Property Graph in Oracle 12.2

The latest release of Oracle (12.2) includes support for Property Graph, previously available only as part of the Big Data Spatial and Graph tool. Unlike the latter, in which data is held in a NoSQL store (Oracle NoSQL, or Apache HBase), it is now possible to use the Oracle Database itself for holding graph definitions and analysing them.
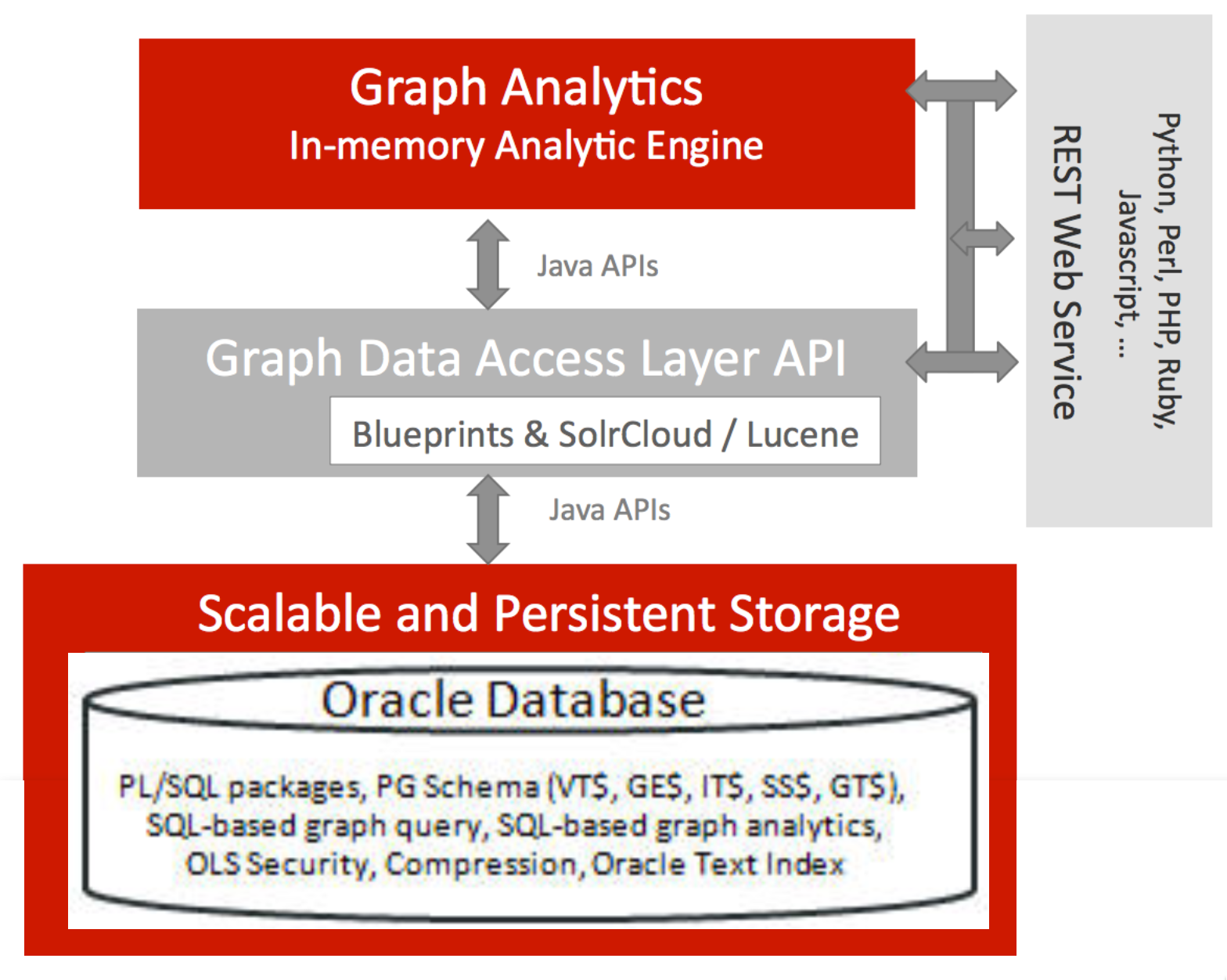
Here we'll see this in action, using the same dataset as I've previously used - the "Panama Papers".
My starting point is the Oracle Developer Day VM, which at under 8GB is a tenth of the size of the beast that is the BigDataLite VM. BDL is great for exploring the vast Big Data ecosystem, both within and external to the Oracle world. However the Developer Day VM serves our needs perfectly here, having been recently updated for the 12.2 release of Oracle. You can also use DB 12.2 in Oracle Cloud, as well as the Docker image.
Prepare Database for Property Graph
The steps below are based on Zhe Wu's blog "Graph Database Says Hello from the Cloud (Part III)", modified slightly for the differing SIDs etc on Developer Day VM.
First, set the Oracle environment by running from a bash prompt
. oraenv
When prompted for SID enter orcl12c:
[oracle@vbgeneric ~]$ . oraenv
ORACLE_SID = [oracle] ? orcl12c
ORACLE_BASE environment variable is not being set since this
information is not available for the current user ID oracle.
You can set ORACLE_BASE manually if it is required.
Resetting ORACLE_BASE to its previous value or ORACLE_HOME
The Oracle base has been set to /u01/app/oracle/product/12.2/db_1
[oracle@vbgeneric ~]$
Now launch SQL*Plus:
sqlplus sys/oracle@localhost:1521/orcl12c as sysdba
and from the SQL*Plus prompt create a tablespace in which the Property Graph data will be stored:
alter session set container=orcl;
create bigfile tablespace pgts
datafile '?/dbs/pgts.dat' size 512M reuse autoextend on next 512M maxsize 10G
EXTENT MANAGEMENT LOCAL
segment space management auto;
Now you need to do a bit of work to update the database to hold larger string sizes, following the following steps.
In SQL*Plus:
ALTER SESSION SET CONTAINER=CDB$ROOT;
ALTER SYSTEM SET max_string_size=extended SCOPE=SPFILE;
shutdown immediate;
startup upgrade;
ALTER PLUGGABLE DATABASE ALL OPEN UPGRADE;
EXIT;
Then from the bash shell:
cd $ORACLE_HOME/rdbms/admin
mkdir /u01/utl32k_cdb_pdbs_output
mkdir /u01/utlrp_cdb_pdbs_output
$ORACLE_HOME/perl/bin/perl $ORACLE_HOME/rdbms/admin/catcon.pl -u SYS -d $ORACLE_HOME/rdbms/admin -l '/u01/utl32k_cdb_pdbs_output' -b utl32k_cdb_pdbs_output utl32k.sql
When prompted, enter SYS password (oracle)
After a short time you should get output:
catcon.pl: completed successfully
Now back into SQL*Plus:
sqlplus sys/oracle@localhost:1521/orcl12c as sysdba
and restart the database instances:
shutdown immediate;
startup;
ALTER PLUGGABLE DATABASE ALL OPEN READ WRITE;
exit
Run a second script from the bash shell:
$ORACLE_HOME/perl/bin/perl $ORACLE_HOME/rdbms/admin/catcon.pl -u SYS -d $ORACLE_HOME/rdbms/admin -l '/u01/utlrp_cdb_pdbs_output' -b utlrp_cdb_pdbs_output utlrp.sql
Again, enter SYS password (oracle) when prompted. This step then takes a while (c.15 minutes) to run, so be patient. Eventually it should finish and you'll see:
catcon.pl: completed successfully
Now to validate that the change has worked. Fire up SQL*Plus:
sqlplus sys/oracle@localhost:1521/orcl12c as sysdba
And check the value for max_string, which should be EXTENDED:
alter session set container=orcl;
SQL> show parameters max_string;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
max_string_size string EXTENDED
Load Property Graph data from Oracle Flat File format
Now we can get going with our Property Graph. We're going to use Gremlin, a groovy-based interpretter, for interacting with PG. As of Oracle 12.2, it ships with the product itself. Launch it from bash:
cd $ORACLE_HOME/md/property_graph/dal/groovy
sh gremlin-opg-rdbms.sh
--------------------------------
Mar 08, 2017 8:52:22 AM java.util.prefs.FileSystemPreferences$1 run
INFO: Created user preferences directory.
opg-oracledb>
First off, let's create the Property Graph object in Oracle itself. Under the covers, this will set up the necessary database objects that will store the data.
cfg = GraphConfigBuilder.\
forPropertyGraphRdbms().\
setJdbcUrl("jdbc:oracle:thin:@127.0.0.1:1521/ORCL").\
setUsername("scott").\
setPassword("oracle").\
setName("panama").\
setMaxNumConnections(8).\
build();
opg = OraclePropertyGraph.getInstance(cfg);
You can also do this with the PL/SQL command exec opg_apis.create_pg('panama', 4, 8, 'PGTS');. Either way, the effect is the same; a set of tables created in the owner's schema:
SQL> select table_name from user_tables;
TABLE_NAME
------------------------------------------
PANAMAGE$
PANAMAGT$
PANAMAVT$
PANAMAIT$
PANAMASS$
Now let's load the data. I'm using the Oracle Flat File format here, having converted it from the original CSV format using R. For more details of why and how, see my article here.
From the Gremlin prompt, run:
// opg.clearRepository(); // start from scratch
opgdl=OraclePropertyGraphDataLoader.getInstance();
efile="/home/oracle/panama_edges.ope"
vfile="/home/oracle/panama_nodes.opv"
opgdl.loadData(opg, vfile, efile, 1, 10000, true, null);
This will take a few minutes. Once it's completed you'll get null response, but can verify the data has successfully loaded using the opg.Count* functions:
opg-oracledb> opgdl.loadData(opg, vfile, efile, 1, 10000, true, null);
==>null
opg-oracledb> opg.countEdges()
==>1265690
opg-oracledb> opg.countVertices()
==>838295
We can inspect the data in Oracle itself too. Here I'm using SQLcl, which is available by default on the Developer Day VM. Using the ...VT$ table we can query the number of distinct properties the nodes (verticies) in the graph:
SQL> select distinct k from panamaVT$;
K
----------------------------
Entity incorporation.date
Entity company.type
Entity note
ID
Officer icij.id
Countries
Type
Entity status
Country
Source ID
Country Codes
Entity struck.off.date
Entity address
Name
Entity jurisdiction
Entity jurisdiction.description
Entity dorm.date
17 rows selected.
Inspect the edges:
[oracle@vbgeneric ~]$ sql scott/oracle@localhost:1521/orcl
SQL> select p.* from PANAMAGE$ p where rownum<5;
EID SVID DVID EL K T V VN VT SL VTS VTE FE
---------- ---------- ---------- ---------------- ---- ---- ---- ---- ---- ---- ---- ---- ----
6 6 205862 officer_of
11 11 228601 officer_of
30 36 216748 officer_of
34 39 216487 officer_of
SQL>
You can also natively execute some of the Property Graph algorithms from PL/SQL itself. Here is how to run the PageRank algorithm, which can be used to identify the most significant nodes in a graph, assigning them each a score (the "page rank" value):
set serveroutput on
DECLARE
wt_pr varchar2(2000); -- name of the table to hold PR value of the current iteration
wt_npr varchar2(2000); -- name of the table to hold PR value for the next iteration
wt3 varchar2(2000);
wt4 varchar2(2000);
wt5 varchar2(2000);
n_vertices number;
BEGIN
wt_pr := 'panamaPR';
opg_apis.pr_prep('panamaGE$', wt_pr, wt_npr, wt3, wt4, null);
dbms_output.put_line('Working table names ' || wt_pr
|| ', wt_npr ' || wt_npr || ', wt3 ' || wt3 || ', wt4 '|| wt4);
opg_apis.pr('panamaGE$', 0.85, 10, 0.01, 4, wt_pr, wt_npr, wt3, wt4, 'SYSAUX', null, n_vertices)
;
END;
/
When run this creates a new table with the PageRank score for each vertex in the graph, which can then be queried as any other table:
SQL> select * from panamaPR
2 order by PR desc
3* fetch first 5 rows only;
NODE PR C
---------- ---------- ----------
236724 8851.73652 0
288469 904.227685 0
264051 667.422717 0
285729 562.561604 0
237076 499.739316 0
On its own, this is not so much use; but joined to the vertices table, we can now find out, within our graph, the top ranked vertices:
SQL> select pr.pr, v.k,v.V from panamaPR pr inner join PANAMAVT$ V on pr.NODE = v.vid where v.K = 'Name' order by PR desc fetch first 5 rows only;
PR K V
---------- ---------- ---------------
8851.73652 Name Portcullis TrustNet Chambers P.O. Box 3444 Road Town- Tortola British Virgin Isl
904.227685 Name Unitrust Corporate Services Ltd. John Humphries House- Room 304 4-10 Stockwell Stre
667.422717 Name Company Kit Limited Unit A- 6/F Shun On Comm Bldg. 112-114 Des Voeux Road C.- Hong
562.561604 Name Sealight Incorporations Limited Room 1201- Connaught Commercial Building 185 Wanc
499.739316 Name David Chong & Co. Office B1- 7/F. Loyong Court 212-220 Lockhart Road Wanchai Hong K
SQL>
Since our vertices in this graph have properties, including "Type", we can also analyse it by that - the following shows the top ranked vertices that are Officers:
SQL> select V.vid, pr.pr from panamaPR pr inner join PANAMAVT$ V on pr.NODE = v.vid where v.K = 'Type' and v.V = 'Officer' order by PR desc fetch first 5 rows only;
VID PR
---------- ----------
12171184 1.99938104
12030645 1.56722346
12169701 1.55754873
12143648 1.46977361
12220783 1.39846834
which we can then put in a subquery to show the details for these nodes:
with OfficerPR as
(select V.vid, pr.pr
from panamaPR pr
inner join PANAMAVT$ V
on pr.NODE = v.vid
where v.K = 'Type' and v.V = 'Officer'
order by PR desc
fetch first 5 rows only)
select pr2.pr,v2.k,v2.v
from OfficerPR pr2
inner join panamaVT$ v2
on pr2.vid = v2.vid
where v2.k in ('Name','Countries');
PR K V
---------- ---------- -----------------------
1.99938104 Countries Guernsey
1.99938104 Name Cannon Asset Management Limited re G006
1.56722346 Countries Gibraltar
1.56722346 Name NORTH ATLANTIC TRUST COMPANY LTD. AS TRUSTEE THE DAWN TRUST
1.55754873 Countries Guernsey
1.55754873 Name Cannon Asset Management Limited re J006
1.46977361 Countries Portugal
1.46977361 Name B-49-MARQUIS-CONSULTADORIA E SERVICOS (SOCIEDADE UNIPESSOAL) LDA
1.39846834 Countries Cyprus
1.39846834 Name SCIVIAS TRUST MANAGEMENT LTD
10 rows selected.
But here we get into the limitations of SQL - already this is starting to look like a bit of a complex query to maintain. This is where PGQL comes in, as it enables to express the above request much more eloquently. The key thing with PGQL is that it understands the concept of a 'node', which removes the need for the convoluted sub-select that I had to do above to first identify the top-ranked nodes that had a given property (Type = Officer), and then for those identified nodes show information about them (Name and Countries). The above SQL could be expressed in PGQL simply as:
SELECT n.pr, n.name, n.countries
WHERE (n WITH Type =~ 'Officer')
ORDER BY n.pr limit 5
At the moment Property Graph in the Oracle DB doesn't support PGQL - but I'd expect to see it in the future.
Jupyter Notebooks
As well as working with the Property Graph in SQL and Gremlin, we can use the Python API. This is shipped with Oracle 12.2. I'd strongly recommend using it through a Notebook, and this provides an excellent environment in which to prototype code and explore the results. Here I'll use Jupyter, but Apache Zeppelin is also very good.
First let's install Anaconda Python, which includes Jupyter Notebooks:
wget https://repo.continuum.io/archive/Anaconda2-4.3.0-Linux-x86_64.sh
bash Anaconda2-4.3.0-Linux-x86_64.sh
In the install options I use the default path (/home/oracle) as the location, and keep the default (no)
Launch Jupyter, telling it to listen on any NIC (not just localhost). If you installed anaconda in a different path from the default you'll need to amend the /home/oracle/ bit of the path.
/home/oracle/anaconda2/bin/jupyter notebook --ip 0.0.0.0
If you ran the above command from the terminal window within the VM, you'll get Firefox pop up with the following:
If you're using the VM headless you'll now want to fire up your own web browser and go to http://<ip>:8888 use the token given in the startup log of Jupyter to login.
Either way, you should now have a functioning Jupyter notebook environment.
Now let's install the Property Graph support into the Python & Jupyter environment. First, make sure you've got the right Python set, by confirming with which it's the anaconda version you installed, and when you run python you see Anaconda in the version details:
[oracle@vbgeneric ~]$ export PATH=/home/oracle/anaconda2/bin:$PATH
[oracle@vbgeneric ~]$ which python
~/anaconda2/bin/python
[oracle@vbgeneric ~]$ python -V
Python 2.7.13 :: Anaconda 4.3.0 (64-bit)
[oracle@vbgeneric ~]$
Then run the following
cd $ORACLE_HOME/md/property_graph/pyopg
touch README
python ./setup.py install
without the README being created, the install fails with IOError: [Errno 2] No such file or directory: './README'
You need to be connected to the internet for this as it downloads dependencies as needed. After a few screenfuls of warnings that appear OK to ignore, the installation should be succesful:
[...]
creating /u01/userhome/oracle/anaconda2/lib/python2.7/site-packages/JPype1-0.6.2-py2.7-linux-x86_64.egg
Extracting JPype1-0.6.2-py2.7-linux-x86_64.egg to /u01/userhome/oracle/anaconda2/lib/python2.7/site-packages
Adding JPype1 0.6.2 to easy-install.pth file
Installed /u01/userhome/oracle/anaconda2/lib/python2.7/site-packages/JPype1-0.6.2-py2.7-linux-x86_64.egg
Finished processing dependencies for pyopg==1.0
Now you can use the Python interface to property graph (pyopg) from within Jupyter, as seen below. I've put the notebook on gist.github.com meaning that you can download it from there and run it yourself in Jupyter.