Rittman Mead at BIWA Summit 2017

I'm excited to be attending my first ever BIWA Summit next week (which will take me to Oracle HQ at Redwood Shores for the first time too!). This three day conference is one of the major dates in the conference calendar for all Oracle Analytics folk, and I'm proud to have opportunity to present three papers:
-
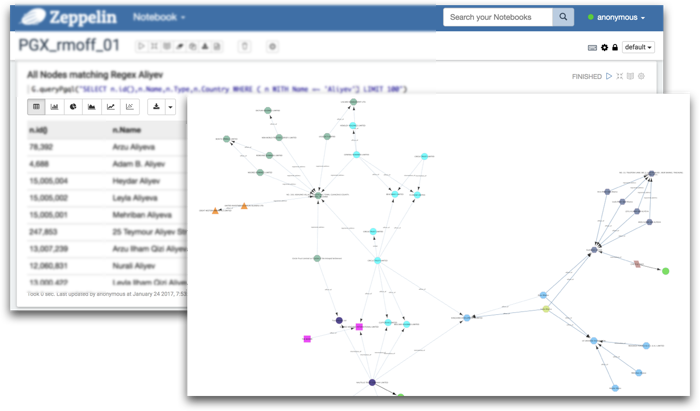
Analysing the Panama Papers with Oracle Big Data Spatial and Graph
31st January, Room 103, 15:45
Based on an article I wrote recently, I'll be talking about how to use property graph analysis through Oracle's Big Data Spatial and Graph tool to examine and analyse the relationships in the Panama Papers dataset. Complex relationships that would be all but impossible to query in relational SQL can be uncovered using built in algorithms as well as with Property Graph Query Language (PGQL). I'm using my new favourite tool, interactive notebooks, to demonstrate PGQL as well as the PGX interface.
-
Kafka's Role in Implementing Oracle's Big Data Reference Architecture on the Big Data Appliance
1st February, Room 102, 14:20
Apache Kafka is rapidly becoming accepted as a de-facto means of building a data pipeline through a business, ensuring availability of data to and from all systems that need it. In this presentation I go in to the detail of what Apache Kafka is, the problems that it solves - and then put this in context of the Oracle Information Management and Big Data Reference Architecture.
-
(Still) No Silver Bullets : OBIEE 12c Performance in the Real World
2nd February, Room 203, 13:30
One of my favourite presentations to deliver, this dives into what you should - and shouldn't - do when building an OBIEE system. It explains how to troubleshoot performance issues methodically - and not a best practice in sight!
There's a full listing of all sessions here, with a PDF to download here.
You can follow the conference proceedings on twitter with the hashtag #BIWASummit, and I'll be tweeting about it to as @rmoff. The presentations that I'm delivering will be available to download on speakerdeck.