Exploring the Rittman Mead Insights Lab

What is our Insights Lab?
The Insights Lab offers on-demand access to an experienced data science team, using a mature methodology to deliver one-off analyses and production-ready predictive models.
Our Data Science team includes physicists, mathematicians, industry veterans and data engineers ready to help you take analytics to the next level while providing expert guidance in the process.
Why use it?
Data is cheaper to collect and easier to store than ever before. But collecting the data is not synonymous with getting value from it. Businesses need to do more with the same budget and are starting to look into machine learning to achieve this.
These processes can take off some of the workload, freeing up people's time to work on more demanding tasks. However, many businesses don't know how to get started down this route, or even if they have the data necessary for a predictive model.
R
Our Data science team primarily work using the R programming language. R is an open source language which is supported by a large community.
The functionality of R is extended by many community written packages which implement a wide variety of statistical and graphical techniques, including linear and nonlinear modeling, statistical tests, time-series analysis, classification, clustering as well as packages for data access, cleaning, tidying, analysing and building reports.
All of these packages can be found on the Comprehensive R Archive Network (CRAN), making it easy to get access to new techniques or functionalities without needing to develop them yourself (all the community written packages work together).
R is not only free and extendable, it works well with other technologies and makes it an ideal choice for businesses who want to start looking into advanced analytics. Python is an obvious alternative, and several of our data scientists prefer it. We're happy to use whatever our client's teams are most familiar with.
Experienced programmers will find R syntax easy enough to pick up and will soon be able to implement some form of machine learning. However, for a detailed introduction to R and a closer look at implementing some of the concepts mentioned below we do offer a training course in R.
Our Methodology
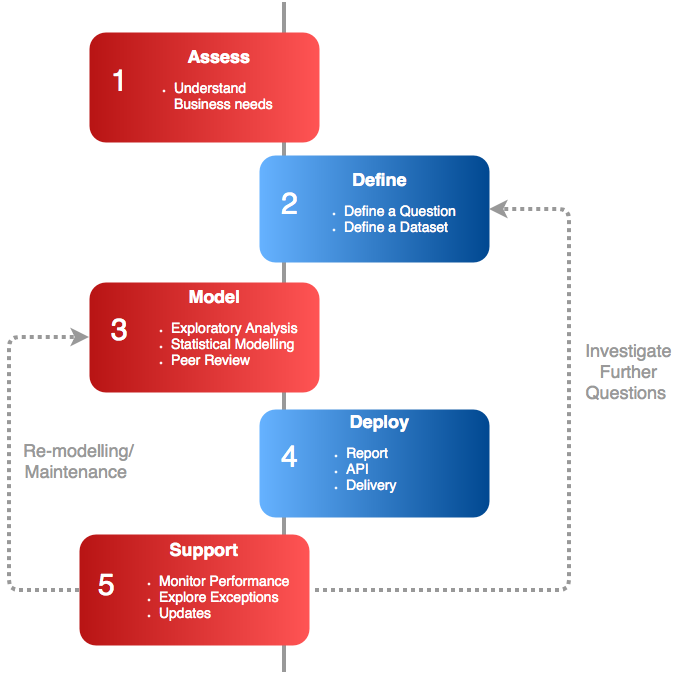
Define
Define a Question
Analytics, for all intents and purposes, is a scientific discipline and as such requires a hypothesis to test. That means having a specific question to answer using the data.
Starting this process without a question can lead to biases in the produced result. This is called data dredging - testing huge numbers of hypotheses about a single data set until the desired outcome is found. Many other forms of bias can be introduced accidentally; the most commonly occurring will be outlined in a future blog post.
Once a question is defined, it is also important to understand which aspects of the question you are most interested in. Associated, is the level of uncertainty or error that can be tolerated if the result is to be applied in a business context.
Questions can be grouped into a number of types. Some examples will be outlined in a future blog post.
Define a dataset
The data you expect to be relevant to your question needs to be collated. Maybe supplementary data is needed, or can be added from different databases or web scraping.
This data set then needs to be cleaned and tidied. This involves merging and reshaping the data as well as possibly summarising some variables. For example, removing spaces and non-printing characters from text and converting data types.
The data may be in a raw format, there may be errors in the data collection, or corrupt or missing values that need to be managed. These records can either be removed completely or replaced with reasonable default values, determined by which makes the most sense in this specific situation. If records are removed you need to ensure that no selection biases are being introduced.
All the data should be relevant to the question at hand, anything that isn't can be removed. There may also be external drivers for altering the data, such as privacy issues that require data to be anonymised.
Natural language processing could be implemented for text fields. This takes bodies of text in human readable format such as emails, documents and web page content and processes it into a form that is easier to analyse.
Any changes to the dataset need to be recorded and justified.
Model
Exploratory Analysis
Exploratory data analysis involves summarising the data, investigating the structure, detecting outliers / anomalies as well as identifying patterns and trends. It can be considered as an early part of the model production process or as a preparatory step immediately prior. Exploratory analysis is driven by the data scientist, enabling them to fully understand the data set and make educated decisions; for example the best statistical methods to employ when developing a model.
The relationships between different variables can be understood and correlations found. As the data is explored, different hypotheses could be found that may define future projects.
Visualisations are a fundamental aspect of exploring the relationships in large datasets, allowing the identification of structure in the underlying dataset.
This is also a good time to look at the distribution of your dataset with respect to what you want to predict. This often provides an indication of the types of models or sampling techniques that will work well and lead to accurate predictions.
Variables with very few instances (or those with small variance) may not be beneficial, and in some cases could even be detrimental, increasing computation time and noise. Worse still, if these instances represent an outlier, significant (and unwarranted) value may be placed on these leading to bias and skewed results.
Statistical Modelling/Prediction
The data set is split into two sub groups, "Training" and "Test". The training set is used only in developing or "training" a model, ensuring that the data it is tested on (the test set) is unseen. This means the model is tested in a more realistic context and will help to determine whether the model has overfitted to the training set. i.e. is fitting random noise in addition to any meaningful features.
Taking what was learned from the exploratory analysis phase, an initial model can be developed based on an appropriate application of statistical methods and modeling tools. There are many different types of model that can be applied to the data, the best tends to depend on the complexity of your data and the any relationships that were found in the exploratory analysis phase. During training, the models are evaluated in accordance with an appropriate metric, the improvement of which is the "goal" of the development process. The predictions produced from the trained models when run on the test set will determine the accuracy of the model (i.e. how closely its predictions align with the unseen real data).
A particular type of modelling method, "machine learning" can streamline and improve upon this somewhat laborious process by defining models in such a way that they are able to self optimise, "learning" from past iterations to develop a superior version. Broadly, there are two types, supervised and un-supervised. A supervised machine learning model is given some direction from the data scientist as to the types of methods that it should use and what it is expecting. Unsupervised machine learning on the other hand, as the name suggests, involves giving the model less information to start with and letting it decide for its self what to value, and how to approach the problem. This can help to remove bias and reduce the number of assumptions made but will be more computationally intensive, as the model has a broader scope to investigate. Usually supervised machine learning is employed in a case where the problem and data set are reasonably well understood, and unsupervised machine learning where this is not the case.
Complex predictive modelling algorithms perform feature importance and selection internally while constructing models. These models can also report on the variable importance determined during the model preparation process.
Peer Review
This is an important part of any scientific process, and effectively utilities our broad expertise in modelling at Rittman Mead. This enables us to be sure no biases were introduced that could lead to a misleading prediction and that the accuracy of the models is what could be expected if the model was run on new unseen data. Additional expert views can also lead to alternative potential avenues of investigation being identified as part of an expanded or subsequent study.
Deploy
Report
For a scientific investigation to be credible the results must be reproducible. The reports we produce are written in R markdown and contain all the code required to reproduce the results presented. This also means it can be re-run with new data as long as it is of the same format. A clear and concise description of the investigation from start to finish will be provided to ensure that justification and context is given for all decisions and actions.
Delivery
If the result is of the required accuracy we will deploy a model API enabling customers to start utilising it immediately.
There is always a risk however that the data does not contain the required variables to create predictions with sufficient confidence for use. In these cases, and after the exploratory analysis phase there may be other questions that would be beneficial to investigate. This is also a useful result, enabling us to suggest additional data to collect that may allow a more accurate result should the process be repeated later.
Support
Following delivery we are able to provide a number of support services to ensure that maximum value is extracted from the model on an on-going basis. These include:
- Monitoring performance and accuracy against the observed, actual values over a period of time. Should there be discrepancies between these values arise, these can be used to identify the need for alterations to the model.
- Exploring specific exceptions to the model. There may be cases in which the model consistently performs poorly. Instances like these may not have existed in the training set and the model could be re-trained accordingly. If they were in the training set these could be weighted differently to ensure a better accuracy, or could be represented by a separate model.
- Updates to the model to reflect discrepancies identified through monitoring, changes of circumstance, or the availability of new data.
- Many problems are time dependent and so model performance is expected to degrade, requiring retraining on more up to date data.
Summary
In conclusion our Insights lab has a clearly defined and proven process for data science projects that can be adapted to fit a range of problems.
Contact us to learn how Insights Lab can help your organization get the most from its data, and schedule your consultation today.
Contact us at info@rittmanmead.com