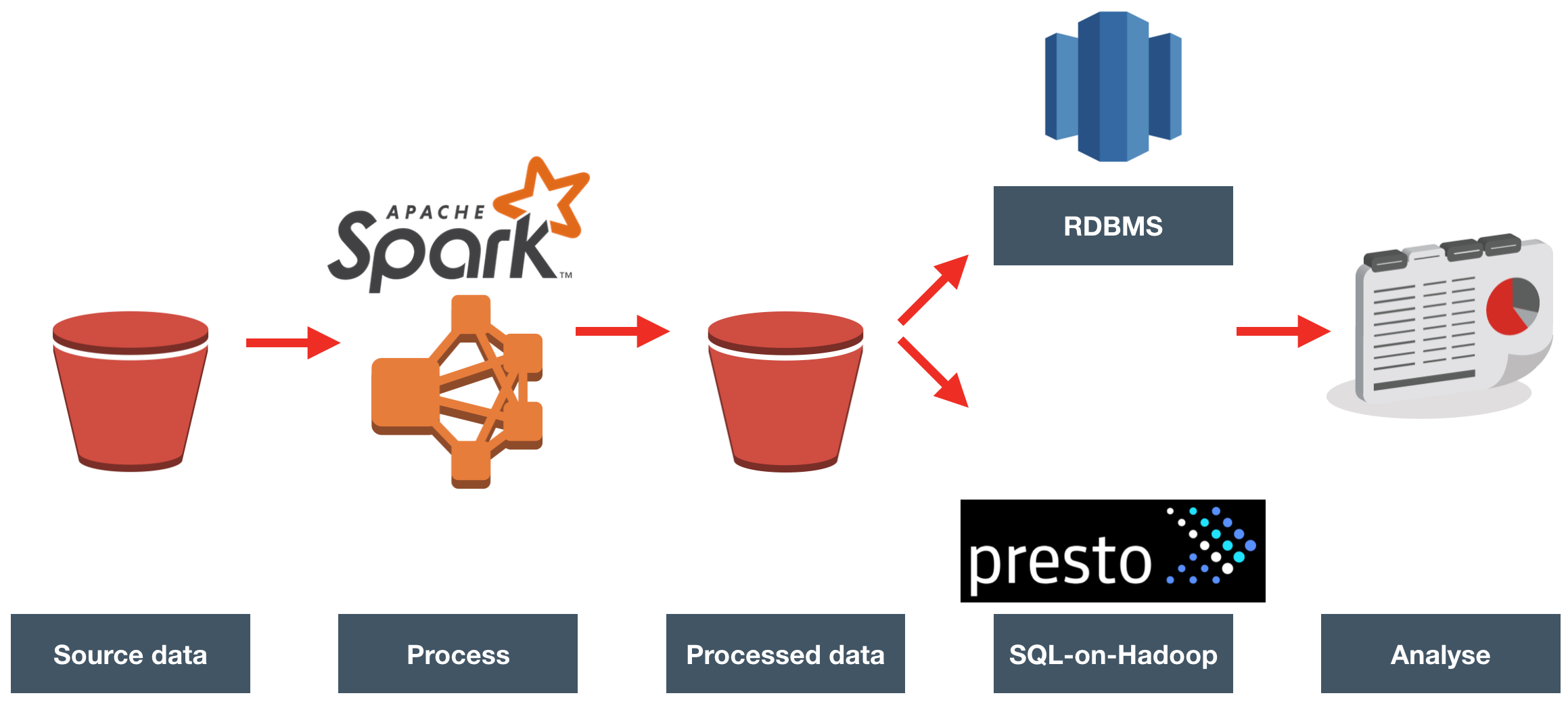
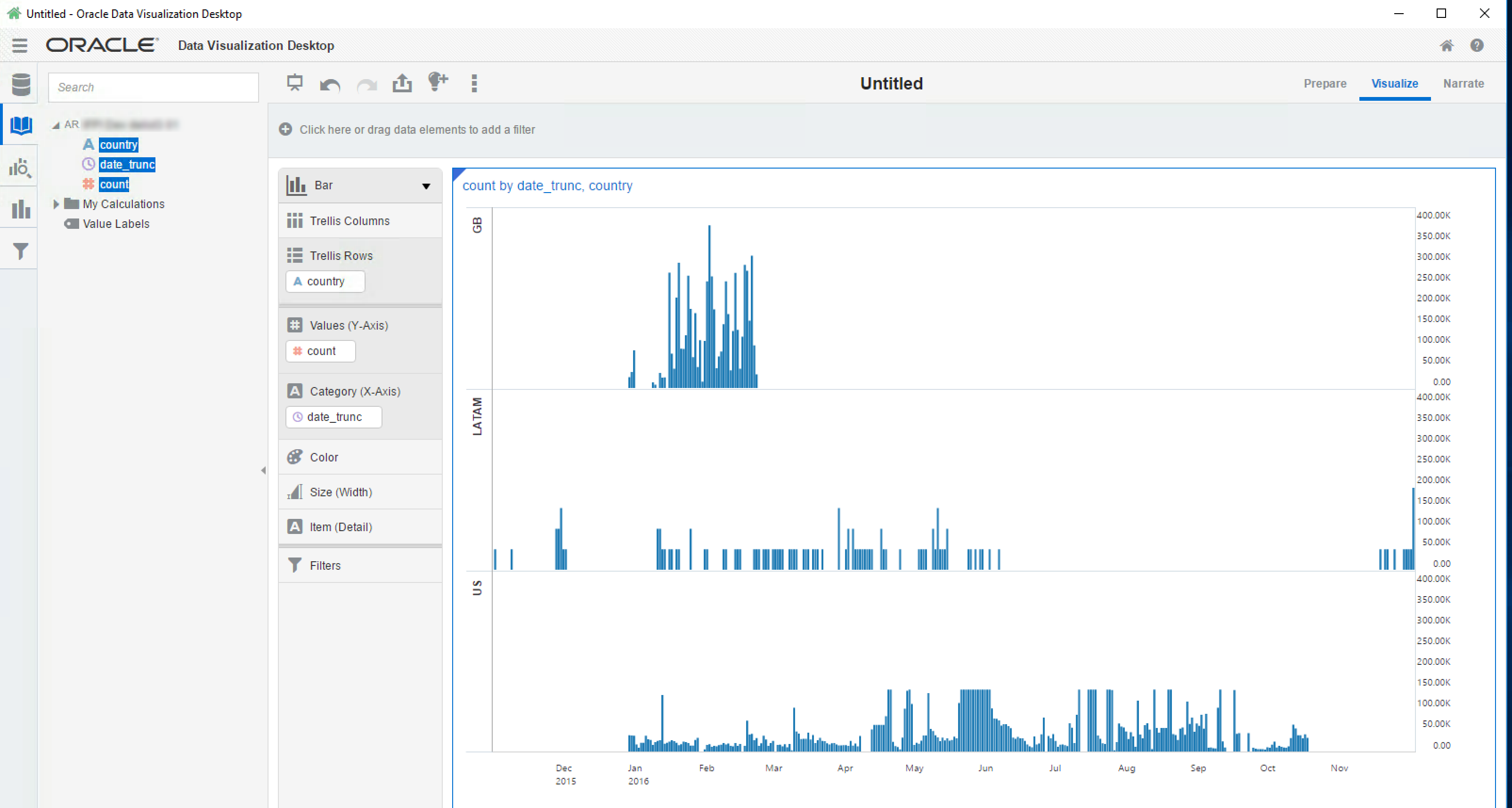
Oracle's Data Visualization Desktop was used as the front end for querying.
Benefits
Cost Benefits
- By moving ETL processing to Hadoop-based platform, we free up capacity (and potentially licensing costs) on the existing commerical RDBMS (Oracle) where the processing currently takes place
- Costs are further reduced by the 'elastic' provisioning and cost model of the cloud service. You only pay for the size of the cluster necessary for your workload, for the duration that it took to execute.
Technology Benefits
In this solution we have taken advantage of the decoupling of storage from compute. This is a significant advantage that cloud technology brings.
- Amazon S3 provides the durable data store for our data (whether CSV, Parquet, or any other data format). With S3 you simply pay for the storage that you use. S3 can be accessed by dozens of client libraries as well as HDFS-compatible APIs. Data in S3 is completely compute-target agnostic. Contrast this to data sat in your proprietory RDBMS database, and if you want to process or analyse this in another system.
- In this instance we wanted to enrich the data, and proved Spark as an appropriate tool to do so. Running on Elastic Map Reduce we could provision this automagically, run our processing, and have the EMR cluster terminate itself once complete. The compute part of the equation is entirely isolated, and can be switched in and our of the architecture as required.
Moving existing workloads to the cloud is not just a case of provisioning servers running in someone else's data centre to perform the same work as before. To truly benefit (dare I say, leverage) from the new possibilities, it makes sense to re-architect how you store your data and perform processing on it.
As well as the benefit of cloud technology, we can see that we don't even need an RDBMS for much of this enrichment and transformation work. Redshift has proved to be useful for interactive analysis of the data, but the processing of the data that would typically get done within an RDBMS (with associated license costs) can instead be done on technology such as Spark.
Broader Observations
The world of data and analytics is changing, and there are some interesting points that this project raised, which I discuss below.
Cloud
The client for whom we carried out this work are already cloud 'converts', running their entire operation on AWS already. They're not alone in recognising the benefits of Cloud, and it's going to be interesting to see the rate at which adoption continues to occur elsewhere, particularly in the Oracle market as they ramp up their offerings.
Cloud Overview
The Cloud is of course a big deal nowadays, whether in the breathless excitement of marketing talk, or the more gradual realisation amongst more technical folk that The Cloud brings some serious benefits. There are three broad flavours of Cloud - Infrastructure, Platform, and Software (IaaS, PaaS, SaaS respectively):
-
At the lowest level, you basically rent access to tin (hardware). Infrastructure-as-a-service (IaaS) can include simply running virtual machines on someone else's hardware, but it's more clever than that. You get the ability to provision storage separately from compute, and all with virtualised networking too. Thus you store your data, but don't pay for the processing until you want to. This is a very long way from working out how big a server to order for installation in your data centre (or indeed, a VM to provision in the cloud) - how many CPUs, how much RAM, how big the hard disks should be - and worrying about under- or over-provisioning it.
With IaaS the components can be decoupled, and scaled elastically as required. You pay for what you use.
The additional benefit of IaaS is that someone else manages the actual hardware; machine outages, disk failures, and so on, are all someone else's concern.
-
IaaS can sometimes still be a lot of work; after all, you still have the manage the servers, or architect and manage the decoupled components such as storage and compute. The next 'aaS' up in Platform as a Service (PaaS). Here, the "platform" is provided and managed for you.
A clear example of PaaS is the Hadoop platform. You can run a Hadoop cluster yourself, whether on Oracle's Big Data Appliance (BDA), or maybe on your own hardware (or indeed, on IaaS in the cloud) but with a distribution such as Cloudera's CDH. Point being, you still have to manage it, to tune your Hadoop parameters, and so on. Hadoop as a platform in the cloud (i.e. PaaS) is offered by many companies, including the big vendors, such as Oracle (Big Data Cloud Service), Microsoft (HDInsight), Google (Dataproc) -- and then the daddy of them all, Amazon with it's Elastic Map Reduce (EMR) platform
Another example of PaaS is Oracle's BI Cloud Service (BICS), in which you build and run your own RPD and reports, but Oracle look after the actual server processes.
-
Software as a Service (SaaS) is where everything is provisioned and managed for you. Whereas on PaaS you still write the code that's to be run (whether a Spark routine on Hadoop, or BI metadata model on BICS), on SaaS someone has already done that too. You just provide the inputs, which obviously depend on the purpose of the SaaS. Something like GMail is a good example of SaaS. You're not having to write the web-based email, you're not having to provision the servers on which to run that - you simply utilise the software.
Cloud's Benefit to Analytics
Cloud brings benefits - but also greater subtleties to our solutions. Instead of simply provisioning one or more servers on which to hold our data and process it, we start to unpick this into separate components. In the context of this study, we have:
- Data at rest, on S3. This is storage paid for simply based on how much you use. Importantly, you don't have to have a server (or in more abstract terms, 'compute') running. It's roughly analogous to network mounted storage. You can access S3 externally to AWS, such as your laptop or a server in your data centre. You can also access it, obviously, from within the AWS ecosystem. You can even use S3 to serve up files just as a web server would.
- Compute, on EMR. How often do you need to carry out transformations and processing on your data? Not continuously? Then why pay for a server to sit idle the rest of the time? What about the size of the server that it does run on - how many CPUs do you need? How many nodes in your cluster? EMR solves both these problems, by enabling you to provision a Hadoop cluster of any size and spec, on demand - and optionally, terminate itself once it's completed its work so that you only pay for the compute time necessary.
- Having a bunch of data sat around isn't going to bring any value to the business, without Analytics and a way of presenting that to the user. This could be done either through loading the data into a traditional RDBMS such as Oracle, or Redshift, and analysing it there - or potentially through one of the new generation of "SQL on Hadoop" engines, such as Impala or Presto. There's also Athena which is a SQL interface directly to data in S3 - you don't even need to be running a Hadoop cluster to use this.
Innovation vs Execution (or, just because you can, doesn't mean you should)
The code written during this exercise could, with a bit of tidying up, be run in Production. As in, it does the job that it was built to do. We could even expand it to audit row counts in and out, report duff data, send notifications when complete. What about the next processing requirement that comes in? More bespoke code? And more? At some point we'd probably end up refactoring a whole bunch of it into some kind of framework. Into that framework we'd obviously want good things like handling SCDs, data lineage, and more. Welcome to re-inventing the in-house ETL wheel. Whether Spark jobs nowadays, PL/SQL ten years ago, or COBOL routines a decade before that - doing data processing at a wider scale soon becomes a challenge. Even with the best coders (or 'engineers' as they're now called) in the world, you're going to end up with a bespoke platform that's relient on inhouse skills to support and maintain. That presumes of course that you can find the relevant skills in the market to write all the processing and transformations that you need - and support them, of course. As you aquire new staff, they'll need to be trained on your code base - and suddenly the "free" technology platform isn't appearing so cheap.
Before you shoot me down for a hyperbolic strawman argument, there is an important dichotomy to draw here, between innovation and execution. Applicable to the world of big data in general, it is a useful concept spelt out in the Oracle Information Management & Big Data Reference Architecture. For data to provide value, it doesn't have to land straight away into the world of formalised development processes, Production environments, and so on. A lot of the time you will want to 'poke around' with it, to explore it -- to innovate. Of the technology base out there, you may not know which tool, or library, is going to yield the best results. This is where the "discovery lab" comes in, and where the type of hand-cranked Spark coding that I've demonstrated sits:
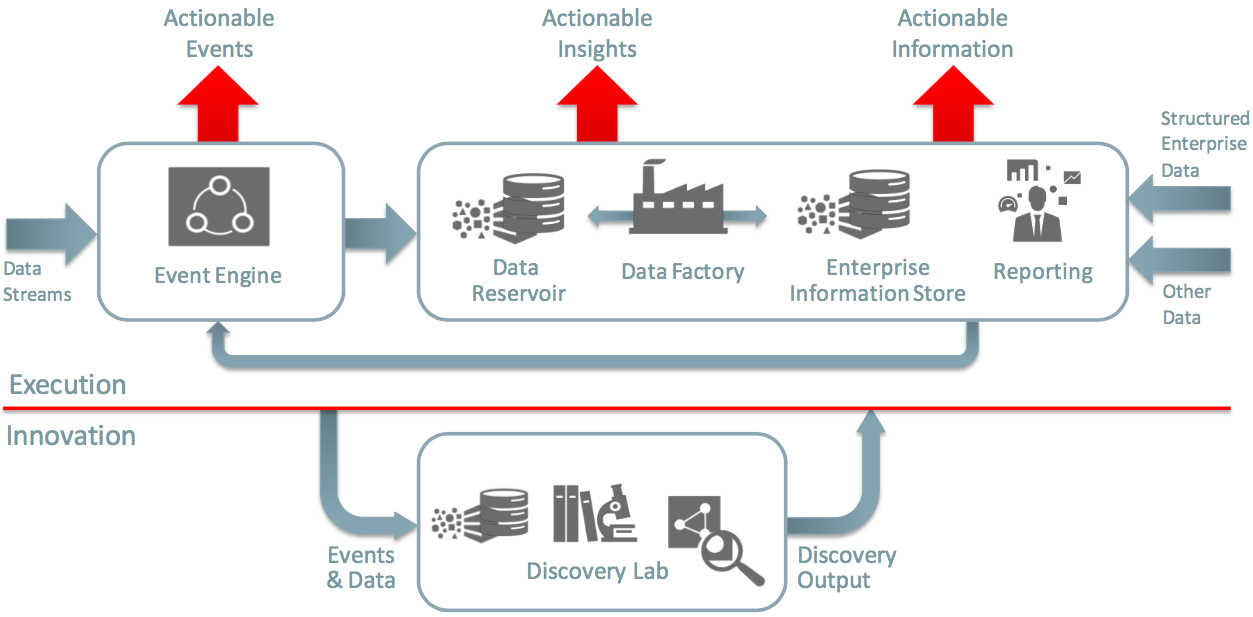
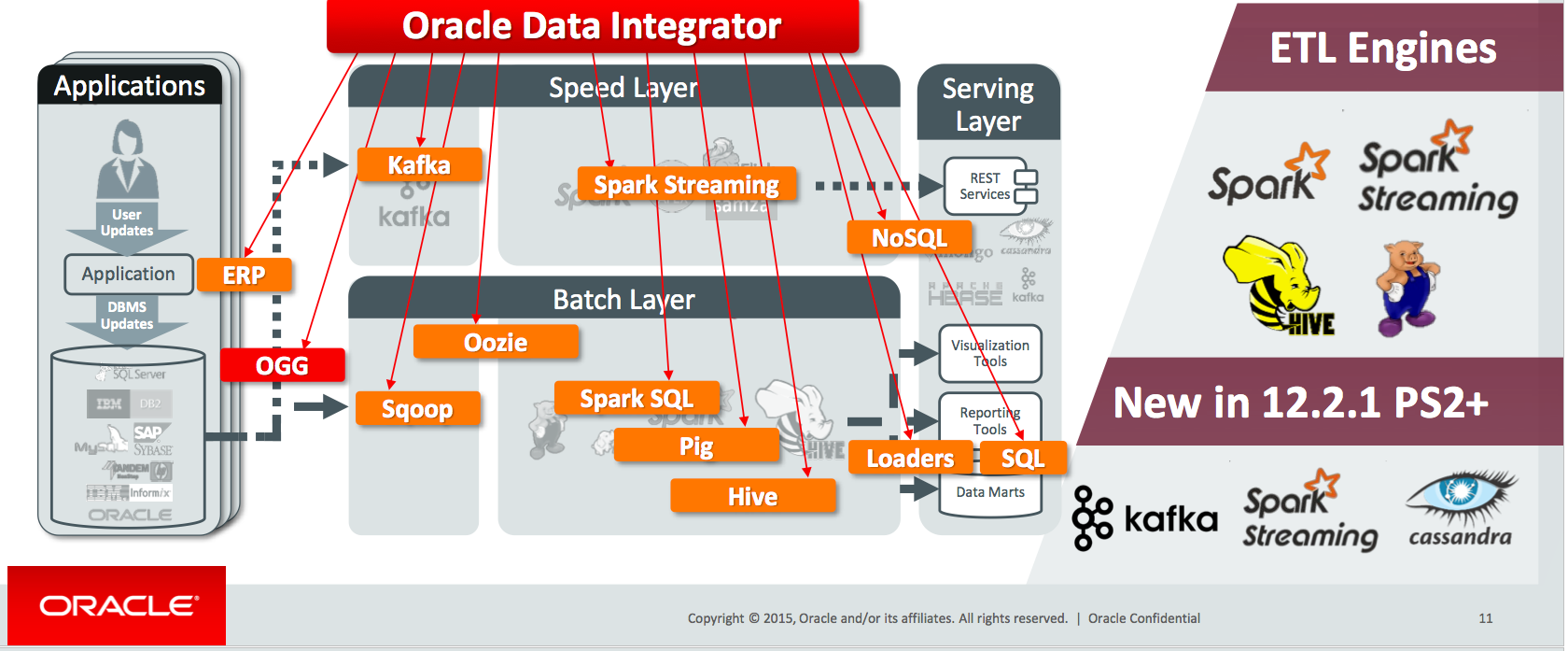
Sometimes, work done in innovation is complete once it's done. As in, it has answered the required business question, and provided its value. But a lot of the time though it will simply establish and prove the process that is to be applied to the data, that then needs taking through to the execution layer. This is often called, in an abuse of the English language, "productionisation" or "industrialisation". This is where the questions of code maintenance and scalability need to be seriously considered. And this is where you need a scalable and maintainable approach to the design, management, and orchestration of your data processing - which is exactly what a tool like Oracle Data Integrator (ODI) provides.
ODI is the premier DI tool on the market, with good support for "big data" technologies, including the ability to generate Spark code to perform transformation. It can be deployed to run on Amazon's EMR, as illustrated here, as well as Oracle's Cloud platform. As can be seen from this presentation from Oracle Open World in September 2016, there's additional capabilities coming including around Kafka, Spark Streaming, and Cassandra.
Another route to examine, alongside ODI, is the ecosystem within AWS itself around code execution and orchestration with tools such as Lambda, Data Pipeline, and Simple Workflow Service. There's also AWS Glue, which like Athena was announced at re:Invent 2016. This promises three key things of crucial importance here:
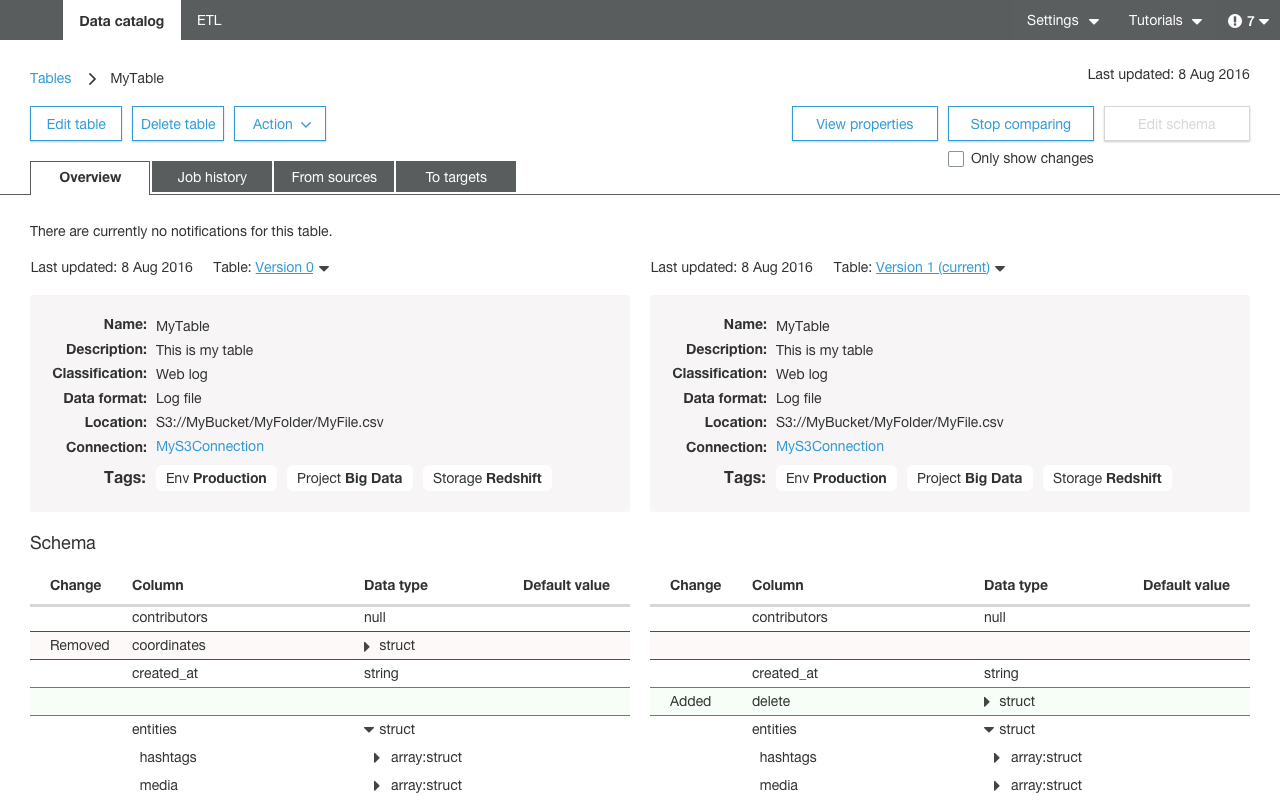
- A Data Catalog, populated automatically, and not only just supporting multiple formats and sources, but including automatic classification (e.g. "Web Log") of the data itself.
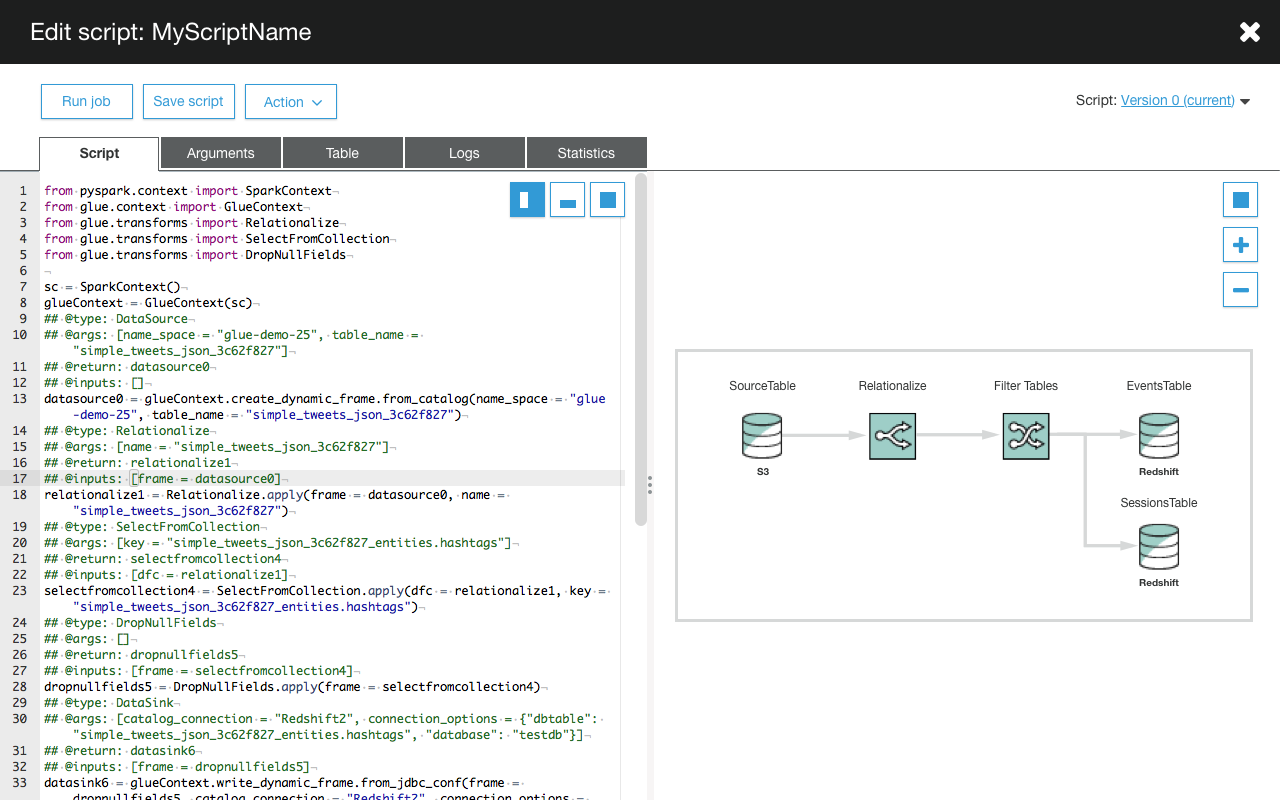
- Automatic generation of ETL code. From the release announcement notes this looks like it is pySpark-based code. So the code that I put together for this exercise here, manually (and at times, painfully), could be automagically generated based on source/target and operators required. The announcement notes also specifically mention the inclusion of standard ETL processes such as handling bad data
- Orchestration and management of ETL jobs. One of my main objections above to taking 'proof of concept' pySpark code and trying to use it in a Production scenario is that you end up with a spaghetti of scripts, which are a nightmare to maintain and support. If Glue lives up to its promises, we'd pretty much get the best of all worlds - a flexible yet robust platform.
{kind=link}
{kind=link}
{kind=link}
Hadoop Ecosystems
A single vendor for your IT platform gives you "one throat to choke" when it comes to support, which is usually a good thing. But if that vendor's platform is closed and proprietary it makes leaving it, or even just making use of alternative tools with it, difficult. One of the evangelical claims made about the new world of open source software is that the proliferation of open standards would spell an end to vendor lockin. I was interested to see during the course of this exercise a few examples where the big vendors subtly pushed you towards their own tool of choice, or away from an alternative.
For example, Amazon EMR makes available Presto as part of the default build, but to run the latest version of Impala you'd have to install it yourself. Whilst it is possible to install it yourself, of course, this added friction makes it less likely that people will. This friction increases when we consider that the software usually needs installing - and configuring - across multiple the nodes of the Hadoop cluster. Given an open field of tools all purporting to do the same or similar things, any impedance to using one over the other will count. The same argument could be made for the CDH distribution, in which Impala is front and center, and deploying Presto or Drill would be a manual exercise. Again, yes, installing it may be relatively trivial - but manual download and deployment across a cluster is never going to win out over a one-click deploying from a centralised management console.
This is a long way from any kind of vendor lockin, but it is worth bearing in mind that walls, albeit thin ones, are being built around these various gardens in the Hadoop ecosystem.
Summary
I hope you've found this series of article useful. You can find a list of them below. In the meantime, please do get in touch if you'd like to find out more about how Rittman Mead can help you on your data and analytics journey!
- ETL Offload with Spark and Amazon EMR - Part 1 - Introduction
- ETL Offload with Spark and Amazon EMR - Part 2 - Code development
- ETL Offload with Spark and Amazon EMR - Part 3 - Running pySpark on EMR
- ETL Offload with Spark and Amazon EMR - Part 4 - Analysing the data
- ETL Offload with Spark and Amazon EMR - Part 5 - Summary
You can listen to a discussion of this project, along with other topics including OBIEE, in an episode of the Drill to Detail podcast here.