Making our way into Dremio
In an analytics system, we typically have an Operational Data Store (ODS) or staging layer; a performance layer or some data marts; and on top, there would be an exploration or reporting tool such as Tableau or Oracle's OBIEE. This architecture can lead to latency in decision making, creating a gap between analysis and action. Data preparation tools like Dremio can address this.
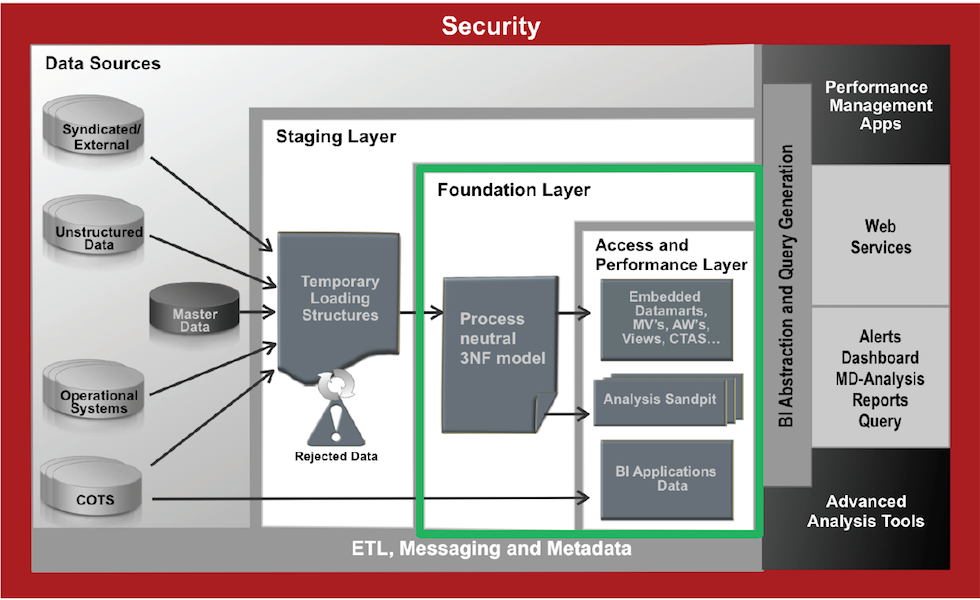
Dremio is a Data-as-a-Service platform allowing users to quickly query data, directly from the source or in any layer, regardless of its size or structure. The product makes use of Apache Arrow, allowing it to virtualise data through an in-memory layer, creating what is called a Data Reflection.
The intent of this post is an introduction to Dremio; it provides a step by step guide on how to query data from Amazon's S3 platform.
I wrote this post using my MacBook Pro, Dremio is supported on MacOS. To install it, I needed to make some configuration changes due to the Java version. The latest version of Dremio uses Java 1.8. If you have a more recent Java version installed, you’ll need to make some adjustments to the Dremio configuration files.
Lets start downloading Dremio and installing it. Dremio can be found for multiple platforms and we can download it from here.
Dremio uses Java 1.8, so if you have an early version please make sure you install java 1.8 and edit /Applications/Dremio.app/Contents/Java/dremio/conf/dremio-env to point to the directory where java 1.8 home is located.

After that you should be able to start Dremio as any other MacOs application and access http://localhost:9047

Configuring S3 Source
Dremio can connect to relational databases (both commercial and open source), NoSQL, Hadoop, cloud storage, ElasticSearch, among others. However the scope of this post is to use a well known NoSQL storage S3 bucket (more details can be found here) and show the query capabilities of Dremio against unstructured data.
For this demo we're using Garmin CSV activity data that can be easily downloaded from Garmin activity page.
Here and example of a CSV Garmin activity. If you don't have a Garmin account you can always replicate the data above.
act,runner,Split,Time,Moving Time,Distance,Elevation Gain,Elev Loss,Avg Pace,Avg Moving Paces,Best Pace,Avg Run Cadence,Max Run Cadence,Avg Stride Length,Avg HR,Max HR,Avg Temperature,Calories
1,NMG,1,00:06:08.258,00:06:06.00,1,36,--,0:06:08 ,0:06:06 ,0:04:13 ,175.390625,193.0,92.89507499768523,--,--,--,65
1,NMG,2,00:10:26.907,00:10:09.00,1,129,--,0:10:26 ,0:10:08 ,0:06:02 ,150.140625,236.0,63.74555754497759,--,--,--,55For user information data we have used the following dataset
runner,dob,name
JM,01-01-1900,Jon Mead
NMG,01-01-1900,Nelio Guimaraes
Add your S3 credentials to access
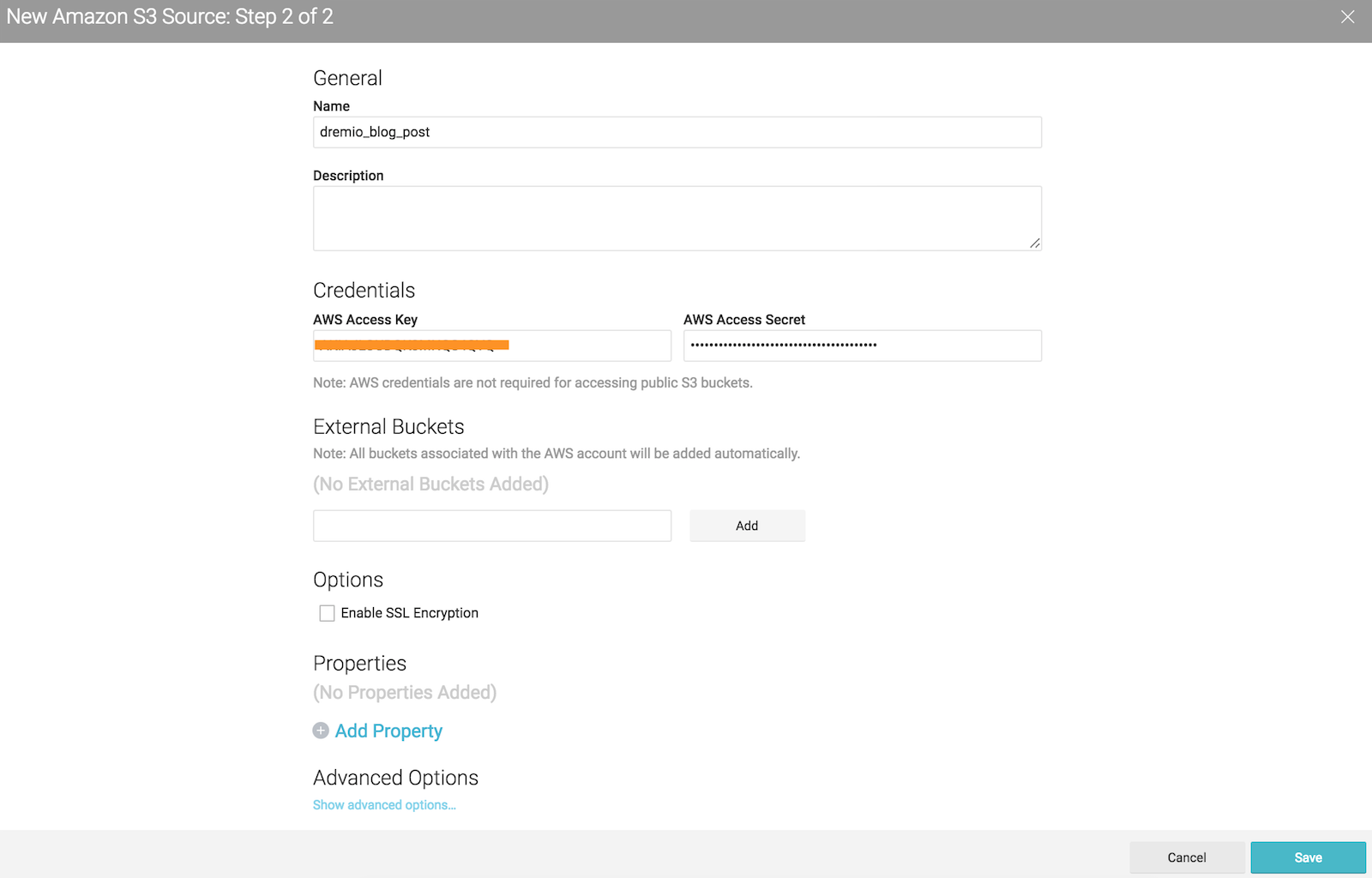
After configuring your S3 account all buckets associated to it, will be prompted under the new source area.
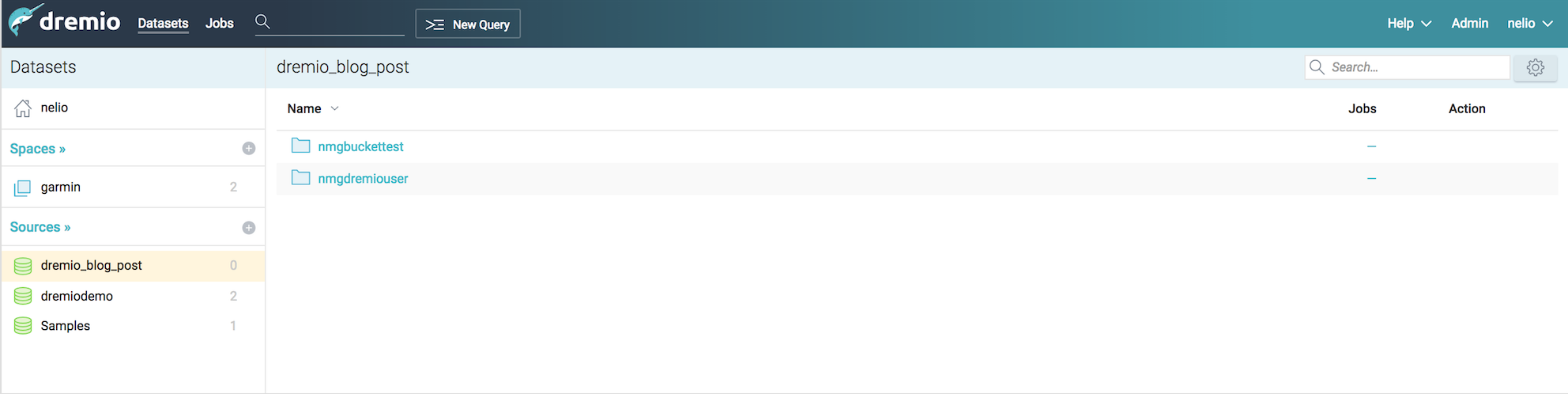
For this post I’ve created two buckets : nmgbuckettest and nmgdremiouser containing data that could be interpreted as a data mart
nmgbuckettest - contains Garmin activity data that could be seen as a fact table in CSV format :
Act,Runner,Split,Time,Moving Time,Distance,Elevation Gain,Elev Loss,Avg Pace,Avg Moving Paces,Best Pace,Avg Run Cadence,Max Run Cadence,Avg Stride Length,Avg HR,Max HR,Avg Temperature,Calories
nmgdremiouser - contains user data that could be seen as a user dimension in a CSV format:
runner,dob,name
Creating datasets
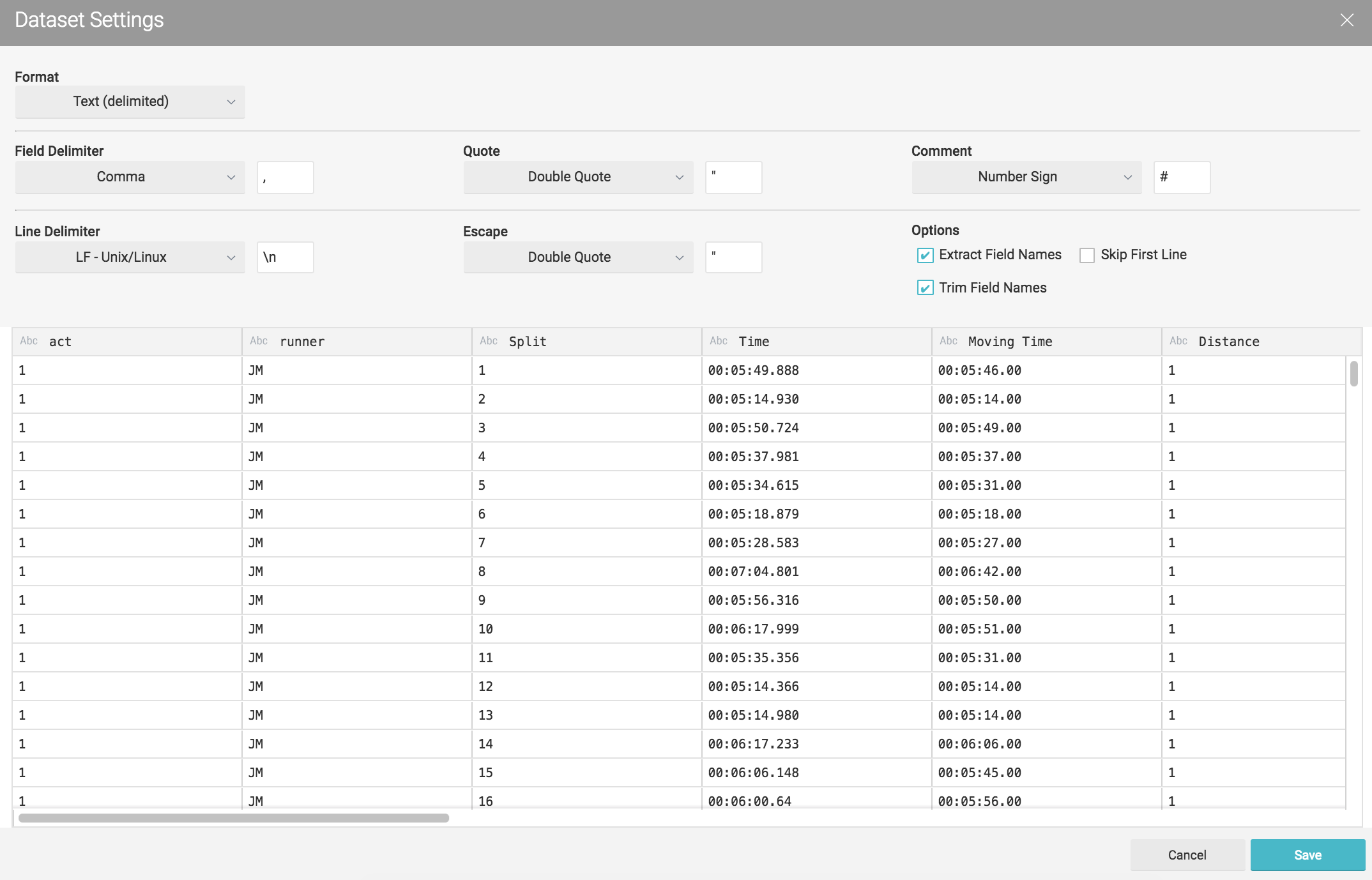
After we add the S3 buckets we need to set up the CSV format. Dremio makes most of the work for us, however we had the need to adjust some fields, for example date formats or map a field as an integer.

By clicking on the gear icon we access the following a configuration panel where we can set the following options. Our CSV's were pretty clean so I've just change the line delimiter for \n and checked the option Extract Field Name
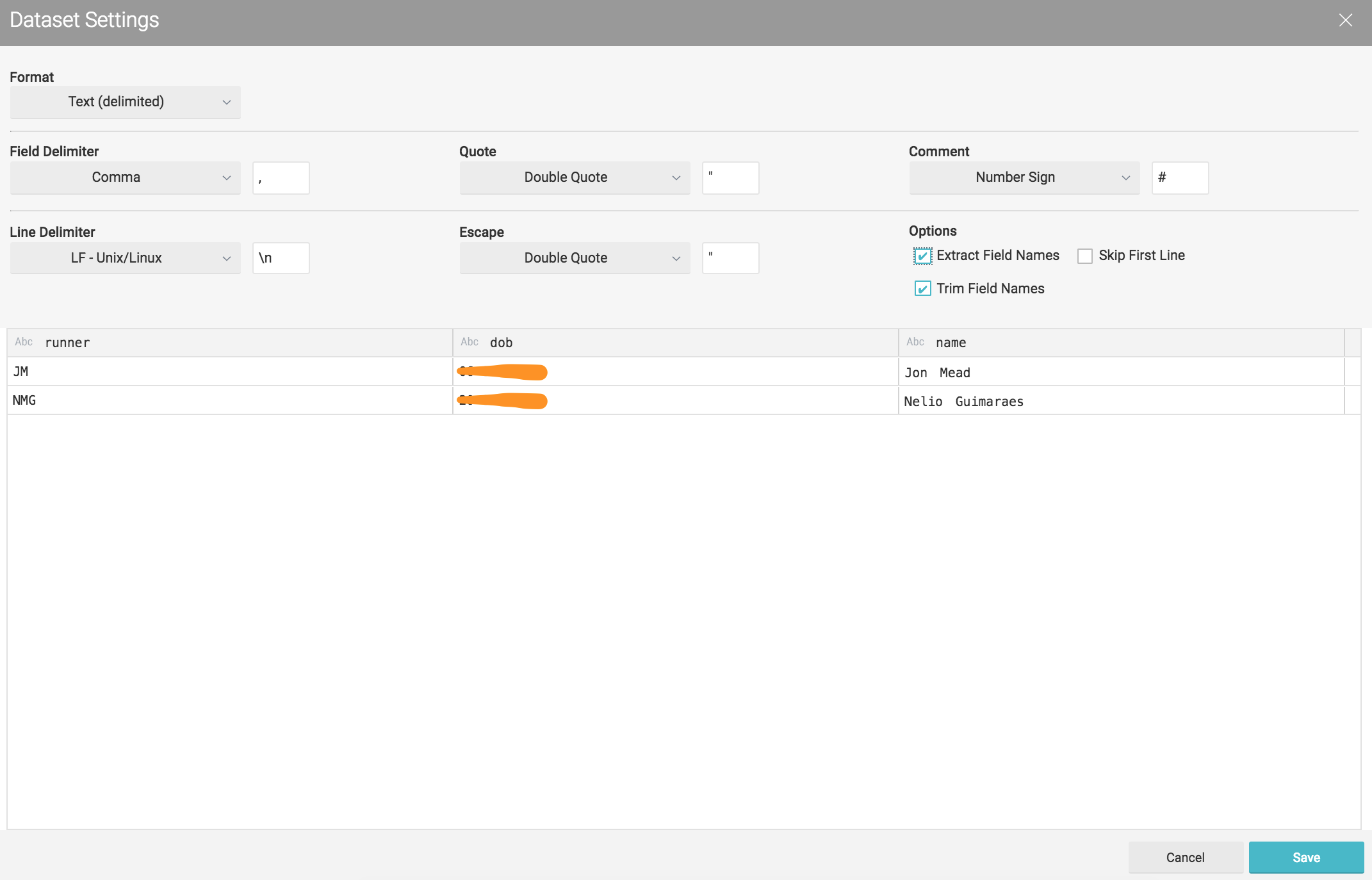
Lets do the same for the second set of CSV's (nmgdremiouser bucket)
Click in saving will drive us to a new panel where we can start performing some queries.

However as mentioned before at this stage we might want to adjust some fields. Right here I'll adapt the dob field from the nmgdremiouser bucket to be in the dd-mm-yyyy format.
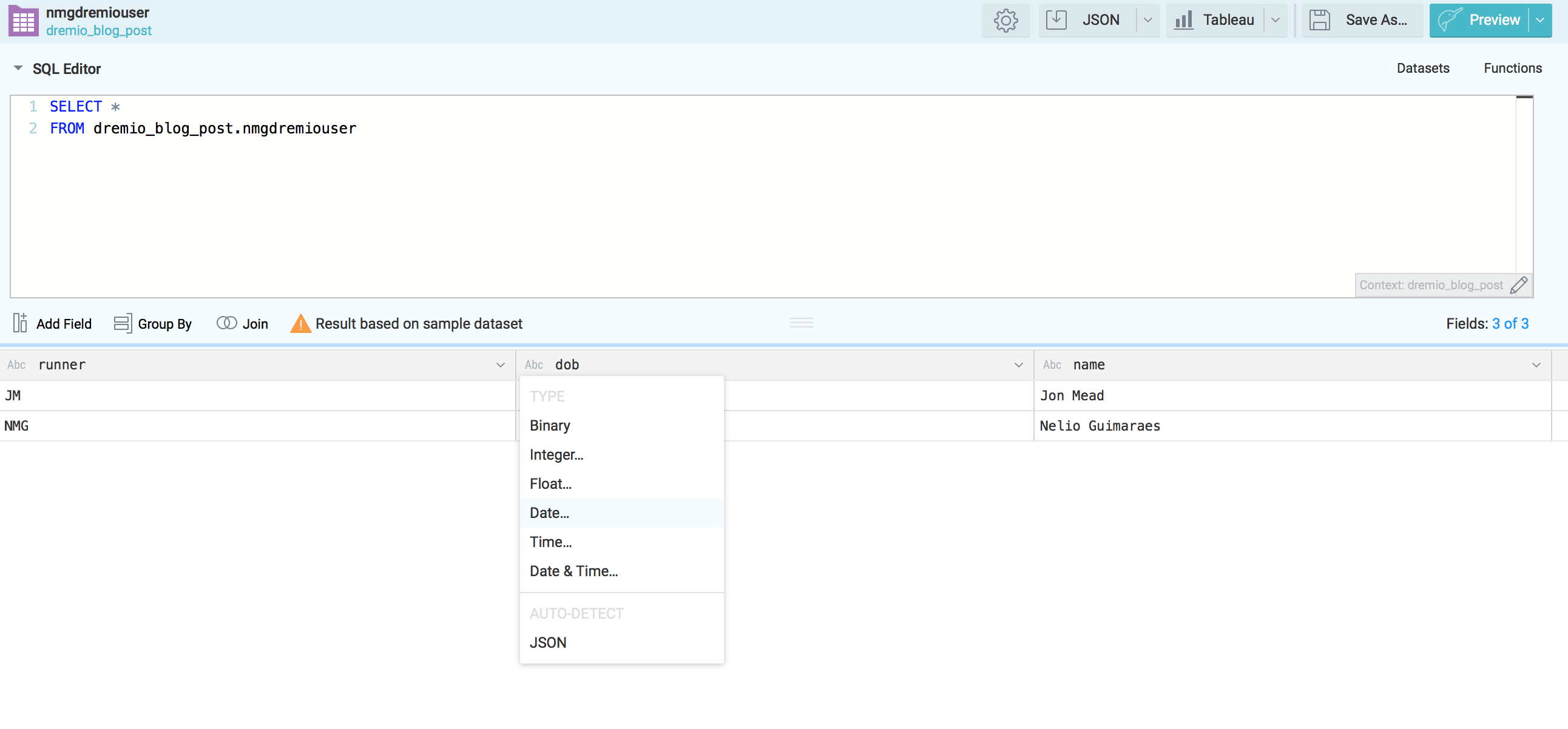
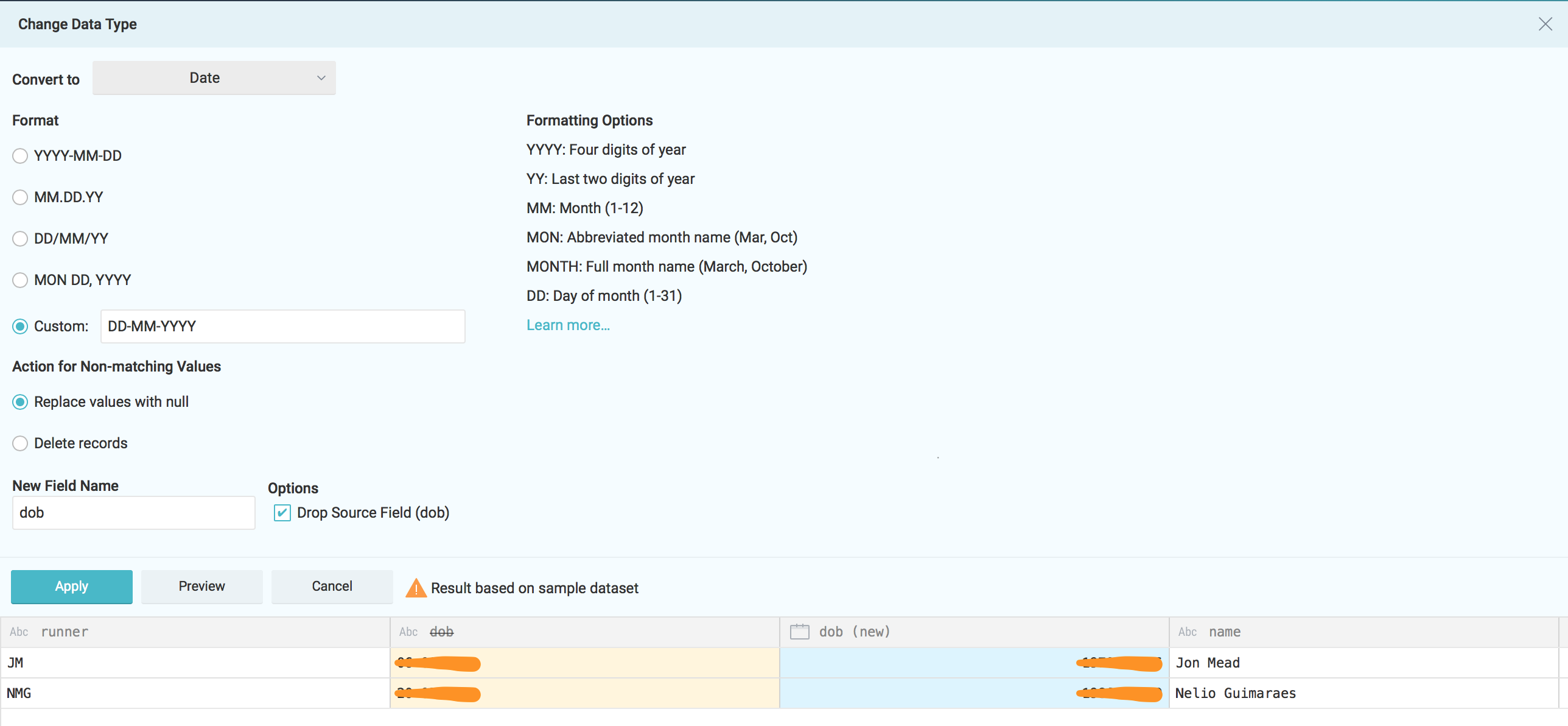
Apply the changes and save the new dataset under the desire space.
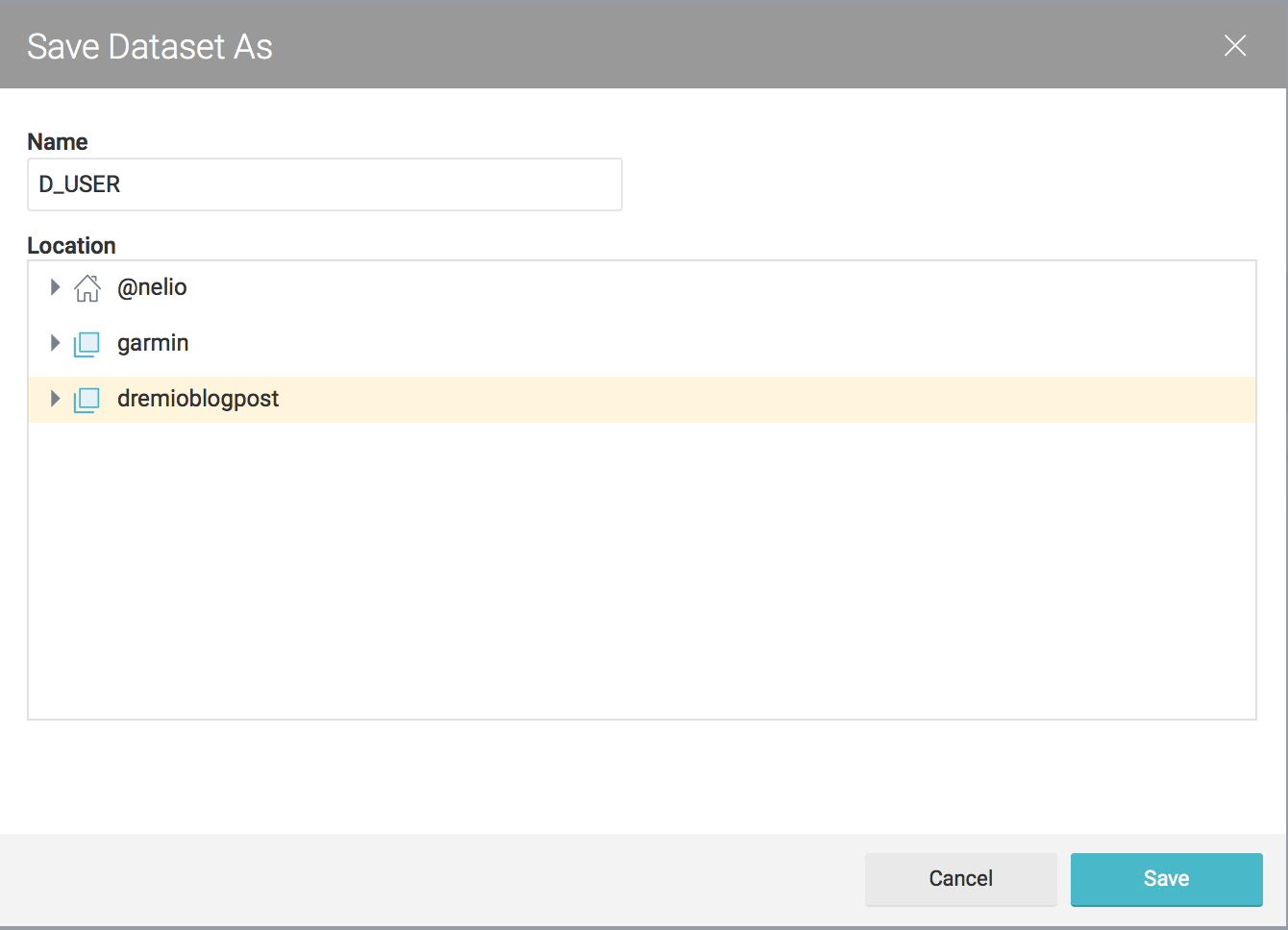
Feel free to do the same for the nmgbuckettest CSV's. As part of my plan to make I'll call D_USER for the dataset coming from nmgdremiouser bucket and F_ACTIVITY for data coming from nmgbuckettest

Querying datasets
Now that we have D_USER and F_ACTIVITY datasets created we can start querying them and do some analysis.
This first analysis will tell us which runner climbs more during his activities:
SELECT round(nested_0.avg_elev_gain) AS avg_elev_gain, round(nested_0.max_elev_gain) AS max_elev_gain, round(nested_0.sum_elev_gain) as sum_elev_gain, join_D_USER.name AS name
FROM (
SELECT avg_elev_gain, max_elev_gain, sum_elev_gain, runner
FROM (
SELECT AVG(to_number("Elevation Gain",'###')) as avg_elev_gain,
MAX(to_number("Elevation Gain",'###')) as max_elev_gain,
SUM(to_number("Elevation Gain",'###')) as sum_elev_gain,
runner
FROM dremioblogpost.F_ACTIVITY
where "Elevation Gain" != '--'
group by runner
) nested_0
) nested_0
INNER JOIN dremioblogpost.D_USER AS join_D_USER ON nested_0.runner = join_D_USER.runner 
To enrich the example lets understand who is the fastest runner with analysis based on the total climbing
SELECT round(nested_0.km_per_hour) AS avg_speed_km_per_hour, nested_0.total_climbing AS total_climbing_in_meters, join_D_USER.name AS name
FROM (
SELECT km_per_hour, total_climbing, runner
FROM (
select avg(cast(3600.0/((cast(substr("Avg Moving Paces",3,2) as integer)*60)+cast(substr("Avg Moving Paces",6,2) as integer)) as float)) as km_per_hour,
sum(cast("Elevation Gain" as integer)) total_climbing,
runner
from dremioblogpost.F_ACTIVITY
where "Avg Moving Paces" != '--'
and "Elevation Gain" != '--'
group by runner
) nested_0
) nested_0
INNER JOIN dremioblogpost.D_USER AS join_D_USER ON nested_0.runner = join_D_USER.runner
Conclusions
Dremio is an interesting tool capable of unifying existing repositories of unstructured data. Is Dremio capable of working with any volume of data and complex relationships? Well, I believe that right now the tool isn't capable of this, even with the simple and small data sets used in this example the performance was not great.
Dremio does successfully provide self service access to most platforms meaning that users don't have to move data around before being able to perform any analysis. This is probably the most exciting part of Dremio. It might well be in the paradigm of a "good enough" way to access data across multiple sources. This will allow data scientists to do analysis before the data is formally structured.